Anime Sketch Colorization by Component-Based Matching Using Deep Appearance Features and Graph Representation
Thien Do,
Pham Van,
Anh Nguyen,
Trung Dang,
Quoc Nguyen,
Bach Hoang,
Giao Nguyen

Auto-TLDR; Combining Deep Learning and Graph Representation for Sketch Colorization
Similar papers
Stylized-Colorization for Line Arts
Tzu-Ting Fang, Minh Duc Vo, Akihiro Sugimoto, Shang-Hong Lai

Auto-TLDR; Stylized-colorization using GAN-based End-to-End Model for Anime
Abstract Slides Poster Similar
UCCTGAN: Unsupervised Clothing Color Transformation Generative Adversarial Network
Shuming Sun, Xiaoqiang Li, Jide Li

Auto-TLDR; An Unsupervised Clothing Color Transformation Generative Adversarial Network
Abstract Slides Poster Similar
3D Pots Configuration System by Optimizing Over Geometric Constraints
Jae Eun Kim, Muhammad Zeeshan Arshad, Seong Jong Yoo, Je Hyeong Hong, Jinwook Kim, Young Min Kim

Auto-TLDR; Optimizing 3D Configurations for Stable Pottery Restoration from irregular and noisy evidence
Abstract Slides Poster Similar
Large-Scale Historical Watermark Recognition: Dataset and a New Consistency-Based Approach
Xi Shen, Ilaria Pastrolin, Oumayma Bounou, Spyros Gidaris, Marc Smith, Olivier Poncet, Mathieu Aubry

Auto-TLDR; Historical Watermark Recognition with Fine-Grained Cross-Domain One-Shot Instance Recognition
Abstract Slides Poster Similar
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
Sketch-Based Community Detection Via Representative Node Sampling
Mahlagha Sedghi, Andre Beckus, George Atia

Auto-TLDR; Sketch-based Clustering of Community Detection Using a Small Sketch
Abstract Slides Poster Similar
Local Facial Attribute Transfer through Inpainting
Ricard Durall, Franz-Josef Pfreundt, Janis Keuper

Auto-TLDR; Attribute Transfer Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Learning to Take Directions One Step at a Time
Qiyang Hu, Adrian Wälchli, Tiziano Portenier, Matthias Zwicker, Paolo Favaro

Auto-TLDR; Generating a Sequence of Motion Strokes from a Single Image
Abstract Slides Poster Similar
Few-Shot Font Generation with Deep Metric Learning
Haruka Aoki, Koki Tsubota, Hikaru Ikuta, Kiyoharu Aizawa

Auto-TLDR; Deep Metric Learning for Japanese Typographic Font Synthesis
Abstract Slides Poster Similar
Interactive Style Space of Deep Features and Style Innovation

Auto-TLDR; Interactive Style Space of Convolutional Neural Network Features
Abstract Slides Poster Similar
Semantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Pierfrancesco Ardino, Yahui Liu, Elisa Ricci, Bruno Lepri, Marco De Nadai

Auto-TLDR; Semantic-Guided Inpainting of Complex Urban Scene Using Semantic Segmentation and Generation
Abstract Slides Poster Similar
Machine-Learned Regularization and Polygonization of Building Segmentation Masks
Stefano Zorzi, Ksenia Bittner, Friedrich Fraundorfer

Auto-TLDR; Automatic Regularization and Polygonization of Building Segmentation masks using Generative Adversarial Network
Abstract Slides Poster Similar
UDBNET: Unsupervised Document Binarization Network Via Adversarial Game
Amandeep Kumar, Shuvozit Ghose, Pinaki Nath Chowdhury, Partha Pratim Roy, Umapada Pal

Auto-TLDR; Three-player Min-max Adversarial Game for Unsupervised Document Binarization
Abstract Slides Poster Similar
Automated Whiteboard Lecture Video Summarization by Content Region Detection and Representation
Bhargava Urala Kota, Alexander Stone, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; A Framework for Summarizing Whiteboard Lecture Videos Using Feature Representations of Handwritten Content Regions
On Morphological Hierarchies for Image Sequences
Caglayan Tuna, Alain Giros, François Merciol, Sébastien Lefèvre

Auto-TLDR; Comparison of Hierarchies for Image Sequences
Abstract Slides Poster Similar
Shape Consistent 2D Keypoint Estimation under Domain Shift
Levi Vasconcelos, Massimiliano Mancini, Davide Boscaini, Barbara Caputo, Elisa Ricci

Auto-TLDR; Deep Adaptation for Keypoint Prediction under Domain Shift
Abstract Slides Poster Similar
Siamese Graph Convolution Network for Face Sketch Recognition
Liang Fan, Xianfang Sun, Paul Rosin

Auto-TLDR; A novel Siamese graph convolution network for face sketch recognition
Abstract Slides Poster Similar
GarmentGAN: Photo-Realistic Adversarial Fashion Transfer
Amir Hossein Raffiee, Michael Sollami

