MedZip: 3D Medical Images Lossless Compressor Using Recurrent Neural Network (LSTM)
Omniah Nagoor,
Joss Whittle,
Jingjing Deng,
Benjamin Mora,
Mark W. Jones

Auto-TLDR; Recurrent Neural Network for Lossless Medical Image Compression using Long Short-Term Memory
Similar papers
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
A Transformer-Based Network for Anisotropic 3D Medical Image Segmentation
Guo Danfeng, Demetri Terzopoulos

Auto-TLDR; A transformer-based model to tackle the anisotropy problem in 3D medical image analysis
Abstract Slides Poster Similar
Compression Strategies and Space-Conscious Representations for Deep Neural Networks
Giosuè Marinò, Gregorio Ghidoli, Marco Frasca, Dario Malchiodi

Auto-TLDR; Compression of Large Convolutional Neural Networks by Weight Pruning and Quantization
Abstract Slides Poster Similar
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Martin Kolarik, Radim Burget, Carlos M. Travieso-Gonzalez, Jan Kocica

Auto-TLDR; Planar 3D Res-U-Net Network for Unbalanced 3D Image Segmentation using Fluid Attenuation Inversion Recover
Joint Compressive Autoencoders for Full-Image-To-Image Hiding
Xiyao Liu, Ziping Ma, Xingbei Guo, Jialu Hou, Lei Wang, Gerald Schaefer, Hui Fang

Auto-TLDR; J-CAE: Joint Compressive Autoencoder for Image Hiding
Abstract Slides Poster Similar
Deep Learning-Based Type Identification of Volumetric MRI Sequences
Jean Pablo De Mello, Thiago Paixão, Rodrigo Berriel, Mauricio Reyes, Alberto F. De Souza, Claudine Badue, Thiago Oliveira-Santos

Auto-TLDR; Deep Learning for Brain MRI Sequences Identification Using Convolutional Neural Network
Abstract Slides Poster Similar
3D Medical Multi-Modal Segmentation Network Guided by Multi-Source Correlation Constraint
Tongxue Zhou, Stéphane Canu, Pierre Vera, Su Ruan

Auto-TLDR; Multi-modality Segmentation with Correlation Constrained Network
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Deep Recurrent-Convolutional Model for AutomatedSegmentation of Craniomaxillofacial CT Scans
Francesca Murabito, Simone Palazzo, Federica Salanitri Proietto, Francesco Rundo, Ulas Bagci, Daniela Giordano, Rosalia Leonardi, Concetto Spampinato

Auto-TLDR; Automated Segmentation of Anatomical Structures in Craniomaxillofacial CT Scans using Fully Convolutional Deep Networks
Abstract Slides Poster Similar
Explorable Tone Mapping Operators
Su Chien-Chuan, Yu-Lun Liu, Hung Jin Lin, Ren Wang, Chia-Ping Chen, Yu-Lin Chang, Soo-Chang Pei

