Robust Image Coding on Synthetic DNA: Reducing Sequencing Noise with Inpainting
Eva Gil San Antonio,
Mattia Piretti,
Melpomeni Dimopoulou,
Marc Antonini

Auto-TLDR; Noise Resilience for DNA Storage
Similar papers
Compression Strategies and Space-Conscious Representations for Deep Neural Networks
Giosuè Marinò, Gregorio Ghidoli, Marco Frasca, Dario Malchiodi

Auto-TLDR; Compression of Large Convolutional Neural Networks by Weight Pruning and Quantization
Abstract Slides Poster Similar
Computational Data Analysis for First Quantization Estimation on JPEG Double Compressed Images
Sebastiano Battiato, Oliver Giudice, Francesco Guarnera, Giovanni Puglisi

Auto-TLDR; Exploiting Discrete Cosine Transform Coefficients for Multimedia Forensics
Abstract Slides Poster Similar
MedZip: 3D Medical Images Lossless Compressor Using Recurrent Neural Network (LSTM)
Omniah Nagoor, Joss Whittle, Jingjing Deng, Benjamin Mora, Mark W. Jones

Auto-TLDR; Recurrent Neural Network for Lossless Medical Image Compression using Long Short-Term Memory
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Local Facial Attribute Transfer through Inpainting
Ricard Durall, Franz-Josef Pfreundt, Janis Keuper

Auto-TLDR; Attribute Transfer Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Recovery of 2D and 3D Layout Information through an Advanced Image Stitching Algorithm Using Scanning Electron Microscope Images
Aayush Singla, Bernhard Lippmann, Helmut Graeb

Auto-TLDR; Image Stitching for True Geometrical Layout Recovery in Nanoscale Dimension
Abstract Slides Poster Similar
Learning Defects in Old Movies from Manually Assisted Restoration
Arthur Renaudeau, Travis Seng, Axel Carlier, Jean-Denis Durou, Fabien Pierre, Francois Lauze, Jean-François Aujol

Auto-TLDR; U-Net: Detecting Defects in Old Movies by Inpainting Techniques
Abstract Slides Poster Similar
Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo, Shusaku Asada, Hirotaka Maruyama, Masaru Koide, Kohei Yamamoto, Yoshihisa Suetsugu

Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Abstract Slides Poster Similar
Graph-Based Image Decoding for Multiplexed in Situ RNA Detection
Gabriele Partel, Carolina Wahlby
Auto-TLDR; A Graph-based Decoding Approach for Multiplexed In situ RNA Detection
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar
Recursive Recognition of Offline Handwritten Mathematical Expressions
Marco Cotogni, Claudio Cusano, Antonino Nocera

Auto-TLDR; Online Handwritten Mathematical Expression Recognition with Recurrent Neural Network
Abstract Slides Poster Similar
On Identification and Retrieval of Near-Duplicate Biological Images: A New Dataset and Protocol
Thomas E. Koker, Sai Spandana Chintapalli, San Wang, Blake A. Talbot, Daniel Wainstock, Marcelo Cicconet, Mary C. Walsh

Auto-TLDR; BINDER: Bio-Image Near-Duplicate Examples Repository for Image Identification and Retrieval
RISEdb: A Novel Indoor Localization Dataset
Carlos Sanchez Belenguer, Erik Wolfart, Álvaro Casado Coscollá, Vitor Sequeira

Auto-TLDR; Indoor Localization Using LiDAR SLAM and Smartphones: A Benchmarking Dataset
Abstract Slides Poster Similar
On the Use of Benford's Law to Detect GAN-Generated Images
Nicolo Bonettini, Paolo Bestagini, Simone Milani, Stefano Tubaro

Auto-TLDR; Using Benford's Law to Detect GAN-generated Images from Natural Images
Abstract Slides Poster Similar
Joint Compressive Autoencoders for Full-Image-To-Image Hiding
Xiyao Liu, Ziping Ma, Xingbei Guo, Jialu Hou, Lei Wang, Gerald Schaefer, Hui Fang

Auto-TLDR; J-CAE: Joint Compressive Autoencoder for Image Hiding
Abstract Slides Poster Similar
Fast Implementation of 4-Bit Convolutional Neural Networks for Mobile Devices
Anton Trusov, Elena Limonova, Dmitry Slugin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; Efficient Quantized Low-Precision Neural Networks for Mobile Devices
Abstract Slides Poster Similar
Interactive Style Space of Deep Features and Style Innovation

Auto-TLDR; Interactive Style Space of Convolutional Neural Network Features
Abstract Slides Poster Similar
The HisClima Database: Historical Weather Logs for Automatic Transcription and Information Extraction
Verónica Romero, Joan Andreu Sánchez

Auto-TLDR; Automatic Handwritten Text Recognition and Information Extraction from Historical Weather Logs
Abstract Slides Poster Similar
Neuron-Based Network Pruning Based on Majority Voting
Ali Alqahtani, Xianghua Xie, Ehab Essa, Mark W. Jones

Auto-TLDR; Large-Scale Neural Network Pruning using Majority Voting
Abstract Slides Poster Similar
A Heuristic-Based Decision Tree for Connected Components Labeling of 3D Volumes
Maximilian Söchting, Stefano Allegretti, Federico Bolelli, Costantino Grana

Auto-TLDR; Entropy Partitioning Decision Tree for Connected Components Labeling
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Cancelable Biometrics Vault: A Secure Key-Binding Biometric Cryptosystem Based on Chaffing and Winnowing
Osama Ouda, Karthik Nandakumar, Arun Ross

Auto-TLDR; Cancelable Biometrics Vault for Key-binding Biometric Cryptosystem Framework
Abstract Slides Poster Similar
Anime Sketch Colorization by Component-Based Matching Using Deep Appearance Features and Graph Representation
Thien Do, Pham Van, Anh Nguyen, Trung Dang, Quoc Nguyen, Bach Hoang, Giao Nguyen

Auto-TLDR; Combining Deep Learning and Graph Representation for Sketch Colorization
Abstract Slides Poster Similar
Fully Convolutional Neural Networks for Raw Eye Tracking Data Segmentation, Generation, and Reconstruction
Wolfgang Fuhl, Yao Rong, Enkelejda Kasneci

Auto-TLDR; Semantic Segmentation of Eye Tracking Data with Fully Convolutional Neural Networks
Abstract Slides Poster Similar
To Honor Our Heroes: Analysis of the Obituaries of Australians Killed in Action in WWI and WWII

Auto-TLDR; Obituaries of World War I and World War II: A Map of Values and Virtues attributed to Australian Military Personnel
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
HP2IFS: Head Pose Estimation Exploiting Partitioned Iterated Function Systems
Carmen Bisogni, Michele Nappi, Chiara Pero, Stefano Ricciardi

Auto-TLDR; PIFS based head pose estimation using fractal coding theory and Partitioned Iterated Function Systems
Abstract Slides Poster Similar
ID Documents Matching and Localization with Multi-Hypothesis Constraints
Guillaume Chiron, Nabil Ghanmi, Ahmad Montaser Awal

Auto-TLDR; Identity Document Localization in the Wild Using Multi-hypothesis Exploration
Abstract Slides Poster Similar
Learning Image Inpainting from Incomplete Images using Self-Supervision
Sriram Yenamandra, Rohit Kumar Jena, Ansh Khurana, Suyash Awate

Auto-TLDR; Unsupervised Deep Neural Network for Semantic Image Inpainting
Abstract Slides Poster Similar
Deep Composer: A Hash-Based Duplicative Neural Network for Generating Multi-Instrument Songs
Jacob Galajda, Brandon Royal, Kien Hua

Auto-TLDR; Deep Composer for Intelligence Duplication
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
Are Multiple Cross-Correlation Identities Better Than Just Two? Improving the Estimate of Time Differences-Of-Arrivals from Blind Audio Signals
Danilo Greco, Jacopo Cavazza, Alessio Del Bue

Auto-TLDR; Improving Blind Channel Identification Using Cross-Correlation Identity for Time Differences-of-Arrivals Estimation
Abstract Slides Poster Similar
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
Exploiting Local Indexing and Deep Feature Confidence Scores for Fast Image-To-Video Search
Savas Ozkan, Gözde Bozdağı Akar

Auto-TLDR; Fast and Robust Image-to-Video Retrieval Using Local and Global Descriptors
Abstract Slides Poster Similar
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
2D Discrete Mirror Transform for Image Non-Linear Approximation
Alessandro Gnutti, Fabrizio Guerrini, Riccardo Leonardi

Auto-TLDR; Discrete Mirror Transform (DMT)
Abstract Slides Poster Similar
A Scalable Deep Neural Network to Detect Low Quality Images without a Reference
Auto-TLDR; A Deep Neural Network-based Algorithm for Non-reference Non-Reference Non-Referential Image Quality Metrics for Streaming Services
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
Expectation-Maximization for Scheduling Problems in Satellite Communication
Werner Bailer, Martin Winter, Johannes Ebert, Joel Flavio, Karin Plimon

