Image Defocus Analysis for Finger Detection on a Virtual Keyboard
Miwa Michio,
Honda Kenji,
Sato Makoto
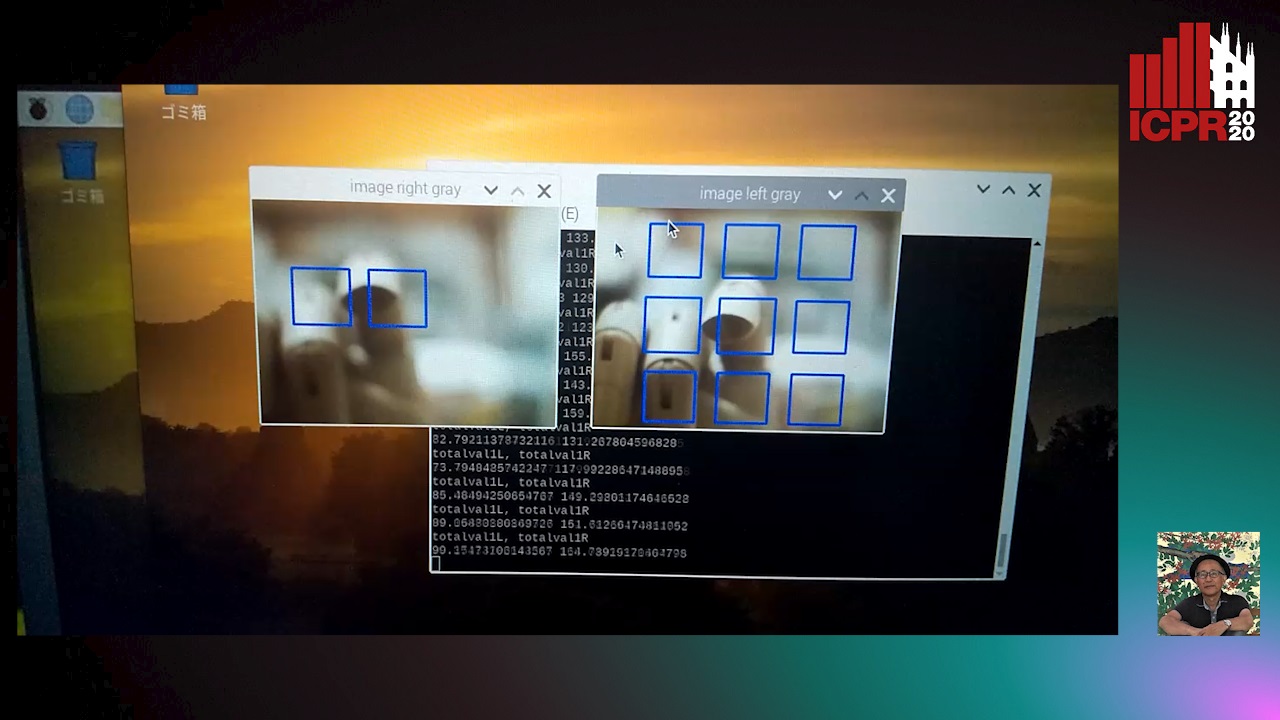
Auto-TLDR; Analysis of defocus information when a finger touching a virtual keyboard by using DCT (Discrete Cosine Transform) coefficient without detecting 3D position
Similar papers
Stabilized Calculation of Gaussian Smoothing and Its Differentials Using Attenuated Sliding Fourier Transform
Yukihiko Yamashita, Toru Wakahara

Auto-TLDR; An attenuated SFT for Gaussian smoothing
Abstract Slides Poster Similar
DCT/IDCT Filter Design for Ultrasound Image Filtering
Barmak Honarvar Shakibaei Asli, Jan Flusser, Yifan Zhao, John Ahmet Erkoyuncu, Rajkumar Roy

Auto-TLDR; Finite impulse response digital filter using DCT-II and inverse DCT
Abstract Slides Poster Similar
Calibration and Absolute Pose Estimation of Trinocular Linear Camera Array for Smart City Applications
Martin Ahrnbom, Mikael Nilsson, Håkan Ardö, Kalle Åström, Oksana Yastremska-Kravchenko, Aliaksei Laureshyn

