Concept Embedding through Canonical Forms: A Case Study on Zero-Shot ASL Recognition
Azamat Kamzin,
Apurupa Amperyani,
Prasanth Sukhapalli,
Ayan Banerjee,
Sandeep Gupta

Auto-TLDR; A canonical form of gestures in American Sign Language
Similar papers
A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Jinting Wu, Yujia Zhang, Xiao-Guang Zhao

Auto-TLDR; Generalized Zero-Shot Learning for Hand Gesture Recognition
Abstract Slides Poster Similar
Recognizing American Sign Language Nonmanual Signal Grammar Errors in Continuous Videos
Elahe Vahdani, Longlong Jing, Ying-Li Tian, Matt Huenerfauth

Auto-TLDR; ASL-HW-RGBD: Recognizing Grammatical Errors in Continuous Sign Language
Abstract Slides Poster Similar
Exploiting the Logits: Joint Sign Language Recognition and Spell-Correction
Christina Runkel, Stefan Dorenkamp, Hartmut Bauermeister, Michael Möller

Auto-TLDR; A Convolutional Neural Network for Spell-correction in Sign Language Videos
Abstract Slides Poster Similar
Pose-Based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Zhengyuan Yang, Amanda Kay, Yuncheng Li, Wendi Cross, Jiebo Luo

Auto-TLDR; Body Language Based Emotion Recognition for Psychiatric Symptoms Prediction
Abstract Slides Poster Similar
Continuous Sign Language Recognition with Iterative Spatiotemporal Fine-Tuning
Kenessary Koishybay, Medet Mukushev, Anara Sandygulova

Auto-TLDR; A Deep Neural Network for Continuous Sign Language Recognition with Iterative Gloss Recognition
Abstract Slides Poster Similar
Context Matters: Self-Attention for Sign Language Recognition
Fares Ben Slimane, Mohamed Bouguessa

Auto-TLDR; Attentional Network for Continuous Sign Language Recognition
Abstract Slides Poster Similar
Applying (3+2+1)D Residual Neural Network with Frame Selection for Hong Kong Sign Language Recognition
Zhenxing Zhou, King-Shan Lui, Vincent W.L. Tam, Edmund Y. Lam

Auto-TLDR; Hong Kong Sign Language Recognition with 3D Residual Neural Network and Resilience Model
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Gibran Benitez-Garcia, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; IPN Hand: A Benchmark Dataset for Continuous Hand Gesture Recognition
Abstract Slides Poster Similar
Recognizing Bengali Word Images - A Zero-Shot Learning Perspective
Sukalpa Chanda, Daniël Arjen Willem Haitink, Prashant Kumar Prasad, Jochem Baas, Umapada Pal, Lambert Schomaker

Auto-TLDR; Zero-Shot Learning for Word Recognition in Bengali Script
Abstract Slides Poster Similar
Learning Dictionaries of Kinematic Primitives for Action Classification
Alessia Vignolo, Nicoletta Noceti, Alessandra Sciutti, Francesca Odone, Giulio Sandini

Auto-TLDR; Action Understanding using Visual Motion Primitives
Abstract Slides Poster Similar
Conditional-UNet: A Condition-Aware Deep Model for Coherent Human Activity Recognition from Wearables
Liming Zhang, Wenbin Zhang, Nathalie Japkowicz

Auto-TLDR; Coherent Human Activity Recognition from Multi-Channel Time Series Data
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Incrementally Zero-Shot Detection by an Extreme Value Analyzer
Sixiao Zheng, Yanwei Fu, Yanxi Hou

Auto-TLDR; IZSD-EVer: Incremental Zero-Shot Detection for Incremental Learning
Occlusion-Tolerant and Personalized 3D Human Pose Estimation in RGB Images

Auto-TLDR; Real-Time 3D Human Pose Estimation in BVH using Inverse Kinematics Solver and Neural Networks
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar
Feasibility Study of Using MyoBand for Learning Electronic Keyboard

Auto-TLDR; Autonomous Finger-Based Music Instrument Learning using Electromyography Using MyoBand and Machine Learning
Abstract Slides Poster Similar
Deep Gait Relative Attribute Using a Signed Quadratic Contrastive Loss
Yuta Hayashi, Shehata Allam, Yasushi Makihara, Daigo Muramatsu, Yasushi Yagi

