A Bayesian Deep CNN Framework for Reconstructing K-T-Undersampled Resting-fMRI
Karan Taneja,
Prachi Kulkarni,
Shabbir Merchant,
Suyash Awate

Auto-TLDR; K-t undersampled R-fMRI Reconstruction using Deep Convolutional Neural Networks
Similar papers
Quantifying Model Uncertainty in Inverse Problems Via Bayesian Deep Gradient Descent
Riccardo Barbano, Chen Zhang, Simon Arridge, Bangti Jin

Auto-TLDR; Bayesian Neural Networks for Inverse Reconstruction via Bayesian Knowledge-Aided Computation
Abstract Slides Poster Similar
A Riemannian Framework for Detecting Stimulus-Relevant Fiber Pathways
Jingyong Su, Linlin Tang, Zhipeng Yang, Mengmeng Guo

Auto-TLDR; Clustering Task-Specific Fiber Pathways in Functional MRI using BOLD Signals
Learning Image Inpainting from Incomplete Images using Self-Supervision
Sriram Yenamandra, Rohit Kumar Jena, Ansh Khurana, Suyash Awate

Auto-TLDR; Unsupervised Deep Neural Network for Semantic Image Inpainting
Abstract Slides Poster Similar
Generative Deep-Neural-Network Mixture Modeling with Semi-Supervised MinMax+EM Learning

Auto-TLDR; Semi-supervised Deep Neural Networks for Generative Mixture Modeling and Clustering
Abstract Slides Poster Similar
Estimating Static and Dynamic Brain Networks by Kulback-Leibler Divergence from fMRI Data
Gonul Degirmendereli, Fatos Yarman Vural

Auto-TLDR; A Novel method to estimate static and dynamic brain networks using Kulback- Leibler divergence using fMRI data
Phase Retrieval Using Conditional Generative Adversarial Networks
Tobias Uelwer, Alexander Oberstraß, Stefan Harmeling

Auto-TLDR; Conditional Generative Adversarial Networks for Phase Retrieval
Abstract Slides Poster Similar
Improving Gravitational Wave Detection with 2D Convolutional Neural Networks
Siyu Fan, Yisen Wang, Yuan Luo, Alexander Michael Schmitt, Shenghua Yu

Auto-TLDR; Two-dimensional Convolutional Neural Networks for Gravitational Wave Detection from Time Series with Background Noise
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Encoding Brain Networks through Geodesic Clustering of Functional Connectivity for Multiple Sclerosis Classification
Muhammad Abubakar Yamin, Valsasina Paola, Michael Dayan, Sebastiano Vascon, Tessadori Jacopo, Filippi Massimo, Vittorio Murino, A Rocca Maria, Diego Sona

Auto-TLDR; Geodesic Clustering of Connectivity Matrices for Multiple Sclerosis Classification
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Neural Machine Registration for Motion Correction in Breast DCE-MRI
Federica Aprea, Stefano Marrone, Carlo Sansone

Auto-TLDR; A Neural Registration Network for Dynamic Contrast Enhanced-Magnetic Resonance Imaging
Abstract Slides Poster Similar
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Martin Kolarik, Radim Burget, Carlos M. Travieso-Gonzalez, Jan Kocica

Auto-TLDR; Planar 3D Res-U-Net Network for Unbalanced 3D Image Segmentation using Fluid Attenuation Inversion Recover
MedZip: 3D Medical Images Lossless Compressor Using Recurrent Neural Network (LSTM)
Omniah Nagoor, Joss Whittle, Jingjing Deng, Benjamin Mora, Mark W. Jones

Auto-TLDR; Recurrent Neural Network for Lossless Medical Image Compression using Long Short-Term Memory
Classification of Spatially Enriched Pixel Time Series with Convolutional Neural Networks
Mohamed Chelali, Camille Kurtz, Anne Puissant, Nicole Vincent

Auto-TLDR; Spatio-Temporal Features Extraction from Satellite Image Time Series Using Random Walk
Abstract Slides Poster Similar
Improved anomaly detection by training an autoencoder with skip connections on images corrupted with Stain-shaped noise
Anne-Sophie Collin, Christophe De Vleeschouwer

Auto-TLDR; Autoencoder with Skip Connections for Anomaly Detection
Abstract Slides Poster Similar
Graph Convolutional Neural Networks for Power Line Outage Identification

Auto-TLDR; Graph Convolutional Networks for Power Line Outage Identification
Robust Skeletonization for Plant Root Structure Reconstruction from MRI