Auto-TLDR; Trinocular Linear Camera Array Calibration for Traffic Surveillance Applications
Abstract Slides Poster Similar
Camera Calibration Using Parallel Line Segments

Auto-TLDR; Closed-Form Calibration of Surveillance Cameras using Parallel 3D Line Segment Projections
Abstract Slides Poster Similar
Generic Document Image Dewarping by Probabilistic Discretization of Vanishing Points
Gilles Simon, Salvatore Tabbone

Auto-TLDR; Robust Document Dewarping using vanishing points
Abstract Slides Poster Similar
Feasibility Study of Using MyoBand for Learning Electronic Keyboard

Auto-TLDR; Autonomous Finger-Based Music Instrument Learning using Electromyography Using MyoBand and Machine Learning
Abstract Slides Poster Similar
Extraction and Analysis of 3D Kinematic Parameters of Table Tennis Ball from a Single Camera
Jordan Calandre, Renaud Péteri, Laurent Mascarilla, Benoit Tremblais

Auto-TLDR; 3D Ball Trajectories Analysis using a Single Camera for Sport Gesture Analysis
Abstract Slides Poster Similar
Photometric Stereo with Twin-Fisheye Cameras
Jordan Caracotte, Fabio Morbidi, El Mustapha Mouaddib

Auto-TLDR; Photometric stereo problem for low-cost 360-degree cameras
Abstract Slides Poster Similar
2D Discrete Mirror Transform for Image Non-Linear Approximation
Alessandro Gnutti, Fabrizio Guerrini, Riccardo Leonardi

Auto-TLDR; Discrete Mirror Transform (DMT)
Abstract Slides Poster Similar
Rotation Detection in Finger Vein Biometrics Using CNNs
Bernhard Prommegger, Georg Wimmer, Andreas Uhl

Auto-TLDR; A CNN based rotation detector for finger vein recognition
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Computational Data Analysis for First Quantization Estimation on JPEG Double Compressed Images
Sebastiano Battiato, Oliver Giudice, Francesco Guarnera, Giovanni Puglisi

Auto-TLDR; Exploiting Discrete Cosine Transform Coefficients for Multimedia Forensics
Abstract Slides Poster Similar
Surface Material Dataset for Robotics Applications (SMDRA): A Dataset with Friction Coefficient and RGB-D for Surface Segmentation
Donghun Noh, Hyunwoo Nam, Min Sung Ahn, Hosik Chae, Sangjoon Lee, Kyle Gillespie, Dennis Hong