Auto-TLDR; Signal-Contrastive Loss for Gait Attributes Estimation
VSB^2-Net: Visual-Semantic Bi-Branch Network for Zero-Shot Hashing
Xin Li, Xiangfeng Wang, Bo Jin, Wenjie Zhang, Jun Wang, Hongyuan Zha

Auto-TLDR; VSB^2-Net: inductive zero-shot hashing for image retrieval
Abstract Slides Poster Similar
Developing Motion Code Embedding for Action Recognition in Videos
Maxat Alibayev, David Andrea Paulius, Yu Sun

Auto-TLDR; Motion Embedding via Motion Codes for Action Recognition
Abstract Slides Poster Similar
Heterogeneous Graph-Based Knowledge Transfer for Generalized Zero-Shot Learning
Junjie Wang, Xiangfeng Wang, Bo Jin, Junchi Yan, Wenjie Zhang, Hongyuan Zha

Auto-TLDR; Heterogeneous Graph-based Knowledge Transfer for Generalized Zero-Shot Learning
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Light3DPose: Real-Time Multi-Person 3D Pose Estimation from Multiple Views
Alessio Elmi, Davide Mazzini, Pietro Tortella

Auto-TLDR; 3D Pose Estimation of Multiple People from a Few calibrated Camera Views using Deep Learning
Abstract Slides Poster Similar
Prior Knowledge about Attributes: Learning a More Effective Potential Space for Zero-Shot Recognition

Auto-TLDR; Attribute Correlation Potential Space Generation for Zero-Shot Learning
Abstract Slides Poster Similar
Rotational Adjoint Methods for Learning-Free 3D Human Pose Estimation from IMU Data
Caterina Emilia Agelide Buizza, Yiannis Demiris

Auto-TLDR; Learning-free 3D Human Pose Estimation from Inertial Measurement Unit Data
Automatic Annotation of Corpora for Emotion Recognition through Facial Expressions Analysis
Alex Mircoli, Claudia Diamantini, Domenico Potena, Emanuele Storti

Auto-TLDR; Automatic annotation of video subtitles on the basis of facial expressions using machine learning algorithms
Abstract Slides Poster Similar
SL-DML: Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Raphael Memmesheimer, Nick Theisen, Dietrich Paulus

Auto-TLDR; One-Shot Action Recognition using Metric Learning
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Renshu Gu, Gaoang Wang, Jenq-Neng Hwang

Auto-TLDR; 3D Human Pose Estimation for Multi-Human Videos with Occlusion
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Sequential Non-Rigid Factorisation for Head Pose Estimation
Stefania Cristina, Kenneth Patrick Camilleri

Auto-TLDR; Sequential Shape-and-Motion Factorisation for Head Pose Estimation in Eye-Gaze Tracking
Abstract Slides Poster Similar
Text Synopsis Generation for Egocentric Videos
Aidean Sharghi, Niels Lobo, Mubarak Shah

Auto-TLDR; Egocentric Video Summarization Using Multi-task Learning for End-to-End Learning
Multi-Attribute Learning with Highly Imbalanced Data
Lady Viviana Beltran Beltran, Mickaël Coustaty, Nicholas Journet, Juan C. Caicedo, Antoine Doucet

Auto-TLDR; Data Imbalance in Multi-Attribute Deep Learning Models: Adaptation to face each one of the problems derived from imbalance
Abstract Slides Poster Similar
Information Graphic Summarization Using a Collection of Multimodal Deep Neural Networks
Edward Kim, Connor Onweller, Kathleen F. Mccoy