Auto-TLDR; Learning-based multimodal tone-mapping from HDR images
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux, Riadh Fezzani, Jean-Christophe Olivo-Marin
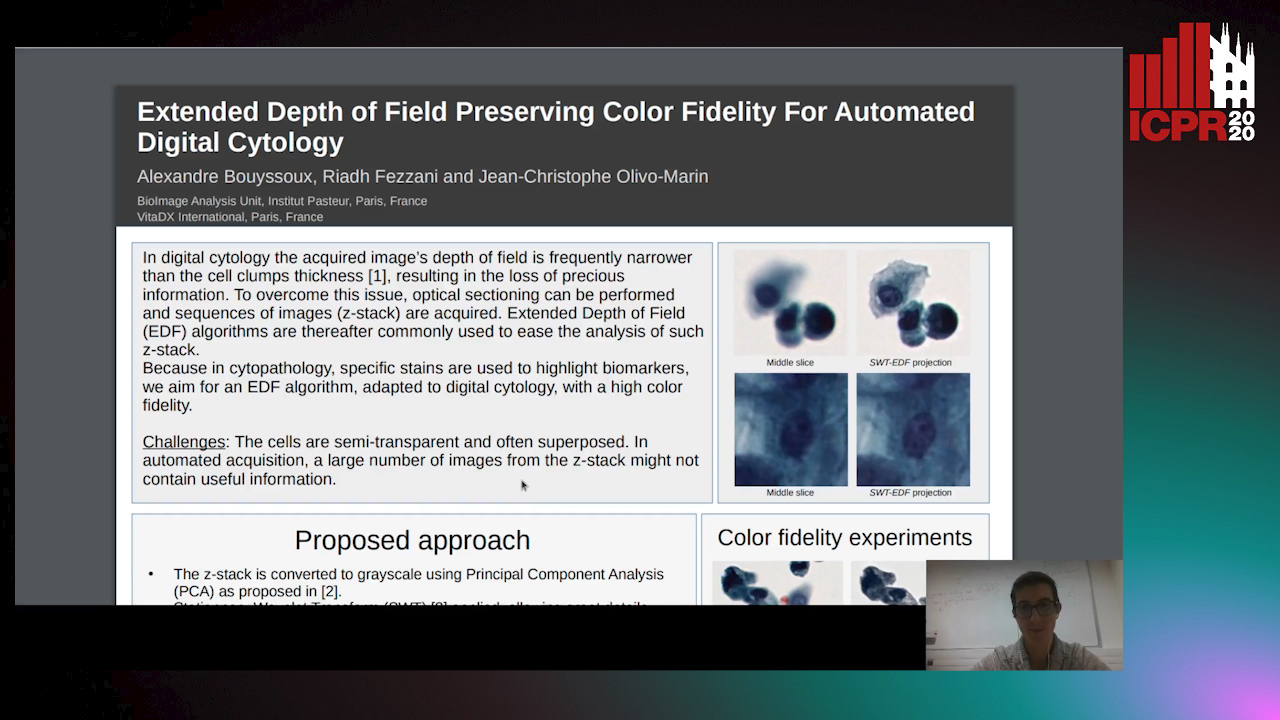
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform
Neural Machine Registration for Motion Correction in Breast DCE-MRI
Federica Aprea, Stefano Marrone, Carlo Sansone

Auto-TLDR; A Neural Registration Network for Dynamic Contrast Enhanced-Magnetic Resonance Imaging
Abstract Slides Poster Similar
Attack-Agnostic Adversarial Detection on Medical Data Using Explainable Machine Learning
Matthew Watson, Noura Al Moubayed

Auto-TLDR; Explainability-based Detection of Adversarial Samples on EHR and Chest X-Ray Data
Abstract Slides Poster Similar
A Heuristic-Based Decision Tree for Connected Components Labeling of 3D Volumes
Maximilian Söchting, Stefano Allegretti, Federico Bolelli, Costantino Grana

Auto-TLDR; Entropy Partitioning Decision Tree for Connected Components Labeling
Abstract Slides Poster Similar
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
CardioGAN: An Attention-Based Generative Adversarial Network for Generation of Electrocardiograms
Subhrajyoti Dasgupta, Sudip Das, Ujjwal Bhattacharya

Auto-TLDR; CardioGAN: Generative Adversarial Network for Synthetic Electrocardiogram Signals
Abstract Slides Poster Similar
On the Impact of Lossy Image and Video Compression on the Performance of Deep Convolutional Neural Network Architectures
Matt Poyser, Toby Breckon, Amir Atapour-Abarghouei

Auto-TLDR; The Impact of Lossy Image Compression on Deep Neural Networks for Image-based Detection and Classification
Transformer Networks for Trajectory Forecasting
Francesco Giuliari, Hasan Irtiza, Marco Cristani, Fabio Galasso

Auto-TLDR; TransformerNetworks for Trajectory Prediction of People Interactions
Abstract Slides Poster Similar
Mutual Information Based Method for Unsupervised Disentanglement of Video Representation
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; MIPAE: Mutual Information Predictive Auto-Encoder for Video Prediction
Abstract Slides Poster Similar
Reducing the Variance of Variational Estimates of Mutual Information by Limiting the Critic's Hypothesis Space to RKHS
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; Mutual Information Estimation from Variational Lower Bounds Using a Critic's Hypothesis Space
ESResNet: Environmental Sound Classification Based on Visual Domain Models
Andrey Guzhov, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Environmental Sound Classification with Short-Time Fourier Transform Spectrograms
Abstract Slides Poster Similar
EdgeNet: Semantic Scene Completion from a Single RGB-D Image
Aloisio Dourado, Teofilo De Campos, Adrian Hilton, Hansung Kim