Auto-TLDR; GarmentGAN: A Generative Adversarial Network for Image-Based Garment Transfer
Abstract Slides Poster Similar
Global Image Sentiment Transfer
Jie An, Tianlang Chen, Songyang Zhang, Jiebo Luo

Auto-TLDR; Image Sentiment Transfer Using DenseNet121 Architecture
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
The Color Out of Space: Learning Self-Supervised Representations for Earth Observation Imagery
Stefano Vincenzi, Angelo Porrello, Pietro Buzzega, Marco Cipriano, Pietro Fronte, Roberto Cuccu, Carla Ippoliti, Annamaria Conte, Simone Calderara

Auto-TLDR; Satellite Image Representation Learning for Remote Sensing
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Learning Embeddings for Image Clustering: An Empirical Study of Triplet Loss Approaches
Kalun Ho, Janis Keuper, Franz-Josef Pfreundt, Margret Keuper

Auto-TLDR; Clustering Objectives for K-means and Correlation Clustering Using Triplet Loss
Abstract Slides Poster Similar
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar
VITON-GT: An Image-Based Virtual Try-On Model with Geometric Transformations
Matteo Fincato, Federico Landi, Marcella Cornia, Fabio Cesari, Rita Cucchiara

Auto-TLDR; VITON-GT: An Image-based Virtual Try-on Architecture for Fashion Catalogs
Abstract Slides Poster Similar
Attributes Aware Face Generation with Generative Adversarial Networks
Zheng Yuan, Jie Zhang, Shiguang Shan, Xilin Chen

Auto-TLDR; AFGAN: A Generative Adversarial Network for Attributes Aware Face Image Generation
Abstract Slides Poster Similar
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
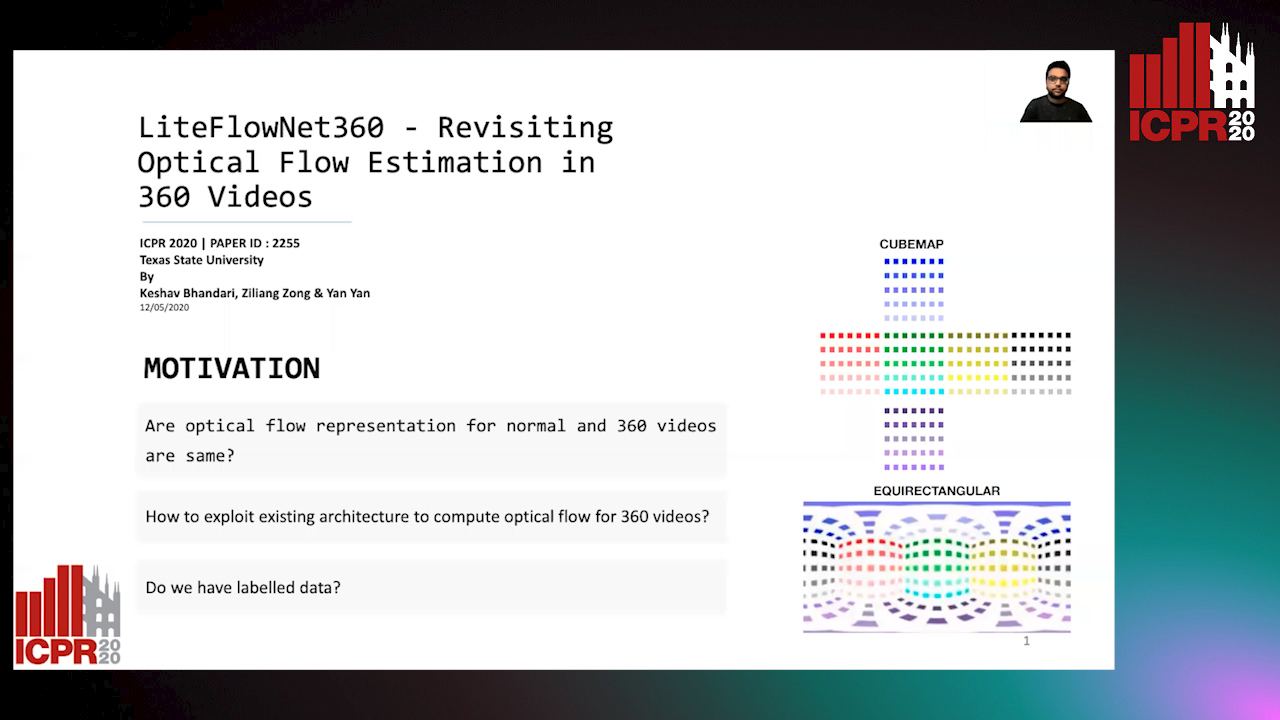
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
Equation Attention Relationship Network (EARN) : A Geometric Deep Metric Framework for Learning Similar Math Expression Embedding
Saleem Ahmed, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; Representational Learning for Similarity Based Retrieval of Mathematical Expressions
Abstract Slides Poster Similar
Multi-Scale Keypoint Matching