Auto-TLDR; Structural reconstruction of plant roots from MRI using semantic root vs shoot segmentation and 3D skeletonization
Abstract Slides Poster Similar
Temporal Pattern Detection in Time-Varying Graphical Models
Federico Tomasi, Veronica Tozzo, Annalisa Barla

Auto-TLDR; A dynamical network inference model that leverages on kernels to consider general temporal patterns
Abstract Slides Poster Similar
Tensor Factorization of Brain Structural Graph for Unsupervised Classification in Multiple Sclerosis
Berardino Barile, Marzullo Aldo, Claudio Stamile, Françoise Durand-Dubief, Dominique Sappey-Marinier

Auto-TLDR; A Fully Automated Tensor-based Algorithm for Multiple Sclerosis Classification based on Structural Connectivity Graph of the White Matter Network
Abstract Slides Poster Similar
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
EEG-Based Cognitive State Assessment Using Deep Ensemble Model and Filter Bank Common Spatial Pattern
Debashis Das Chakladar, Shubhashis Dey, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; A Deep Ensemble Model for Cognitive State Assessment using EEG-based Cognitive State Analysis
Abstract Slides Poster Similar
Digit Recognition Applied to Reconstructed Audio Signals Using Deep Learning
Anastasia-Sotiria Toufa, Constantine Kotropoulos

Auto-TLDR; Compressed Sensing for Digit Recognition in Audio Reconstruction
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Anupama S, Prasan Shedligeri, Abhishek Pal, Kaushik Mitr

Auto-TLDR; Recovering Video from Motion-Blurred and Coded Exposure Images Using Deep Learning
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Deep Residual Attention Network for Hyperspectral Image Reconstruction

Auto-TLDR; Deep Convolutional Neural Network for Hyperspectral Image Reconstruction from a Snapshot
Abstract Slides Poster Similar
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Ultrasound Image Restoration Using Weighted Nuclear Norm Minimization
Hanmei Yang, Ye Luo, Jianwei Lu, Jian Lu

Auto-TLDR; A Nonconvex Low-Rank Matrix Approximation Model for Ultrasound Images Restoration
Variational Capsule Encoder
Harish Raviprakash, Syed Anwar, Ulas Bagci

Auto-TLDR; Bayesian Capsule Networks for Representation Learning in latent space
Abstract Slides Poster Similar
Weakly Supervised Geodesic Segmentation of Egyptian Mummy CT Scans
Avik Hati, Matteo Bustreo, Diego Sona, Vittorio Murino, Alessio Del Bue

Auto-TLDR; A Weakly Supervised and Efficient Interactive Segmentation of Ancient Egyptian Mummies CT Scans Using Geodesic Distance Measure and GrabCut
Abstract Slides Poster Similar
End-To-End Multi-Task Learning of Missing Value Imputation and Forecasting in Time-Series Data
Jinhee Kim, Taesung Kim, Jang-Ho Choi, Jaegul Choo

Auto-TLDR; Time-Series Prediction with Denoising and Imputation of Missing Data
Abstract Slides Poster Similar
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux, Riadh Fezzani, Jean-Christophe Olivo-Marin
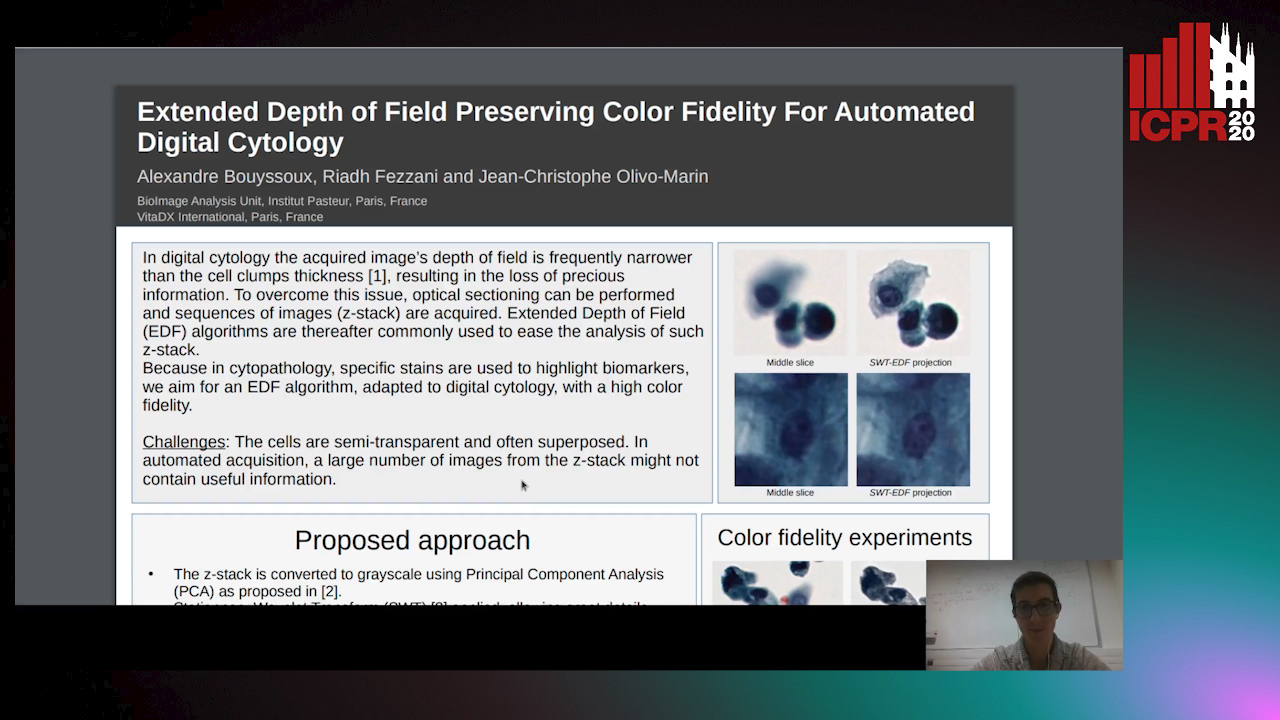
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform
DSPNet: Deep Learning-Enabled Blind Reduction of Speckle Noise
Yuxu Lu, Meifang Yang, Liu Wen