Auto-TLDR; Semantic Scene Completion using 3D Depth and RGB Information
Abstract Slides Poster Similar
Computational Data Analysis for First Quantization Estimation on JPEG Double Compressed Images
Sebastiano Battiato, Oliver Giudice, Francesco Guarnera, Giovanni Puglisi

Auto-TLDR; Exploiting Discrete Cosine Transform Coefficients for Multimedia Forensics
Abstract Slides Poster Similar
Multi-Scanning Based Recurrent Neural Network for Hyperspectral Image Classification
Weilian Zhou, Sei-Ichiro Kamata

Auto-TLDR; Spatial-Spectral Unification for Hyperspectral Image Classification
Abstract Slides Poster Similar
Constructing Geographic and Long-term Temporal Graph for Traffic Forecasting
Yiwen Sun, Yulu Wang, Kun Fu, Zheng Wang, Changshui Zhang, Jieping Ye

Auto-TLDR; GLT-GCRNN: Geographic and Long-term Temporal Graph Convolutional Recurrent Neural Network for Traffic Forecasting
Abstract Slides Poster Similar
Transfer Learning with Graph Neural Networks for Short-Term Highway Traffic Forecasting
Tanwi Mallick, Prasanna Balaprakash, Eric Rask, Jane Macfarlane

Auto-TLDR; Transfer Learning for Highway Traffic Forecasting on Unseen Traffic Networks
Abstract Slides Poster Similar
RNN Training along Locally Optimal Trajectories via Frank-Wolfe Algorithm
Yun Yue, Ming Li, Venkatesh Saligrama, Ziming Zhang

Auto-TLDR; Frank-Wolfe Algorithm for Efficient Training of RNNs
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
BCAU-Net: A Novel Architecture with Binary Channel Attention Module for MRI Brain Segmentation
Yongpei Zhu, Zicong Zhou, Guojun Liao, Kehong Yuan

Auto-TLDR; BCAU-Net: Binary Channel Attention U-Net for MRI brain segmentation
Abstract Slides Poster Similar
On Resource-Efficient Bayesian Network Classifiers and Deep Neural Networks
Wolfgang Roth, Günther Schindler, Holger Fröning, Franz Pernkopf

Auto-TLDR; Quantization-Aware Bayesian Network Classifiers for Small-Scale Scenarios
Abstract Slides Poster Similar
Quantifying Model Uncertainty in Inverse Problems Via Bayesian Deep Gradient Descent
Riccardo Barbano, Chen Zhang, Simon Arridge, Bangti Jin

Auto-TLDR; Bayesian Neural Networks for Inverse Reconstruction via Bayesian Knowledge-Aided Computation
Abstract Slides Poster Similar
Context Matters: Self-Attention for Sign Language Recognition
Fares Ben Slimane, Mohamed Bouguessa

Auto-TLDR; Attentional Network for Continuous Sign Language Recognition
Abstract Slides Poster Similar
Robust Image Coding on Synthetic DNA: Reducing Sequencing Noise with Inpainting
Eva Gil San Antonio, Mattia Piretti, Melpomeni Dimopoulou, Marc Antonini

Auto-TLDR; Noise Resilience for DNA Storage
Abstract Slides Poster Similar
Trajectory-User Link with Attention Recurrent Networks
Tao Sun, Yongjun Xu, Fei Wang, Lin Wu, 塘文 钱, Zezhi Shao

Auto-TLDR; TULAR: Trajectory-User Link with Attention Recurrent Neural Networks
Abstract Slides Poster Similar
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Renlong Jie, Junbin Gao, Andrey Vasnev, Minh-Ngoc Tran

Auto-TLDR; Flexible Activation in Deep Neural Networks using ReLU and ELUs
Abstract Slides Poster Similar
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar
HP2IFS: Head Pose Estimation Exploiting Partitioned Iterated Function Systems
Carmen Bisogni, Michele Nappi, Chiara Pero, Stefano Ricciardi

Auto-TLDR; PIFS based head pose estimation using fractal coding theory and Partitioned Iterated Function Systems
Abstract Slides Poster Similar
Deep Multi-Stage Model for Automated Landmarking of Craniomaxillofacial CT Scans
Simone Palazzo, Giovanni Bellitto, Luca Prezzavento, Francesco Rundo, Ulas Bagci, Daniela Giordano, Rosalia Leonardi, Concetto Spampinato