Auto-TLDR; A Surface Material Dataset for Robotics Applications
Abstract Slides Poster Similar
Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux, Riadh Fezzani, Jean-Christophe Olivo-Marin
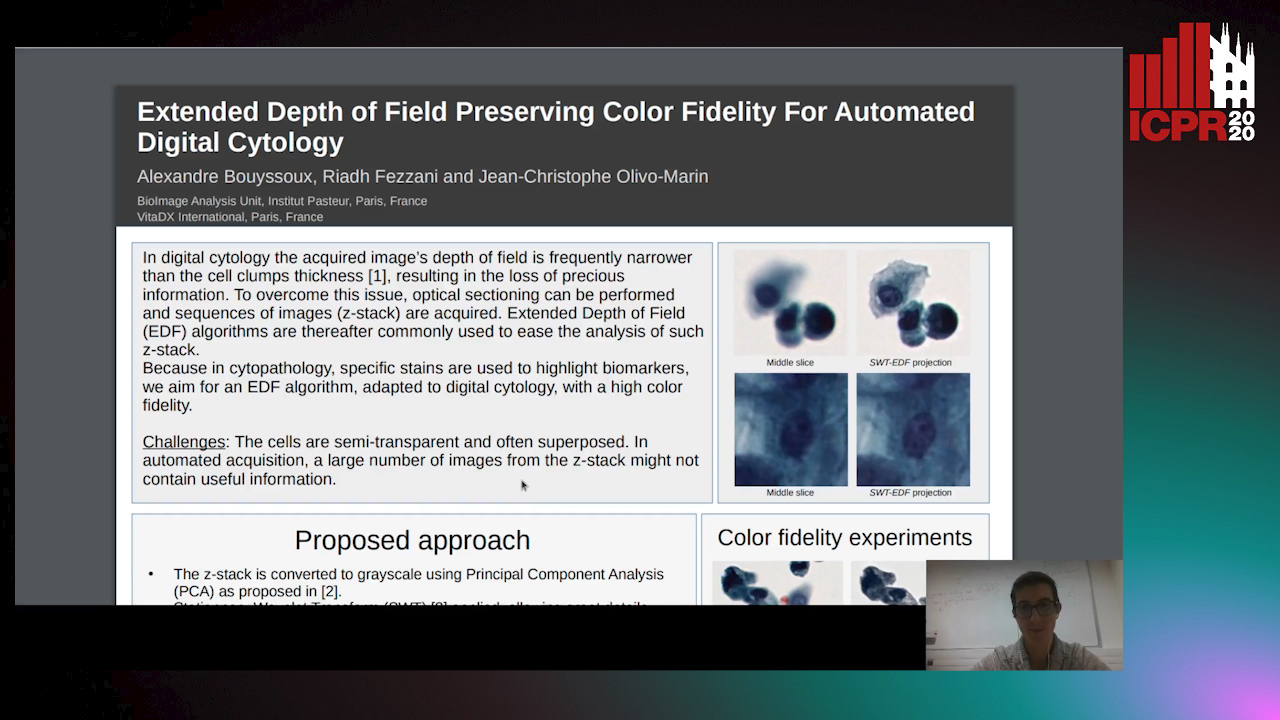
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform
Distortion-Adaptive Grape Bunch Counting for Omnidirectional Images
Ryota Akai, Yuzuko Utsumi, Yuka Miwa, Masakazu Iwamura, Koichi Kise

Auto-TLDR; Object Counting for Omnidirectional Images Using Stereographic Projection
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Air-Writing with Sparse Network of Radars Using Spatio-Temporal Learning
Muhammad Arsalan, Avik Santra, Kay Bierzynski, Vadim Issakov

Auto-TLDR; An Air-writing System for Sparse Radars using Deep Convolutional Neural Networks
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Dynamic Resource-Aware Corner Detection for Bio-Inspired Vision Sensors
Sherif Abdelmonem Sayed Mohamed, Jawad Yasin, Mohammad-Hashem Haghbayan, Antonio Miele, Jukka Veikko Heikkonen, Hannu Tenhunen, Juha Plosila

Auto-TLDR; Three Layer Filtering-Harris Algorithm for Event-based Cameras in Real-Time
A Two-Step Approach to Lidar-Camera Calibration
Yingna Su, Yaqing Ding, Jian Yang, Hui Kong

Auto-TLDR; Closed-Form Calibration of Lidar-camera System for Ego-motion Estimation and Scene Understanding
Abstract Slides Poster Similar
Benchmarking Cameras for OpenVSLAM Indoors
Kevin Chappellet, Guillaume Caron, Fumio Kanehiro, Ken Sakurada, Abderrahmane Kheddar

Auto-TLDR; OpenVSLAM: Benchmarking Camera Types for Visual Simultaneous Localization and Mapping
Abstract Slides Poster Similar
RISEdb: A Novel Indoor Localization Dataset
Carlos Sanchez Belenguer, Erik Wolfart, Álvaro Casado Coscollá, Vitor Sequeira

Auto-TLDR; Indoor Localization Using LiDAR SLAM and Smartphones: A Benchmarking Dataset
Abstract Slides Poster Similar
Estimating Gaze Points from Facial Landmarks by a Remote Spherical Camera

Auto-TLDR; Gaze Point Estimation from a Spherical Image from Facial Landmarks
Abstract Slides Poster Similar
Cost Volume Refinement for Depth Prediction
João L. Cardoso, Nuno Goncalves, Michael Wimmer

