Feasibility Study of Using MyoBand for Learning Electronic Keyboard

Auto-TLDR; Autonomous Finger-Based Music Instrument Learning using Electromyography Using MyoBand and Machine Learning
Similar papers
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Gibran Benitez-Garcia, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; IPN Hand: A Benchmark Dataset for Continuous Hand Gesture Recognition
Abstract Slides Poster Similar
Handwritten Signature and Text Based User Verification Using Smartwatch
Raghavendra Ramachandra, Sushma Venkatesh, Raja Kiran, Christoph Busch
Auto-TLDR; A novel technique for user verification using a smartwatch based on writing pattern or signing pattern
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Translation Resilient Opportunistic WiFi Sensing
Mohammud Junaid Bocus, Wenda Li, Jonas Paulavičius, Ryan Mcconville, Raul Santos-Rodriguez, Kevin Chetty, Robert Piechocki

Auto-TLDR; Activity Recognition using Fine-Grained WiFi Channel State Information using WiFi CSI
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Influence of Event Duration on Automatic Wheeze Classification
Bruno M Rocha, Diogo Pessoa, Alda Marques, Paulo Carvalho, Rui Pedro Paiva

Auto-TLDR; Experimental Design of the Non-wheeze Class for Wheeze Classification
Abstract Slides Poster Similar
Conditional-UNet: A Condition-Aware Deep Model for Coherent Human Activity Recognition from Wearables
Liming Zhang, Wenbin Zhang, Nathalie Japkowicz

Auto-TLDR; Coherent Human Activity Recognition from Multi-Channel Time Series Data
Abstract Slides Poster Similar
Concept Embedding through Canonical Forms: A Case Study on Zero-Shot ASL Recognition
Azamat Kamzin, Apurupa Amperyani, Prasanth Sukhapalli, Ayan Banerjee, Sandeep Gupta

Auto-TLDR; A canonical form of gestures in American Sign Language
Abstract Slides Poster Similar
Estimation of Clinical Tremor Using Spatio-Temporal Adversarial AutoEncoder
Li Zhang, Vidya Koesmahargyo, Isaac Galatzer-Levy

Auto-TLDR; ST-AAE: Spatio-temporal Adversarial Autoencoder for Clinical Assessment of Hand Tremor Frequency and Severity
Abstract Slides Poster Similar
Deep Transfer Learning for Alzheimer’s Disease Detection
Nicole Cilia, Claudio De Stefano, Francesco Fontanella, Claudio Marrocco, Mario Molinara, Alessandra Scotto Di Freca

Auto-TLDR; Automatic Detection of Handwriting Alterations for Alzheimer's Disease Diagnosis using Dynamic Features
Abstract Slides Poster Similar
Air-Writing with Sparse Network of Radars Using Spatio-Temporal Learning
Muhammad Arsalan, Avik Santra, Kay Bierzynski, Vadim Issakov

Auto-TLDR; An Air-writing System for Sparse Radars using Deep Convolutional Neural Networks
Abstract Slides Poster Similar
Automatic Classification of Human Granulosa Cells in Assisted Reproductive Technology Using Vibrational Spectroscopy Imaging
Marina Paolanti, Emanuele Frontoni, Giorgia Gioacchini, Giorgini Elisabetta, Notarstefano Valentina, Zacà Carlotta, Carnevali Oliana, Andrea Borini, Marco Mameli

Auto-TLDR; Predicting Oocyte Quality in Assisted Reproductive Technology Using Machine Learning Techniques
Abstract Slides Poster Similar
Ballroom Dance Recognition from Audio Recordings
Tomas Pavlin, Jan Cech, Jiri Matas

Auto-TLDR; A CNN-based approach to classify ballroom dances given audio recordings
Abstract Slides Poster Similar
Magnifying Spontaneous Facial Micro Expressions for Improved Recognition
Pratikshya Sharma, Sonya Coleman, Pratheepan Yogarajah, Laurence Taggart, Pradeepa Samarasinghe

Auto-TLDR; Eulerian Video Magnification for Micro Expression Recognition
Abstract Slides Poster Similar
Learning Dictionaries of Kinematic Primitives for Action Classification
Alessia Vignolo, Nicoletta Noceti, Alessandra Sciutti, Francesca Odone, Giulio Sandini

Auto-TLDR; Action Understanding using Visual Motion Primitives
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Human or Machine? It Is Not What You Write, but How You Write It
Luis Leiva, Moises Diaz, M.A. Ferrer, Réjean Plamondon

Auto-TLDR; Behavioral Biometrics via Handwritten Symbols for Identification and Verification
Abstract Slides Poster Similar
EEG-Based Cognitive State Assessment Using Deep Ensemble Model and Filter Bank Common Spatial Pattern
Debashis Das Chakladar, Shubhashis Dey, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; A Deep Ensemble Model for Cognitive State Assessment using EEG-based Cognitive State Analysis
Abstract Slides Poster Similar
Exploring Seismocardiogram Biometrics with Wavelet Transform
Po-Ya Hsu, Po-Han Hsu, Hsin-Li Liu

