Gait Recognition Using Multi-Scale Partial Representation Transformation with Capsules
Alireza Sepas-Moghaddam,
Saeed Ghorbani,
Nikolaus F. Troje,
Ali Etemad
Auto-TLDR; Learning to Transfer Multi-scale Partial Gait Representations using Capsule Networks for Gait Recognition
Similar papers
Part-Based Collaborative Spatio-Temporal Feature Learning for Cloth-Changing Gait Recognition
Lingxiang Yao, Worapan Kusakunniran, Qiang Wu, Jian Zhang, Jingsong Xu

Auto-TLDR; Part-based Spatio-Temporal Feature Learning for Gait Recognition
Abstract Slides Poster Similar
Deep Gait Relative Attribute Using a Signed Quadratic Contrastive Loss
Yuta Hayashi, Shehata Allam, Yasushi Makihara, Daigo Muramatsu, Yasushi Yagi

Auto-TLDR; Signal-Contrastive Loss for Gait Attributes Estimation
Two-Level Attention-Based Fusion Learning for RGB-D Face Recognition
Hardik Uppal, Alireza Sepas-Moghaddam, Michael Greenspan, Ali Etemad

Auto-TLDR; Fused RGB-D Facial Recognition using Attention-Aware Feature Fusion
Abstract Slides Poster Similar
Pose-Robust Face Recognition by Deep Meta Capsule Network-Based Equivariant Embedding
Fangyu Wu, Jeremy Simon Smith, Wenjin Lu, Bailing Zhang

Auto-TLDR; Deep Meta Capsule Network-based Equivariant Embedding Model for Pose-Robust Face Recognition
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
The Application of Capsule Neural Network Based CNN for Speech Emotion Recognition

Auto-TLDR; CapCNN: A Capsule Neural Network for Speech Emotion Recognition
Abstract Slides Poster Similar
Attention-Driven Body Pose Encoding for Human Activity Recognition
Bappaditya Debnath, Swagat Kumar, Marry O'Brien, Ardhendu Behera

Auto-TLDR; Attention-based Body Pose Encoding for Human Activity Recognition
Abstract Slides Poster Similar
Quaternion Capsule Networks
Barış Özcan, Furkan Kınlı, Mustafa Furkan Kirac

Auto-TLDR; Quaternion Capsule Networks for Object Recognition
Abstract Slides Poster Similar
2D Deep Video Capsule Network with Temporal Shift for Action Recognition
Théo Voillemin, Hazem Wannous, Jean-Philippe Vandeborre

Auto-TLDR; Temporal Shift Module over Capsule Network for Action Recognition in Continuous Videos
Vision-Based Multi-Modal Framework for Action Recognition
Djamila Romaissa Beddiar, Mourad Oussalah, Brahim Nini

Auto-TLDR; Multi-modal Framework for Human Activity Recognition Using RGB, Depth and Skeleton Data
Abstract Slides Poster Similar
Fixed Simplex Coordinates for Angular Margin Loss in CapsNet
Rita Pucci, Christian Micheloni, Gian Luca Foresti, Niki Martinel

Auto-TLDR; angular margin loss for capsule networks
Abstract Slides Poster Similar
Gender Classification Using Video Sequences of Body Sway Recorded by Overhead Camera
Takuya Kamitani, Yuta Yamaguchi, Shintaro Nakatani, Masashi Nishiyama, Yoshio Iwai

Auto-TLDR; Spatio-Temporal Feature for Gender Classification of a Standing Person Using Body Stance Using Time-Series Signals
Abstract Slides Poster Similar
Video Summarization with a Dual Attention Capsule Network
Hao Fu, Hongxing Wang, Jianyu Yang

Auto-TLDR; Dual Self-Attention Capsule Network for Video Summarization
Abstract Slides Poster Similar
JT-MGCN: Joint-Temporal Motion Graph Convolutional Network for Skeleton-Based Action Recognition

Auto-TLDR; Joint-temporal Motion Graph Convolutional Networks for Action Recognition
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Context Matters: Self-Attention for Sign Language Recognition
Fares Ben Slimane, Mohamed Bouguessa

Auto-TLDR; Attentional Network for Continuous Sign Language Recognition
Abstract Slides Poster Similar
Unsupervised Disentangling of Viewpoint and Residues Variations by Substituting Representations for Robust Face Recognition
Minsu Kim, Joanna Hong, Junho Kim, Hong Joo Lee, Yong Man Ro

Auto-TLDR; Unsupervised Disentangling of Identity, viewpoint, and Residue Representations for Robust Face Recognition
Abstract Slides Poster Similar
Lightweight Low-Resolution Face Recognition for Surveillance Applications
Yoanna Martínez-Díaz, Heydi Mendez-Vazquez, Luis S. Luevano, Leonardo Chang, Miguel Gonzalez-Mendoza

Auto-TLDR; Efficiency of Lightweight Deep Face Networks on Low-Resolution Surveillance Imagery
Abstract Slides Poster Similar
Video Analytics Gait Trend Measurement for Fall Prevention and Health Monitoring
Lawrence O'Gorman, Xinyi Liu, Md Imran Sarker, Mariofanna Milanova