Auto-TLDR; Multi-Scale Keypoint Matching Using Multi-Scale Information
Abstract Slides Poster Similar
Unsupervised Contrastive Photo-To-Caricature Translation Based on Auto-Distortion
Yuhe Ding, Xin Ma, Mandi Luo, Aihua Zheng, Ran He

Auto-TLDR; Unsupervised contrastive photo-to-caricature translation with style loss
Abstract Slides Poster Similar
Story Comparison for Estimating Field of View Overlap in a Video Collection
Thierry Malon, Sylvie Chambon, Alain Crouzil, Vincent Charvillat

Auto-TLDR; Finding Videos with Overlapping Fields of View Using Video Data
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Edge-Aware Monocular Dense Depth Estimation with Morphology
Zhi Li, Xiaoyang Zhu, Haitao Yu, Qi Zhang, Yongshi Jiang

Auto-TLDR; Spatio-Temporally Smooth Dense Depth Maps Using Only a CPU
Abstract Slides Poster Similar
Weakly Supervised Geodesic Segmentation of Egyptian Mummy CT Scans
Avik Hati, Matteo Bustreo, Diego Sona, Vittorio Murino, Alessio Del Bue

Auto-TLDR; A Weakly Supervised and Efficient Interactive Segmentation of Ancient Egyptian Mummies CT Scans Using Geodesic Distance Measure and GrabCut
Abstract Slides Poster Similar
Sketch-SNet: Deeper Subdivision of Temporal Cues for Sketch Recognition
Yizhou Tan, Lan Yang, Honggang Zhang

Auto-TLDR; Sketch Recognition using Invariable Structural Feature and Drawing Habits Feature
Abstract Slides Poster Similar
Learning Defects in Old Movies from Manually Assisted Restoration
Arthur Renaudeau, Travis Seng, Axel Carlier, Jean-Denis Durou, Fabien Pierre, Francois Lauze, Jean-François Aujol

Auto-TLDR; U-Net: Detecting Defects in Old Movies by Inpainting Techniques
Abstract Slides Poster Similar
Enhancing Depth Quality of Stereo Vision Using Deep Learning-Based Prior Information of the Driving Environment
Weifu Li, Vijay John, Seiichi Mita

Auto-TLDR; A Novel Post-processing Mathematical Framework for Stereo Vision
Abstract Slides Poster Similar
Novel View Synthesis from a 6-DoF Pose by Two-Stage Networks
Xiang Guo, Bo Li, Yuchao Dai, Tongxin Zhang, Hui Deng

Auto-TLDR; Novel View Synthesis from a 6-DoF Pose Using Generative Adversarial Network
Abstract Slides Poster Similar
3D Semantic Labeling of Photogrammetry Meshes Based on Active Learning
Mengqi Rong, Shuhan Shen, Zhanyi Hu

Auto-TLDR; 3D Semantic Expression of Urban Scenes Based on Active Learning
Abstract Slides Poster Similar
G-FAN: Graph-Based Feature Aggregation Network for Video Face Recognition
He Zhao, Yongjie Shi, Xin Tong, Jingsi Wen, Xianghua Ying, Jinshi Hongbin Zha

Auto-TLDR; Graph-based Feature Aggregation Network for Video Face Recognition
Abstract Slides Poster Similar
Learning Disentangled Representations for Identity Preserving Surveillance Face Camouflage
Jingzhi Li, Lutong Han, Hua Zhang, Xiaoguang Han, Jingguo Ge, Xiaochu Cao

Auto-TLDR; Individual Face Privacy under Surveillance Scenario with Multi-task Loss Function
Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Abstract Slides Poster Similar
A Neural Lip-Sync Framework for Synthesizing Photorealistic Virtual News Anchors
Ruobing Zheng, Zhou Zhu, Bo Song, Ji Changjiang

Auto-TLDR; Lip-sync: Synthesis of a Virtual News Anchor for Low-Delayed Applications
Abstract Slides Poster Similar
Learning Low-Shot Generative Networks for Cross-Domain Data
Hsuan-Kai Kao, Cheng-Che Lee, Wei-Chen Chiu

Auto-TLDR; Learning Generators for Cross-Domain Data under Low-Shot Learning
Abstract Slides Poster Similar
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Movement-Induced Priors for Deep Stereo
Yuxin Hou, Muhammad Kamran Janjua, Juho Kannala, Arno Solin

Auto-TLDR; Fusing Stereo Disparity Estimation with Movement-induced Prior Information
Abstract Slides Poster Similar
An Unsupervised Approach towards Varying Human Skin Tone Using Generative Adversarial Networks
Debapriya Roy, Diganta Mukherjee, Bhabatosh Chanda

Auto-TLDR; Unsupervised Skin Tone Change Using Augmented Reality Based Models
Abstract Slides Poster Similar