Auto-TLDR; Refining the Cost Volume for Depth Prediction from Light Field Cameras
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar
Vehicle Lane Merge Visual Benchmark

Auto-TLDR; A Benchmark for Automated Cooperative Maneuvering Using Multi-view Video Streams and Ground Truth Vehicle Description
Abstract Slides Poster Similar
Edge-Aware Monocular Dense Depth Estimation with Morphology
Zhi Li, Xiaoyang Zhu, Haitao Yu, Qi Zhang, Yongshi Jiang

Auto-TLDR; Spatio-Temporally Smooth Dense Depth Maps Using Only a CPU
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Polarimetric Image Augmentation
Marc Blanchon, Fabrice Meriaudeau, Olivier Morel, Ralph Seulin, Desire Sidibe

Auto-TLDR; Polarimetric Augmentation for Deep Learning in Robotics Applications
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
Fourier Domain Pruning of MobileNet-V2 with Application to Video Based Wildfire Detection
Hongyi Pan, Diaa Badawi, E. Cetin

Auto-TLDR; Deep Convolutional Neural Network for Wildfire Detection
Abstract Slides Poster Similar
Three-Dimensional Lip Motion Network for Text-Independent Speaker Recognition
Jianrong Wang, Tong Wu, Shanyu Wang, Mei Yu, Qiang Fang, Ju Zhang, Li Liu

Auto-TLDR; Lip Motion Network for Text-Independent and Text-Dependent Speaker Recognition
Abstract Slides Poster Similar
Generic Merging of Structure from Motion Maps with a Low Memory Footprint
Gabrielle Flood, David Gillsjö, Patrik Persson, Anders Heyden, Kalle Åström

Auto-TLDR; A Low-Memory Footprint Representation for Robust Map Merge
Abstract Slides Poster Similar
Total Estimation from RGB Video: On-Line Camera Self-Calibration, Non-Rigid Shape and Motion

Auto-TLDR; Joint Auto-Calibration, Pose and 3D Reconstruction of a Non-rigid Object from an uncalibrated RGB Image Sequence
Abstract Slides Poster Similar
Combined Invariants to Gaussian Blur and Affine Transformation
Jitka Kostkova, Jan Flusser, Matteo Pedone

Auto-TLDR; A new theory of combined moment invariants to Gaussian blur and spatial affine transformation
Abstract Slides Poster Similar
Real-Time Drone Detection and Tracking with Visible, Thermal and Acoustic Sensors
Fredrik Svanström, Cristofer Englund, Fernando Alonso-Fernandez

Auto-TLDR; Automatic multi-sensor drone detection using sensor fusion
Abstract Slides Poster Similar
Fingerprints, Forever Young?
Roman Kessler, Olaf Henniger, Christoph Busch

Auto-TLDR; Mated Similarity Scores for Fingerprint Recognition: A Hierarchical Linear Model
Abstract Slides Poster Similar
Detection and Correspondence Matching of Corneal Reflections for Eye Tracking Using Deep Learning
Soumil Chugh, Braiden Brousseau, Jonathan Rose, Moshe Eizenman

Auto-TLDR; A Fully Convolutional Neural Network for Corneal Reflection Detection and Matching in Extended Reality Eye Tracking Systems
Abstract Slides Poster Similar
On the Use of Benford's Law to Detect GAN-Generated Images
Nicolo Bonettini, Paolo Bestagini, Simone Milani, Stefano Tubaro

Auto-TLDR; Using Benford's Law to Detect GAN-generated Images from Natural Images
Abstract Slides Poster Similar
Multi-Camera Sports Players 3D Localization with Identification Reasoning
Yukun Yang, Ruiheng Zhang, Wanneng Wu, Yu Peng, Xu Min

Auto-TLDR; Probabilistic and Identified Occupancy Map for Sports Players 3D Localization
Abstract Slides Poster Similar
A Multi-Focus Image Fusion Method Based on Fractal Dimension and Guided Filtering
Nikoo Dehghani, Ehsanollah Kabir