Auto-TLDR; Seismocardiogram Biometric Matching Using Wavelet Transform and Deep Learning Models
Abstract Slides Poster Similar
Anticipating Activity from Multimodal Signals
Tiziana Rotondo, Giovanni Maria Farinella, Davide Giacalone, Sebastiano Mauro Strano, Valeria Tomaselli, Sebastiano Battiato

Auto-TLDR; Exploiting Multimodal Signal Embedding Space for Multi-Action Prediction
Abstract Slides Poster Similar
Rotation Detection in Finger Vein Biometrics Using CNNs
Bernhard Prommegger, Georg Wimmer, Andreas Uhl

Auto-TLDR; A CNN based rotation detector for finger vein recognition
Abstract Slides Poster Similar
Depth Videos for the Classification of Micro-Expressions
Ankith Jain Rakesh Kumar, Bir Bhanu, Christopher Casey, Sierra Cheung, Aaron Seitz

Auto-TLDR; RGB-D Dataset for the Classification of Facial Micro-expressions
Abstract Slides Poster Similar
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Location Prediction in Real Homes of Older Adults based on K-Means in Low-Resolution Depth Videos
Simon Simonsson, Flávia Dias Casagrande, Evi Zouganeli

Auto-TLDR; Semi-supervised Learning for Location Recognition and Prediction in Smart Homes using Depth Video Cameras
Abstract Slides Poster Similar
Algorithm Recommendation for Data Streams
Jáder Martins Camboim De Sá, Andre Luis Debiaso Rossi, Gustavo Enrique De Almeida Prado Alves Batista, Luís Paulo Faina Garcia

Auto-TLDR; Meta-Learning for Algorithm Selection in Time-Changing Data Streams
Abstract Slides Poster Similar
Classifying Eye-Tracking Data Using Saliency Maps
Shafin Rahman, Sejuti Rahman, Omar Shahid, Md. Tahmeed Abdullah, Jubair Ahmed Sourov

Auto-TLDR; Saliency-based Feature Extraction for Automatic Classification of Eye-tracking Data
Abstract Slides Poster Similar
Video Analytics Gait Trend Measurement for Fall Prevention and Health Monitoring
Lawrence O'Gorman, Xinyi Liu, Md Imran Sarker, Mariofanna Milanova

Auto-TLDR; Towards Health Monitoring of Gait with Deep Learning
Abstract Slides Poster Similar
Exploiting the Logits: Joint Sign Language Recognition and Spell-Correction
Christina Runkel, Stefan Dorenkamp, Hartmut Bauermeister, Michael Möller

Auto-TLDR; A Convolutional Neural Network for Spell-correction in Sign Language Videos
Abstract Slides Poster Similar
Fall Detection by Human Pose Estimation and Kinematic Theory
Vincenzo Dentamaro, Donato Impedovo, Giuseppe Pirlo

Auto-TLDR; A Decision Support System for Automatic Fall Detection on Le2i and URFD Datasets
Abstract Slides Poster Similar
Image Defocus Analysis for Finger Detection on a Virtual Keyboard
Miwa Michio, Honda Kenji, Sato Makoto
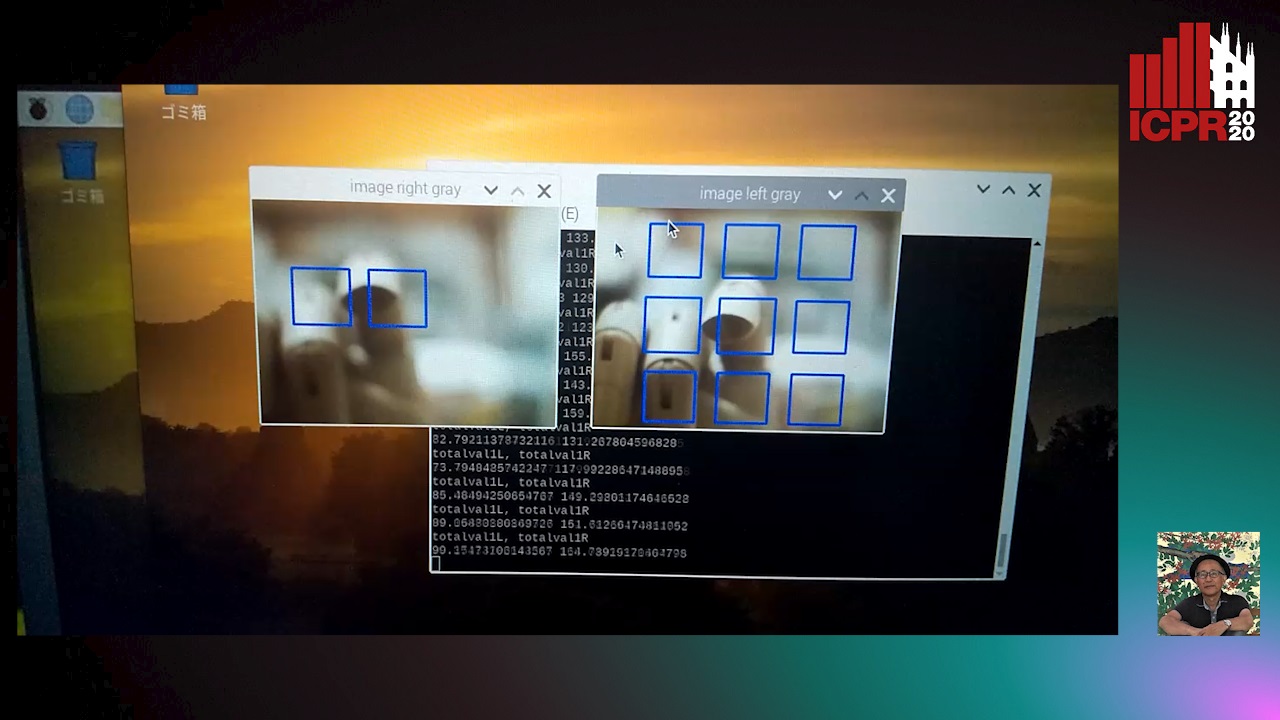
Auto-TLDR; Analysis of defocus information when a finger touching a virtual keyboard by using DCT (Discrete Cosine Transform) coefficient without detecting 3D position
Abstract Slides Poster Similar
Gender Classification Using Video Sequences of Body Sway Recorded by Overhead Camera
Takuya Kamitani, Yuta Yamaguchi, Shintaro Nakatani, Masashi Nishiyama, Yoshio Iwai