Auto-TLDR; A multimodal deep learning framework that can generate summarization text supporting the main idea of an information graphic for presentation to blind or visually impaired
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
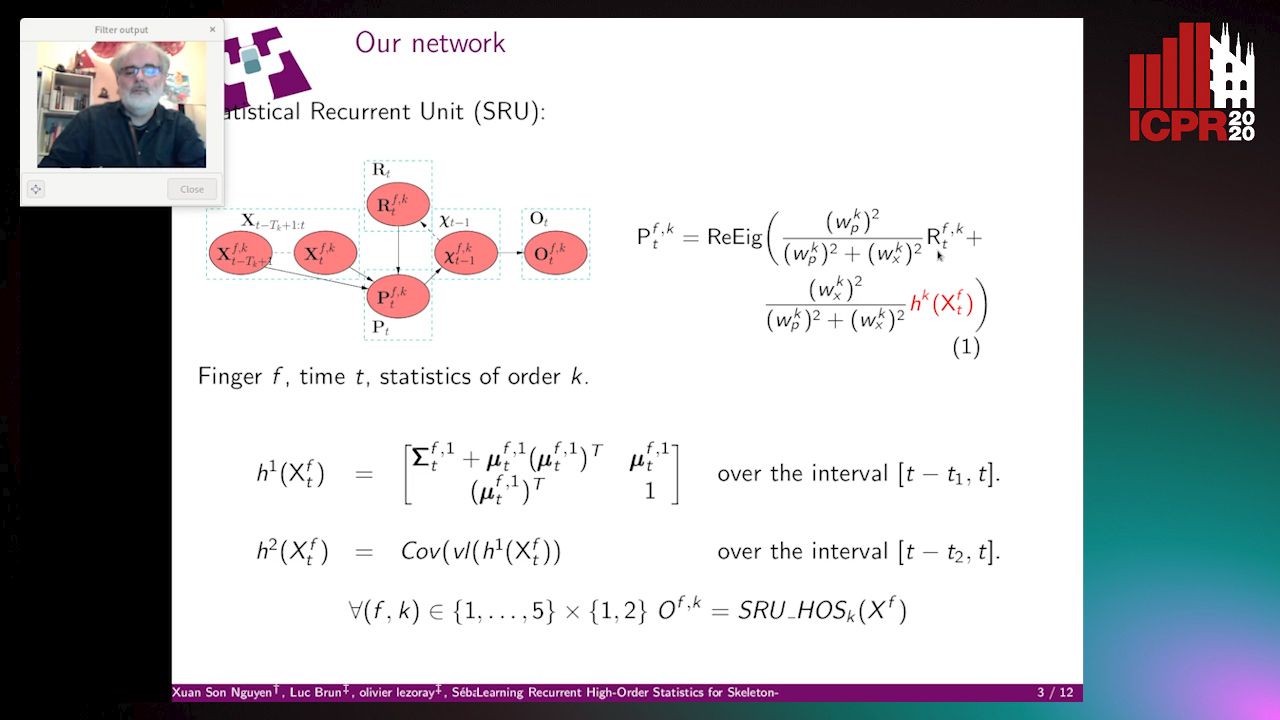
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
Real Time Fencing Move Classification and Detection at Touch Time During a Fencing Match
Cem Ekin Sunal, Chris G. Willcocks, Boguslaw Obara

Auto-TLDR; Fencing Body Move Classification and Detection Using Deep Learning
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
Depth Videos for the Classification of Micro-Expressions
Ankith Jain Rakesh Kumar, Bir Bhanu, Christopher Casey, Sierra Cheung, Aaron Seitz

Auto-TLDR; RGB-D Dataset for the Classification of Facial Micro-expressions
Abstract Slides Poster Similar
Estimation of Clinical Tremor Using Spatio-Temporal Adversarial AutoEncoder
Li Zhang, Vidya Koesmahargyo, Isaac Galatzer-Levy

Auto-TLDR; ST-AAE: Spatio-temporal Adversarial Autoencoder for Clinical Assessment of Hand Tremor Frequency and Severity
Abstract Slides Poster Similar
StrongPose: Bottom-up and Strong Keypoint Heat Map Based Pose Estimation

Auto-TLDR; StrongPose: A bottom-up box-free approach for human pose estimation and action recognition
Abstract Slides Poster Similar
Inner Eye Canthus Localization for Human Body Temperature Screening
Claudio Ferrari, Lorenzo Berlincioni, Marco Bertini, Alberto Del Bimbo

Auto-TLDR; Automatic Localization of the Inner Eye Canthus in Thermal Face Images using 3D Morphable Face Model
Abstract Slides Poster Similar
Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge
Clemens-Alexander Brust, Björn Barz, Joachim Denzler

Auto-TLDR; Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation
Abstract Slides Poster Similar
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
Translation Resilient Opportunistic WiFi Sensing
Mohammud Junaid Bocus, Wenda Li, Jonas Paulavičius, Ryan Mcconville, Raul Santos-Rodriguez, Kevin Chetty, Robert Piechocki

Auto-TLDR; Activity Recognition using Fine-Grained WiFi Channel State Information using WiFi CSI
Abstract Slides Poster Similar
Explainable Online Validation of Machine Learning Models for Practical Applications
Wolfgang Fuhl, Yao Rong, Thomas Motz, Michael Scheidt, Andreas Markus Hartel, Andreas Koch, Enkelejda Kasneci

Auto-TLDR; A Reformulation of Regression and Classification for Machine Learning Algorithm Validation
Abstract Slides Poster Similar