Auto-TLDR; Deep Blind DeSPeckling Network for Imaging Applications
JUMPS: Joints Upsampling Method for Pose Sequences
Lucas Mourot, Francois Le Clerc, Cédric Thébault, Pierre Hellier

Auto-TLDR; JUMPS: Increasing the Number of Joints in 2D Pose Estimation and Recovering Occluded or Missing Joints
Abstract Slides Poster Similar
Segmentation of Axillary and Supraclavicular Tumoral Lymph Nodes in PET/CT: A Hybrid CNN/Component-Tree Approach
Diana Lucia Farfan Cabrera, Nicolas Gogin, David Morland, Benoît Naegel, Dimitri Papathanassiou, Nicolas Passat

Auto-TLDR; Coupling Convolutional Neural Networks and Component-Trees for Lymph node Segmentation from PET/CT Images
Galaxy Image Translation with Semi-Supervised Noise-Reconstructed Generative Adversarial Networks
Qiufan Lin, Dominique Fouchez, Jérôme Pasquet

Auto-TLDR; Semi-supervised Image Translation with Generative Adversarial Networks Using Paired and Unpaired Images
Abstract Slides Poster Similar
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Deep Multi-Stage Model for Automated Landmarking of Craniomaxillofacial CT Scans
Simone Palazzo, Giovanni Bellitto, Luca Prezzavento, Francesco Rundo, Ulas Bagci, Daniela Giordano, Rosalia Leonardi, Concetto Spampinato

Auto-TLDR; Automated Landmarking of Craniomaxillofacial CT Images Using Deep Multi-Stage Architecture
FMRI Brain Networks As Statistical Mechanical Ensembles
Jianjia Wang, Hui Wu, Edwin Hancock

Auto-TLDR; Microcanonical Ensemble Methods for FMRI Brain Networks for Alzheimer's Disease
Abstract Slides Poster Similar
Modulation Pattern Detection Using Complex Convolutions in Deep Learning
Jakob Krzyston, Rajib Bhattacharjea, Andrew Stark

Auto-TLDR; Complex Convolutional Neural Networks for Modulation Pattern Classification
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
Leveraging Synthetic Subject Invariant EEG Signals for Zero Calibration BCI
Nik Khadijah Nik Aznan, Amir Atapour-Abarghouei, Stephen Bonner, Jason Connolly, Toby Breckon

Auto-TLDR; SIS-GAN: Subject Invariant SSVEP Generative Adversarial Network for Brain-Computer Interface
Radar Image Reconstruction from Raw ADC Data Using Parametric Variational Autoencoder with Domain Adaptation
Michael Stephan, Thomas Stadelmayer, Avik Santra, Georg Fischer, Robert Weigel, Fabian Lurz

Auto-TLDR; Parametric Variational Autoencoder-based Human Target Detection and Localization for Frequency Modulated Continuous Wave Radar
Abstract Slides Poster Similar