Auto-TLDR; Towards Health Monitoring of Gait with Deep Learning
Abstract Slides Poster Similar
Variational Capsule Encoder
Harish Raviprakash, Syed Anwar, Ulas Bagci

Auto-TLDR; Bayesian Capsule Networks for Representation Learning in latent space
Abstract Slides Poster Similar
Vertex Feature Encoding and Hierarchical Temporal Modeling in a Spatio-Temporal Graph Convolutional Network for Action Recognition
Konstantinos Papadopoulos, Enjie Ghorbel, Djamila Aouada, Bjorn Ottersten

Auto-TLDR; Spatio-Temporal Graph Convolutional Network for Skeleton-Based Action Recognition
Abstract Slides Poster Similar
Not 3D Re-ID: Simple Single Stream 2D Convolution for Robust Video Re-Identification

Auto-TLDR; ResNet50-IBN for Video-based Person Re-Identification using Single Stream 2D Convolution Network
Abstract Slides Poster Similar
End-To-End Triplet Loss Based Emotion Embedding System for Speech Emotion Recognition
Puneet Kumar, Sidharth Jain, Balasubramanian Raman, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; End-to-End Neural Embedding System for Speech Emotion Recognition
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Attentive Part-Aware Networks for Partial Person Re-Identification
Lijuan Huo, Chunfeng Song, Zhengyi Liu, Zhaoxiang Zhang

Auto-TLDR; Part-Aware Learning for Partial Person Re-identification
Abstract Slides Poster Similar
SL-DML: Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Raphael Memmesheimer, Nick Theisen, Dietrich Paulus

Auto-TLDR; One-Shot Action Recognition using Metric Learning
Self and Channel Attention Network for Person Re-Identification
Asad Munir, Niki Martinel, Christian Micheloni

Auto-TLDR; SCAN: Self and Channel Attention Network for Person Re-identification
Abstract Slides Poster Similar
SAT-Net: Self-Attention and Temporal Fusion for Facial Action Unit Detection
Zhihua Li, Zheng Zhang, Lijun Yin

Auto-TLDR; Temporal Fusion and Self-Attention Network for Facial Action Unit Detection
Abstract Slides Poster Similar
A Two-Stream Recurrent Network for Skeleton-Based Human Interaction Recognition
Qianhui Men, Edmond S. L. Ho, Shum Hubert P. H., Howard Leung

Auto-TLDR; Two-Stream Recurrent Neural Network for Human-Human Interaction Recognition
Abstract Slides Poster Similar
Channel-Wise Dense Connection Graph Convolutional Network for Skeleton-Based Action Recognition
Michael Lao Banteng, Zhiyong Wu

Auto-TLDR; Two-stream channel-wise dense connection GCN for human action recognition
Abstract Slides Poster Similar
Top-DB-Net: Top DropBlock for Activation Enhancement in Person Re-Identification

Auto-TLDR; Top-DB-Net for Person Re-Identification using Top DropBlock
Abstract Slides Poster Similar
Deep Multi-Task Learning for Facial Expression Recognition and Synthesis Based on Selective Feature Sharing
Rui Zhao, Tianshan Liu, Jun Xiao, P. K. Daniel Lun, Kin-Man Lam

Auto-TLDR; Multi-task Learning for Facial Expression Recognition and Synthesis
Abstract Slides Poster Similar
FatNet: A Feature-Attentive Network for 3D Point Cloud Processing
Chaitanya Kaul, Nick Pears, Suresh Manandhar

Auto-TLDR; Feature-Attentive Neural Networks for Point Cloud Classification and Segmentation
Video-Based Facial Expression Recognition Using Graph Convolutional Networks
Daizong Liu, Hongting Zhang, Pan Zhou

Auto-TLDR; Graph Convolutional Network for Video-based Facial Expression Recognition
Abstract Slides Poster Similar
Convolutional Feature Transfer via Camera-Specific Discriminative Pooling for Person Re-Identification
Tetsu Matsukawa, Einoshin Suzuki

Auto-TLDR; A small-scale CNN feature transfer method for person re-identification
Abstract Slides Poster Similar
Temporal Attention-Augmented Graph Convolutional Network for Efficient Skeleton-Based Human Action Recognition
Negar Heidari, Alexandros Iosifidis

Auto-TLDR; Temporal Attention Module for Efficient Graph Convolutional Network-based Action Recognition
Abstract Slides Poster Similar
Single View Learning in Action Recognition
Gaurvi Goyal, Nicoletta Noceti, Francesca Odone

Auto-TLDR; Cross-View Action Recognition Using Domain Adaptation for Knowledge Transfer
Abstract Slides Poster Similar
Audio-Visual Speech Recognition Using a Two-Step Feature Fusion Strategy

Auto-TLDR; A Two-Step Feature Fusion Network for Speech Recognition
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Adaptive L2 Regularization in Person Re-Identification
Xingyang Ni, Liang Fang, Heikki Juhani Huttunen

Auto-TLDR; AdaptiveReID: Adaptive L2 Regularization for Person Re-identification
Abstract Slides Poster Similar
SDMA: Saliency Driven Mutual Cross Attention for Multi-Variate Time Series

Auto-TLDR; Salient-Driven Mutual Cross Attention for Intelligent Time Series Analytics
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
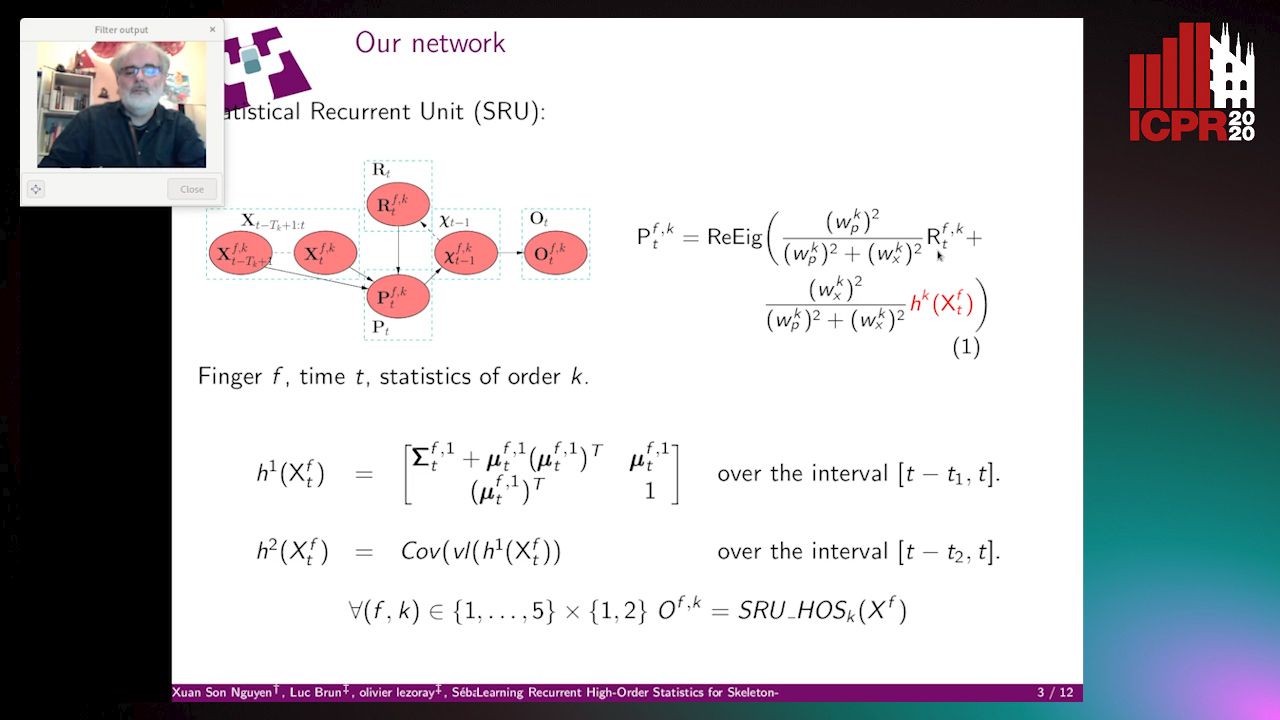
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Age Gap Reducer-GAN for Recognizing Age-Separated Faces
Daksha Yadav, Naman Kohli, Mayank Vatsa, Richa Singh, Afzel Noore

Auto-TLDR; Generative Adversarial Network for Age-separated Face Recognition
Abstract Slides Poster Similar
Multi-Scale Cascading Network with Compact Feature Learning for RGB-Infrared Person Re-Identification
Can Zhang, Hong Liu, Wei Guo, Mang Ye

Auto-TLDR; Multi-Scale Part-Aware Cascading for RGB-Infrared Person Re-identification
Abstract Slides Poster Similar
Recurrent Deep Attention Network for Person Re-Identification
Changhao Wang, Jun Zhou, Xianfei Duan, Guanwen Zhang, Wei Zhou

Auto-TLDR; Recurrent Deep Attention Network for Person Re-identification
Abstract Slides Poster Similar
Relevance Detection in Cataract Surgery Videos by Spatio-Temporal Action Localization
Negin Ghamsarian, Mario Taschwer, Doris Putzgruber, Stephanie. Sarny, Klaus Schoeffmann

Auto-TLDR; relevance-based retrieval in cataract surgery videos
LODENet: A Holistic Approach to Offline Handwritten Chinese and Japanese Text Line Recognition
Huu Tin Hoang, Chun-Jen Peng, Hung Tran, Hung Le, Huy Hoang Nguyen

Auto-TLDR; Logographic DEComposition Encoding for Chinese and Japanese Text Line Recognition
Abstract Slides Poster Similar