Auto-TLDR; Spatio-Temporal Feature for Gender Classification of a Standing Person Using Body Stance Using Time-Series Signals
Abstract Slides Poster Similar
Explainable Online Validation of Machine Learning Models for Practical Applications
Wolfgang Fuhl, Yao Rong, Thomas Motz, Michael Scheidt, Andreas Markus Hartel, Andreas Koch, Enkelejda Kasneci

Auto-TLDR; A Reformulation of Regression and Classification for Machine Learning Algorithm Validation
Abstract Slides Poster Similar
Attribute-Based Quality Assessment for Demographic Estimation in Face Videos
Fabiola Becerra-Riera, Annette Morales-González, Heydi Mendez-Vazquez, Jean-Luc Dugelay

Auto-TLDR; Facial Demographic Estimation in Video Scenarios Using Quality Assessment
Real-Time Drone Detection and Tracking with Visible, Thermal and Acoustic Sensors
Fredrik Svanström, Cristofer Englund, Fernando Alonso-Fernandez

Auto-TLDR; Automatic multi-sensor drone detection using sensor fusion
Abstract Slides Poster Similar
Detection of Calls from Smart Speaker Devices
Vinay Maddali, David Looney, Kailash Patil

Auto-TLDR; Distinguishing Between Smart Speaker and Cell Devices Using Only the Audio Using a Feature Set
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
Fingerprints, Forever Young?
Roman Kessler, Olaf Henniger, Christoph Busch

Auto-TLDR; Mated Similarity Scores for Fingerprint Recognition: A Hierarchical Linear Model
Abstract Slides Poster Similar
Fully Convolutional Neural Networks for Raw Eye Tracking Data Segmentation, Generation, and Reconstruction
Wolfgang Fuhl, Yao Rong, Enkelejda Kasneci

Auto-TLDR; Semantic Segmentation of Eye Tracking Data with Fully Convolutional Neural Networks
Abstract Slides Poster Similar
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
Real-Time Driver Drowsiness Detection Using Facial Action Units
Malaika Vijay, Nandagopal Netrakanti Vinayak, Maanvi Nunna, Subramanyam Natarajan

Auto-TLDR; Real-Time Detection of Driver Drowsiness using Facial Action Units using Extreme Gradient Boosting
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Jinting Wu, Yujia Zhang, Xiao-Guang Zhao

Auto-TLDR; Generalized Zero-Shot Learning for Hand Gesture Recognition
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Feature Engineering and Stacked Echo State Networks for Musical Onset Detection
Peter Steiner, Azarakhsh Jalalvand, Simon Stone, Peter Birkholz

Auto-TLDR; Echo State Networks for Onset Detection in Music Analysis
Abstract Slides Poster Similar
Recognizing American Sign Language Nonmanual Signal Grammar Errors in Continuous Videos
Elahe Vahdani, Longlong Jing, Ying-Li Tian, Matt Huenerfauth

Auto-TLDR; ASL-HW-RGBD: Recognizing Grammatical Errors in Continuous Sign Language
Abstract Slides Poster Similar
Toward Building a Data-Driven System ForDetecting Mounting Actions of Black Beef Cattle
Yuriko Kawano, Susumu Saito, Nakano Teppei, Ikumi Kondo, Ryota Yamazaki, Hiromi Kusaka, Minoru Sakaguchi, Tetsuji Ogawa

Auto-TLDR; Cattle Mounting Action Detection Using Crowdsourcing and Pattern Recognition
GazeMAE: General Representations of Eye Movements Using a Micro-Macro Autoencoder
Louise Gillian C. Bautista, Prospero Naval

Auto-TLDR; Fast and Slow Eye Movement Representations for Sentiment-agnostic Eye Tracking
Abstract Slides Poster Similar