Auto-TLDR; Automated Landmarking of Craniomaxillofacial CT Images Using Deep Multi-Stage Architecture
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Visual Oriented Encoder: Integrating Multimodal and Multi-Scale Contexts for Video Captioning

Auto-TLDR; Visual Oriented Encoder for Video Captioning
Abstract Slides Poster Similar
Resource-efficient DNNs for Keyword Spotting using Neural Architecture Search and Quantization
David Peter, Wolfgang Roth, Franz Pernkopf

Auto-TLDR; Neural Architecture Search for Keyword Spotting in Limited Resource Environments
Abstract Slides Poster Similar
Inferring Functional Properties from Fluid Dynamics Features
Andrea Schillaci, Maurizio Quadrio, Carlotta Pipolo, Marcello Restelli, Giacomo Boracchi

Auto-TLDR; Exploiting Convective Properties of Computational Fluid Dynamics for Medical Diagnosis
Abstract Slides Poster Similar
Segmenting Kidney on Multiple Phase CT Images Using ULBNet
Yanling Chi, Yuyu Xu, Gang Feng, Jiawei Mao, Sihua Wu, Guibin Xu, Weimin Huang
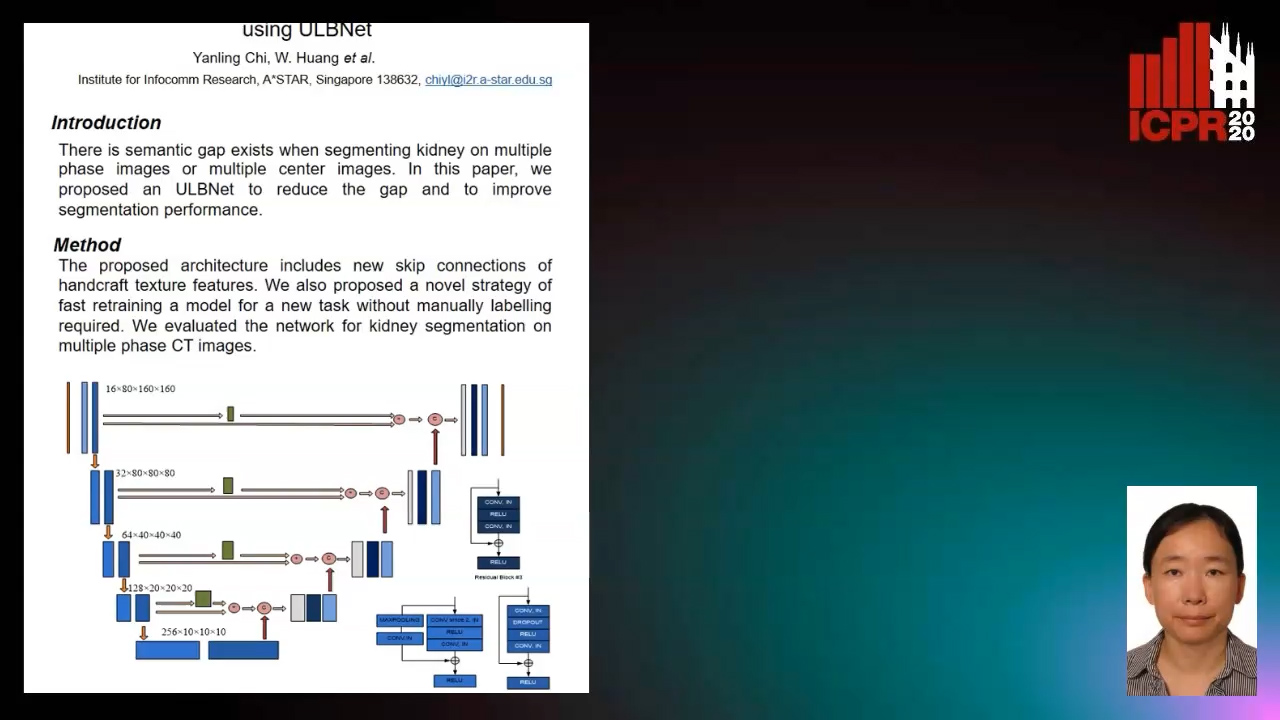
Auto-TLDR; A ULBNet network for kidney segmentation on multiple phase CT images