Auto-TLDR; Unsupervised Machine Learning for Satellite Communication Using Expectation-Maximization
Abstract Slides Poster Similar
LODENet: A Holistic Approach to Offline Handwritten Chinese and Japanese Text Line Recognition
Huu Tin Hoang, Chun-Jen Peng, Hung Tran, Hung Le, Huy Hoang Nguyen

Auto-TLDR; Logographic DEComposition Encoding for Chinese and Japanese Text Line Recognition
Abstract Slides Poster Similar
Hierarchical Deep Hashing for Fast Large Scale Image Retrieval
Yongfei Zhang, Cheng Peng, Zhang Jingtao, Xianglong Liu, Shiliang Pu, Changhuai Chen

Auto-TLDR; Hierarchical indexed deep hashing for fast large scale image retrieval
Abstract Slides Poster Similar
SAILenv: Learning in Virtual Visual Environments Made Simple
Enrico Meloni, Luca Pasqualini, Matteo Tiezzi, Marco Gori, Stefano Melacci

Auto-TLDR; SAILenv: A Simple and Customized Platform for Visual Recognition in Virtual 3D Environment
Abstract Slides Poster Similar
JUMPS: Joints Upsampling Method for Pose Sequences
Lucas Mourot, Francois Le Clerc, Cédric Thébault, Pierre Hellier

Auto-TLDR; JUMPS: Increasing the Number of Joints in 2D Pose Estimation and Recovering Occluded or Missing Joints
Abstract Slides Poster Similar
Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux, Riadh Fezzani, Jean-Christophe Olivo-Marin
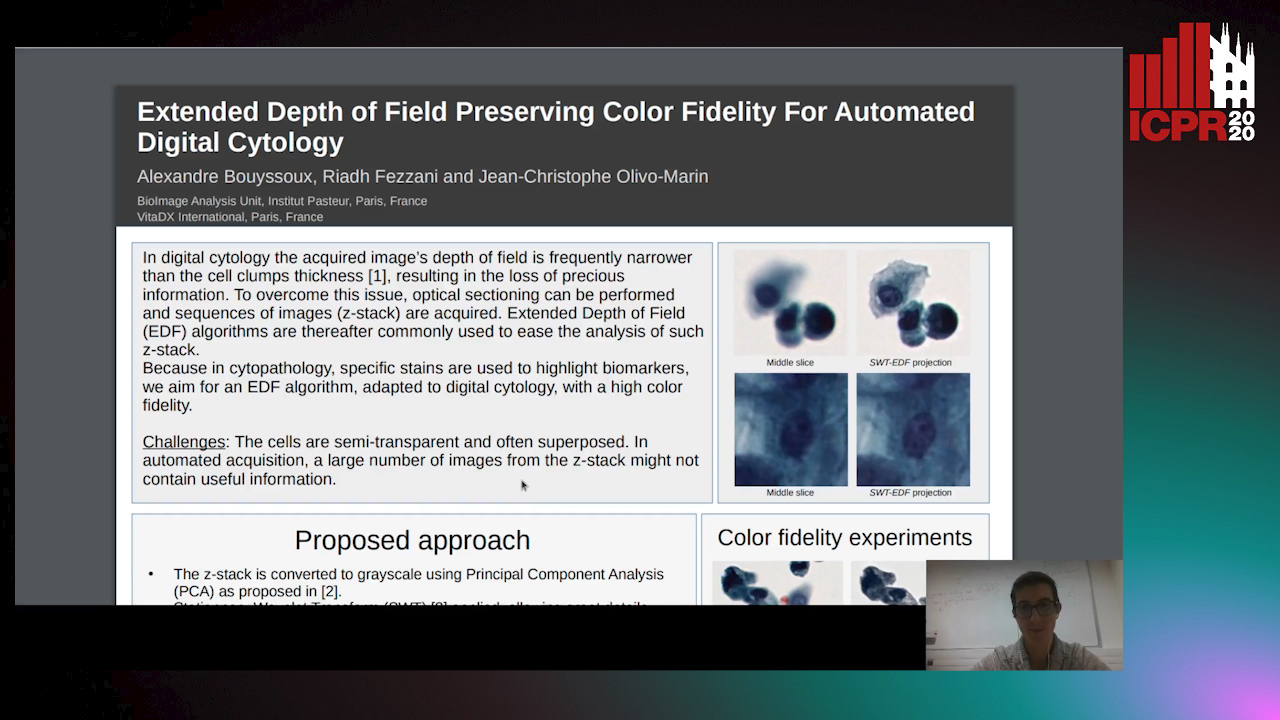
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform