Face Anti-Spoofing Based on Dynamic Color Texture Analysis Using Local Directional Number Pattern
Junwei Zhou,
Ke Shu,
Peng Liu,
Jianwen Xiang,
Shengwu Xiong

Auto-TLDR; LDN-TOP Representation followed by ProCRC Classification for Face Anti-Spoofing
Similar papers
Face Anti-Spoofing Using Spatial Pyramid Pooling
Lei Shi, Zhuo Zhou, Zhenhua Guo

Auto-TLDR; Spatial Pyramid Pooling for Face Anti-Spoofing
Abstract Slides Poster Similar
Disentangled Representation Based Face Anti-Spoofing
Zhao Liu, Zunlei Feng, Yong Li, Zeyu Zou, Rong Zhang, Mingli Song, Jianping Shen

Auto-TLDR; Face Anti-Spoofing using Motion Information and Disentangled Frame Work
Abstract Slides Poster Similar
MixNet for Generalized Face Presentation Attack Detection
Nilay Sanghvi, Sushant Singh, Akshay Agarwal, Mayank Vatsa, Richa Singh

Auto-TLDR; MixNet: A Deep Learning-based Network for Detection of Presentation Attacks in Cross-Database and Unseen Setting
Abstract Slides Poster Similar
A Cross Domain Multi-Modal Dataset for Robust Face Anti-Spoofing
Qiaobin Ji, Shugong Xu, Xudong Chen, Shan Cao, Shunqing Zhang

Auto-TLDR; Cross domain multi-modal FAS dataset GREAT-FASD and several evaluation protocols for academic community
Abstract Slides Poster Similar
Detection of Makeup Presentation Attacks Based on Deep Face Representations
Christian Rathgeb, Pawel Drozdowski, Christoph Busch

Auto-TLDR; An Attack Detection Scheme for Face Recognition Using Makeup Presentation Attacks
Abstract Slides Poster Similar
Dynamically Mitigating Data Discrepancy with Balanced Focal Loss for Replay Attack Detection
Yongqiang Dou, Haocheng Yang, Maolin Yang, Yanyan Xu, Dengfeng Ke

Auto-TLDR; Anti-Spoofing with Balanced Focal Loss Function and Combination Features
Abstract Slides Poster Similar
ResMax: Detecting Voice Spoofing Attacks with Residual Network and Max Feature Map
Il-Youp Kwak, Sungsu Kwag, Junhee Lee, Jun Ho Huh, Choong-Hoon Lee, Youngbae Jeon, Jeonghwan Hwang, Ji Won Yoon

Auto-TLDR; ASVspoof 2019: A Lightweight Automatic Speaker Verification Spoofing and Countermeasures System
Abstract Slides Poster Similar
Generalized Iris Presentation Attack Detection Algorithm under Cross-Database Settings
Mehak Gupta, Vishal Singh, Akshay Agarwal, Mayank Vatsa, Richa Singh

Auto-TLDR; MVNet: A Deep Learning-based PAD Network for Iris Recognition against Presentation Attacks
Abstract Slides Poster Similar
Are Spoofs from Latent Fingerprints a Real Threat for the Best State-Of-Art Liveness Detectors?
Roberto Casula, Giulia Orrù, Daniele Angioni, Xiaoyi Feng, Gian Luca Marcialis, Fabio Roli

Auto-TLDR; ScreenSpoof: Attacks using latent fingerprints against state-of-art fingerprint liveness detectors and verification systems
Depth Videos for the Classification of Micro-Expressions
Ankith Jain Rakesh Kumar, Bir Bhanu, Christopher Casey, Sierra Cheung, Aaron Seitz

Auto-TLDR; RGB-D Dataset for the Classification of Facial Micro-expressions
Abstract Slides Poster Similar
Joint Learning Multiple Curvature Descriptor for 3D Palmprint Recognition
Lunke Fei, Bob Zhang, Jie Wen, Chunwei Tian, Peng Liu, Shuping Zhao

Auto-TLDR; Joint Feature Learning for 3D palmprint recognition using curvature data vectors
Abstract Slides Poster Similar
Magnifying Spontaneous Facial Micro Expressions for Improved Recognition
Pratikshya Sharma, Sonya Coleman, Pratheepan Yogarajah, Laurence Taggart, Pradeepa Samarasinghe

Auto-TLDR; Eulerian Video Magnification for Micro Expression Recognition
Abstract Slides Poster Similar
Color Texture Description Based on Holistic and Hierarchical Order-Encoding Patterns
Tiecheng Song, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; Holistic and Hierarchical Order-Encoding Patterns for Color Texture Classification
Abstract Slides Poster Similar
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
Exposing Deepfake Videos by Tracking Eye Movements
Meng Li, Beibei Liu, Yujiang Hu, Yufei Wang

Auto-TLDR; A Novel Approach to Detecting Deepfake Videos
Abstract Slides Poster Similar
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
Local Grouped Invariant Order Pattern for Grayscale-Inversion and Rotation Invariant Texture Classification
Yankai Huang, Tiecheng Song, Shuang Li, Yuanjing Han