Auto-TLDR; Fractal Dimension-based Multi-focus Image Fusion with Guide Filtering
Abstract Slides Poster Similar
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Gibran Benitez-Garcia, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; IPN Hand: A Benchmark Dataset for Continuous Hand Gesture Recognition
Abstract Slides Poster Similar
Mobile Augmented Reality: Fast, Precise, and Smooth Planar Object Tracking
Dmitrii Matveichev, Daw-Tung Lin

Auto-TLDR; Planar Object Tracking with Sparse Optical Flow Tracking and Descriptor Matching
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
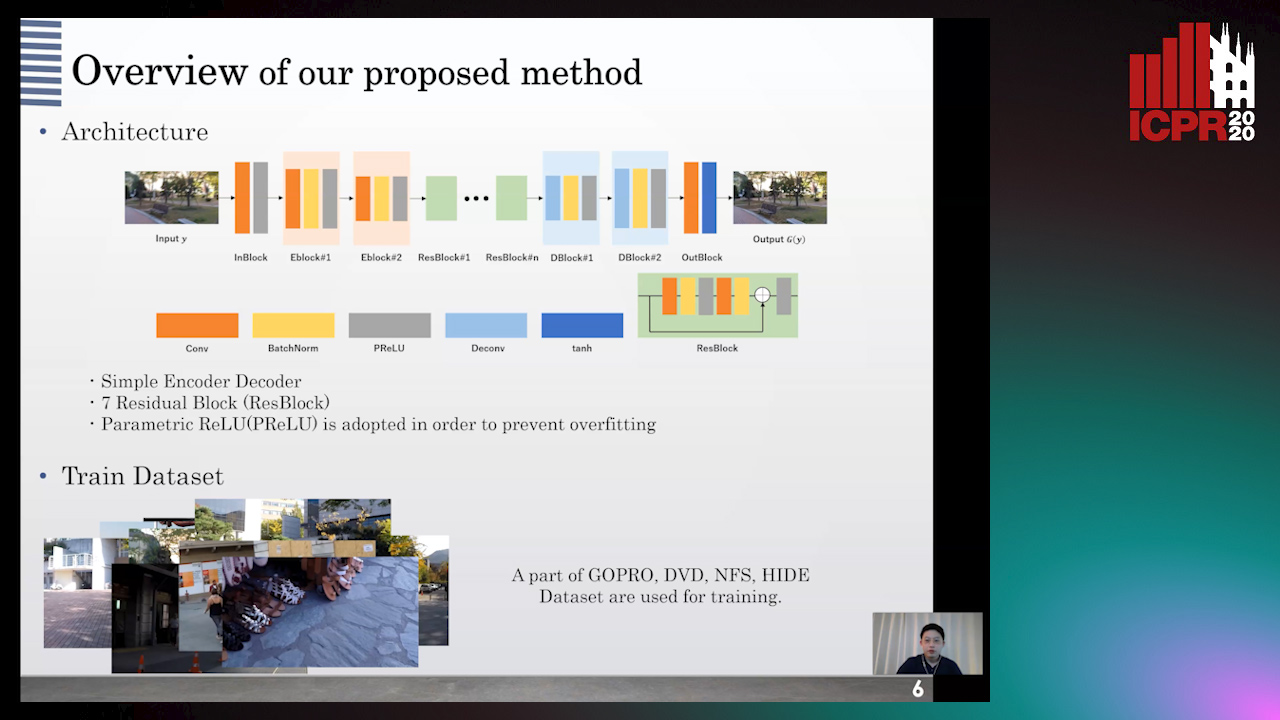
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Radar Image Reconstruction from Raw ADC Data Using Parametric Variational Autoencoder with Domain Adaptation
Michael Stephan, Thomas Stadelmayer, Avik Santra, Georg Fischer, Robert Weigel, Fabian Lurz

Auto-TLDR; Parametric Variational Autoencoder-based Human Target Detection and Localization for Frequency Modulated Continuous Wave Radar
Abstract Slides Poster Similar