Auto-TLDR; Local grouped invariant order pattern for grayscale-inversion and rotation invariant texture classification
Abstract Slides Poster Similar
Local Attention and Global Representation Collaborating for Fine-Grained Classification
He Zhang, Yunming Bai, Hui Zhang, Jing Liu, Xingguang Li, Zhaofeng He

Auto-TLDR; Weighted Region Network for Cosmetic Contact Lenses Detection
Abstract Slides Poster Similar
Viability of Optical Coherence Tomography for Iris Presentation Attack Detection

Auto-TLDR; Optical Coherence Tomography Imaging for Iris Presentation Attack Detection
Abstract Slides Poster Similar
Age Gap Reducer-GAN for Recognizing Age-Separated Faces
Daksha Yadav, Naman Kohli, Mayank Vatsa, Richa Singh, Afzel Noore

Auto-TLDR; Generative Adversarial Network for Age-separated Face Recognition
Abstract Slides Poster Similar
Two-Level Attention-Based Fusion Learning for RGB-D Face Recognition
Hardik Uppal, Alireza Sepas-Moghaddam, Michael Greenspan, Ali Etemad

Auto-TLDR; Fused RGB-D Facial Recognition using Attention-Aware Feature Fusion
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
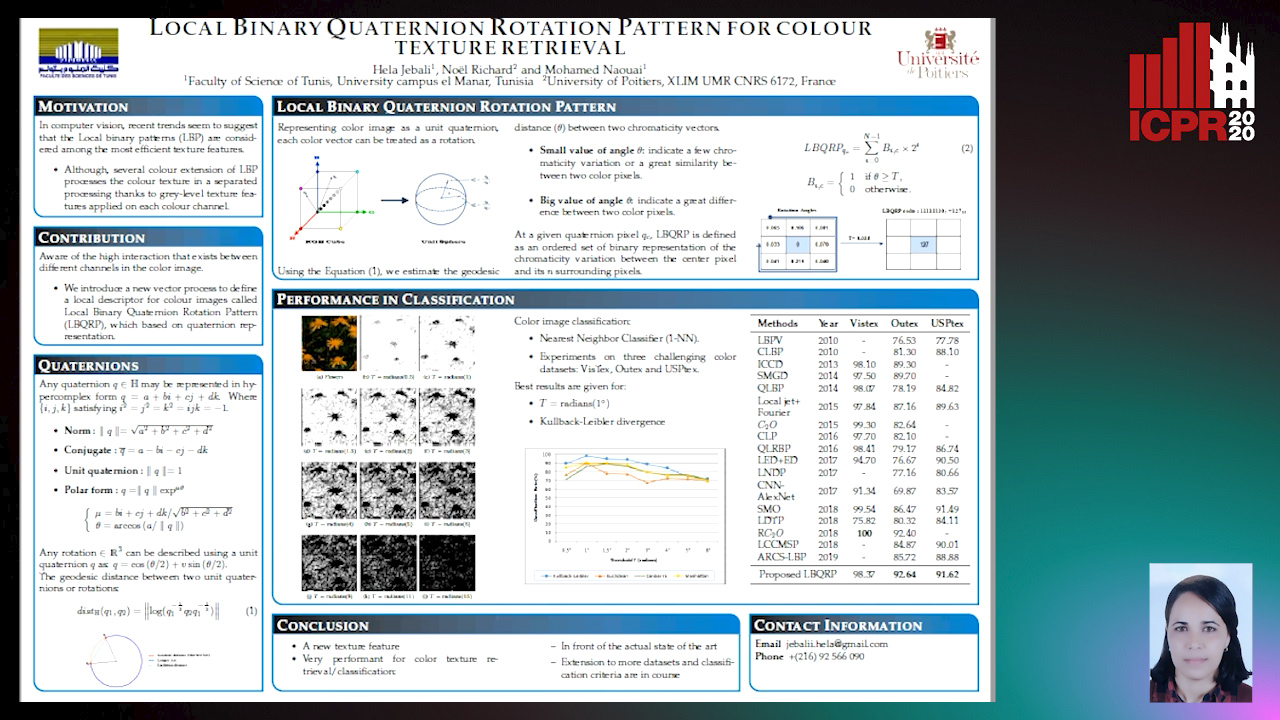
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
First and Second-Order Sorted Local Binary Pattern Features for Grayscale-Inversion and Rotation Invariant Texture Classification
Tiecheng Song, Yuanjing Han, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; First- and Secondorder Sorted Local Binary Pattern for texture classification under inverse grayscale changes and image rotation
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Lightweight Low-Resolution Face Recognition for Surveillance Applications
Yoanna Martínez-Díaz, Heydi Mendez-Vazquez, Luis S. Luevano, Leonardo Chang, Miguel Gonzalez-Mendoza

Auto-TLDR; Efficiency of Lightweight Deep Face Networks on Low-Resolution Surveillance Imagery
Abstract Slides Poster Similar
Quality-Based Representation for Unconstrained Face Recognition
Nelson Méndez-Llanes, Katy Castillo-Rosado, Heydi Mendez-Vazquez, Massimo Tistarelli

Auto-TLDR; activation map for face recognition in unconstrained environments
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
A Local Descriptor with Physiological Characteristic for Finger Vein Recognition
Liping Zhang, Weijun Li, Ning Xin

Auto-TLDR; Finger vein-specific local feature descriptors based physiological characteristic of finger vein patterns
Abstract Slides Poster Similar
A Flatter Loss for Bias Mitigation in Cross-Dataset Facial Age Estimation
Ali Akbari, Muhammad Awais, Zhenhua Feng, Ammarah Farooq, Josef Kittler

Auto-TLDR; Cross-dataset Age Estimation for Neural Network Training
Abstract Slides Poster Similar
Deep Multi-Task Learning for Facial Expression Recognition and Synthesis Based on Selective Feature Sharing
Rui Zhao, Tianshan Liu, Jun Xiao, P. K. Daniel Lun, Kin-Man Lam

Auto-TLDR; Multi-task Learning for Facial Expression Recognition and Synthesis
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
Joint Compressive Autoencoders for Full-Image-To-Image Hiding
Xiyao Liu, Ziping Ma, Xingbei Guo, Jialu Hou, Lei Wang, Gerald Schaefer, Hui Fang

Auto-TLDR; J-CAE: Joint Compressive Autoencoder for Image Hiding
Abstract Slides Poster Similar
Identity-Aware Facial Expression Recognition in Compressed Video
Xiaofeng Liu, Linghao Jin, Xu Han, Jun Lu, Jonghye Woo, Jane You

Auto-TLDR; Exploring Facial Expression Representation in Compressed Video with Mutual Information Minimization
Responsive Social Smile: A Machine-Learning Based Multimodal Behavior Assessment Framework towards Early Stage Autism Screening
Yueran Pan, Kunjing Cai, Ming Cheng, Xiaobing Zou, Ming Li

Auto-TLDR; Responsive Social Smile: A Machine Learningbased Assessment Framework for Early ASD Screening
Learning Metric Features for Writer-Independent Signature Verification Using Dual Triplet Loss
Auto-TLDR; A dual triplet loss based method for offline writer-independent signature verification
A Distinct Discriminant Canonical Correlation Analysis Network Based Deep Information Quality Representation for Image Classification
Lei Gao, Zheng Guo, Ling Guan Ling Guan

Auto-TLDR; DDCCANet: Deep Information Quality Representation for Image Classification
Abstract Slides Poster Similar
A Quantitative Evaluation Framework of Video De-Identification Methods
Sathya Bursic, Alessandro D'Amelio, Marco Granato, Giuliano Grossi, Raffaella Lanzarotti

Auto-TLDR; Face de-identification using photo-reality and facial expressions
Abstract Slides Poster Similar
Exploring Seismocardiogram Biometrics with Wavelet Transform
Po-Ya Hsu, Po-Han Hsu, Hsin-Li Liu

Auto-TLDR; Seismocardiogram Biometric Matching Using Wavelet Transform and Deep Learning Models
Abstract Slides Poster Similar
Two-Stream Temporal Convolutional Network for Dynamic Facial Attractiveness Prediction
Nina Weng, Jiahao Wang, Annan Li, Yunhong Wang

Auto-TLDR; 2S-TCN: A Two-Stream Temporal Convolutional Network for Dynamic Facial Attractiveness Prediction
Abstract Slides Poster Similar
Pose-Robust Face Recognition by Deep Meta Capsule Network-Based Equivariant Embedding
Fangyu Wu, Jeremy Simon Smith, Wenjin Lu, Bailing Zhang

Auto-TLDR; Deep Meta Capsule Network-based Equivariant Embedding Model for Pose-Robust Face Recognition
Attribute-Based Quality Assessment for Demographic Estimation in Face Videos
Fabiola Becerra-Riera, Annette Morales-González, Heydi Mendez-Vazquez, Jean-Luc Dugelay

Auto-TLDR; Facial Demographic Estimation in Video Scenarios Using Quality Assessment
ClusterFace: Joint Clustering and Classification for Set-Based Face Recognition
Samadhi Poornima Kumarasinghe Wickrama Arachchilage, Ebroul Izquierdo

Auto-TLDR; Joint Clustering and Classification for Face Recognition in the Wild
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
RobusterNet: Improving Copy-Move Forgery Detection with Volterra-Based Convolutions
Efthimia Kafali, Nicholas Vretos, Theodoros Semertzidis, Petros Daras
Auto-TLDR; Convolutional Neural Networks with Nonlinear Inception for Copy-Move Forgery Detection
Finger Vein Recognition and Intra-Subject Similarity Evaluation of Finger Veins Using the CNN Triplet Loss
Georg Wimmer, Bernhard Prommegger, Andreas Uhl

Auto-TLDR; Finger vein recognition using CNNs and hard triplet online selection
Abstract Slides Poster Similar
A Weak Coupling of Semi-Supervised Learning with Generative Adversarial Networks for Malware Classification
Shuwei Wang, Qiuyun Wang, Zhengwei Jiang, Xuren Wang, Rongqi Jing

Auto-TLDR; IMIR: An Improved Malware Image Rescaling Algorithm Using Semi-supervised Generative Adversarial Network
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar