Air-Writing with Sparse Network of Radars Using Spatio-Temporal Learning
Muhammad Arsalan,
Avik Santra,
Kay Bierzynski,
Vadim Issakov

Auto-TLDR; An Air-writing System for Sparse Radars using Deep Convolutional Neural Networks
Similar papers
Radar Image Reconstruction from Raw ADC Data Using Parametric Variational Autoencoder with Domain Adaptation
Michael Stephan, Thomas Stadelmayer, Avik Santra, Georg Fischer, Robert Weigel, Fabian Lurz

Auto-TLDR; Parametric Variational Autoencoder-based Human Target Detection and Localization for Frequency Modulated Continuous Wave Radar
Abstract Slides Poster Similar
CARRADA Dataset: Camera and Automotive Radar with Range-Angle-Doppler Annotations
Arthur Ouaknine, Alasdair Newson, Julien Rebut, Florence Tupin, Patrick Pérez

Auto-TLDR; CARRADA: A dataset of synchronized camera and radar recordings with range-angle-Doppler annotations for autonomous driving
Abstract Slides Poster Similar
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Online Trajectory Recovery from Offline Handwritten Japanese Kanji Characters of Multiple Strokes
Hung Tuan Nguyen, Tsubasa Nakamura, Cuong Tuan Nguyen, Masaki Nakagawa

Auto-TLDR; Recovering Dynamic Online Trajectories from Offline Japanese Kanji Character Images for Handwritten Character Recognition
Abstract Slides Poster Similar
Ghost Target Detection in 3D Radar Data Using Point Cloud Based Deep Neural Network
Mahdi Chamseddine, Jason Rambach, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; Point Based Deep Learning for Ghost Target Detection in 3D Radar Point Clouds
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Map-Based Temporally Consistent Geolocalization through Learning Motion Trajectories

Auto-TLDR; Exploiting Motion Trajectories for Geolocalization of Object on Topological Map using Recurrent Neural Network
Abstract Slides Poster Similar
Trajectory-User Link with Attention Recurrent Networks
Tao Sun, Yongjun Xu, Fei Wang, Lin Wu, 塘文 钱, Zezhi Shao

Auto-TLDR; TULAR: Trajectory-User Link with Attention Recurrent Neural Networks
Abstract Slides Poster Similar
Extraction and Analysis of 3D Kinematic Parameters of Table Tennis Ball from a Single Camera
Jordan Calandre, Renaud Péteri, Laurent Mascarilla, Benoit Tremblais

Auto-TLDR; 3D Ball Trajectories Analysis using a Single Camera for Sport Gesture Analysis
Abstract Slides Poster Similar
Transformer Networks for Trajectory Forecasting
Francesco Giuliari, Hasan Irtiza, Marco Cristani, Fabio Galasso

Auto-TLDR; TransformerNetworks for Trajectory Prediction of People Interactions
Abstract Slides Poster Similar
AV-SLAM: Autonomous Vehicle SLAM with Gravity Direction Initialization
Kaan Yilmaz, Baris Suslu, Sohini Roychowdhury, L. Srikar Muppirisetty

Auto-TLDR; VI-SLAM with AGI: A combination of three SLAM algorithms for autonomous vehicles
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
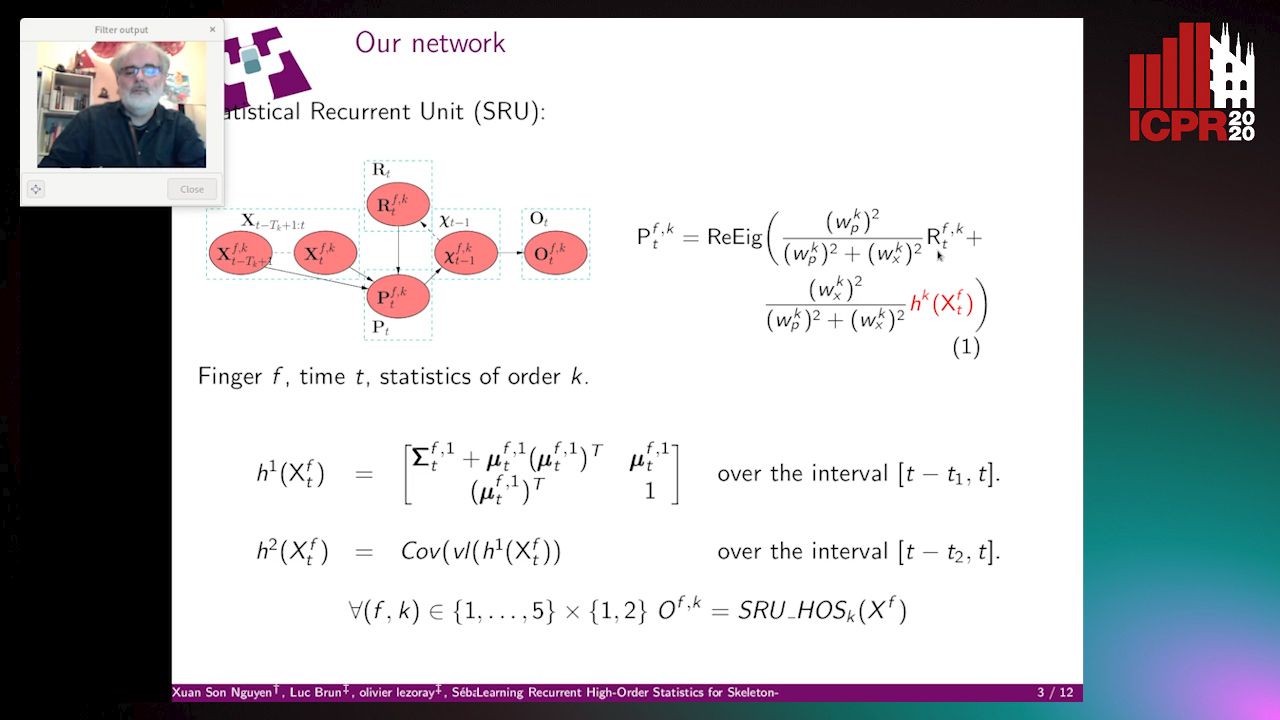
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
Exploiting the Logits: Joint Sign Language Recognition and Spell-Correction
Christina Runkel, Stefan Dorenkamp, Hartmut Bauermeister, Michael Möller

Auto-TLDR; A Convolutional Neural Network for Spell-correction in Sign Language Videos
Abstract Slides Poster Similar
A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Jinting Wu, Yujia Zhang, Xiao-Guang Zhao

Auto-TLDR; Generalized Zero-Shot Learning for Hand Gesture Recognition
Abstract Slides Poster Similar
Feasibility Study of Using MyoBand for Learning Electronic Keyboard

Auto-TLDR; Autonomous Finger-Based Music Instrument Learning using Electromyography Using MyoBand and Machine Learning
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Holistic Grid Fusion Based Stop Line Estimation
Runsheng Xu, Faezeh Tafazzoli, Li Zhang, Timo Rehfeld, Gunther Krehl, Arunava Seal

Auto-TLDR; Fused Multi-Sensory Data for Stop Lines Detection in Intersection Scenarios
Image Sequence Based Cyclist Action Recognition Using Multi-Stream 3D Convolution
Stefan Zernetsch, Steven Schreck, Viktor Kress, Konrad Doll, Bernhard Sick

Auto-TLDR; 3D-ConvNet: A Multi-stream 3D Convolutional Neural Network for Detecting Cyclists in Real World Traffic Situations
Abstract Slides Poster Similar
Self-Supervised Detection and Pose Estimation of Logistical Objects in 3D Sensor Data
Nikolas Müller, Jonas Stenzel, Jian-Jia Chen

Auto-TLDR; A self-supervised and fully automated deep learning approach for object pose estimation using simulated 3D data
Abstract Slides Poster Similar
Human or Machine? It Is Not What You Write, but How You Write It
Luis Leiva, Moises Diaz, M.A. Ferrer, Réjean Plamondon

Auto-TLDR; Behavioral Biometrics via Handwritten Symbols for Identification and Verification
Abstract Slides Poster Similar
AG-GAN: An Attentive Group-Aware GAN for Pedestrian Trajectory Prediction
Yue Song, Niccolò Bisagno, Syed Zohaib Hassan, Nicola Conci

Auto-TLDR; An attentive group-aware GAN for motion prediction in crowded scenarios
Abstract Slides Poster Similar
Translation Resilient Opportunistic WiFi Sensing
Mohammud Junaid Bocus, Wenda Li, Jonas Paulavičius, Ryan Mcconville, Raul Santos-Rodriguez, Kevin Chetty, Robert Piechocki

Auto-TLDR; Activity Recognition using Fine-Grained WiFi Channel State Information using WiFi CSI
Abstract Slides Poster Similar
Signature Features with the Visibility Transformation
Yue Wu, Hao Ni, Terry Lyons, Robin Hudson

Auto-TLDR; The Visibility Transformation for Pattern Recognition
Abstract Slides Poster Similar
Camera Calibration Using Parallel Line Segments

Auto-TLDR; Closed-Form Calibration of Surveillance Cameras using Parallel 3D Line Segment Projections
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
Motion Segmentation with Pairwise Matches and Unknown Number of Motions
Federica Arrigoni, Tomas Pajdla, Luca Magri

Auto-TLDR; Motion Segmentation using Multi-Modelfitting andpermutation synchronization
Abstract Slides Poster Similar
Conditional-UNet: A Condition-Aware Deep Model for Coherent Human Activity Recognition from Wearables
Liming Zhang, Wenbin Zhang, Nathalie Japkowicz

Auto-TLDR; Coherent Human Activity Recognition from Multi-Channel Time Series Data
Abstract Slides Poster Similar
Enhancing Handwritten Text Recognition with N-Gram Sequencedecomposition and Multitask Learning
Vasiliki Tassopoulou, George Retsinas, Petros Maragos

Auto-TLDR; Multi-task Learning for Handwritten Text Recognition
Abstract Slides Poster Similar
Learning Dictionaries of Kinematic Primitives for Action Classification
Alessia Vignolo, Nicoletta Noceti, Alessandra Sciutti, Francesca Odone, Giulio Sandini

Auto-TLDR; Action Understanding using Visual Motion Primitives
Abstract Slides Poster Similar
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Renshu Gu, Gaoang Wang, Jenq-Neng Hwang

Auto-TLDR; 3D Human Pose Estimation for Multi-Human Videos with Occlusion
Inferring Functional Properties from Fluid Dynamics Features
Andrea Schillaci, Maurizio Quadrio, Carlotta Pipolo, Marcello Restelli, Giacomo Boracchi

Auto-TLDR; Exploiting Convective Properties of Computational Fluid Dynamics for Medical Diagnosis
Abstract Slides Poster Similar
Switching Dynamical Systems with Deep Neural Networks
Cesar Ali Ojeda Marin, Kostadin Cvejoski, Bogdan Georgiev, Ramses J. Sanchez

Auto-TLDR; Variational RNN for Switching Dynamics
Abstract Slides Poster Similar
Feature Extraction by Joint Robust Discriminant Analysis and Inter-Class Sparsity

Auto-TLDR; Robust Discriminant Analysis with Feature Selection and Inter-class Sparsity (RDA_FSIS)
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
Recursive Recognition of Offline Handwritten Mathematical Expressions
Marco Cotogni, Claudio Cusano, Antonino Nocera

Auto-TLDR; Online Handwritten Mathematical Expression Recognition with Recurrent Neural Network
Abstract Slides Poster Similar
Total Estimation from RGB Video: On-Line Camera Self-Calibration, Non-Rigid Shape and Motion

Auto-TLDR; Joint Auto-Calibration, Pose and 3D Reconstruction of a Non-rigid Object from an uncalibrated RGB Image Sequence
Abstract Slides Poster Similar
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
Dimensionality Reduction for Data Visualization and Linear Classification, and the Trade-Off between Robustness and Classification Accuracy
Martin Becker, Jens Lippel, Thomas Zielke

Auto-TLDR; Robustness Assessment of Deep Autoencoder for Data Visualization using Scatter Plots
Abstract Slides Poster Similar
Real-Time Drone Detection and Tracking with Visible, Thermal and Acoustic Sensors
Fredrik Svanström, Cristofer Englund, Fernando Alonso-Fernandez

Auto-TLDR; Automatic multi-sensor drone detection using sensor fusion
Abstract Slides Poster Similar
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
RISEdb: A Novel Indoor Localization Dataset
Carlos Sanchez Belenguer, Erik Wolfart, Álvaro Casado Coscollá, Vitor Sequeira

Auto-TLDR; Indoor Localization Using LiDAR SLAM and Smartphones: A Benchmarking Dataset
Abstract Slides Poster Similar
Single-Modal Incremental Terrain Clustering from Self-Supervised Audio-Visual Feature Learning
Reina Ishikawa, Ryo Hachiuma, Akiyoshi Kurobe, Hideo Saito

Auto-TLDR; Multi-modal Variational Autoencoder for Terrain Type Clustering
Abstract Slides Poster Similar
Fall Detection by Human Pose Estimation and Kinematic Theory
Vincenzo Dentamaro, Donato Impedovo, Giuseppe Pirlo

Auto-TLDR; A Decision Support System for Automatic Fall Detection on Le2i and URFD Datasets
Abstract Slides Poster Similar
Rotational Adjoint Methods for Learning-Free 3D Human Pose Estimation from IMU Data
Caterina Emilia Agelide Buizza, Yiannis Demiris

Auto-TLDR; Learning-free 3D Human Pose Estimation from Inertial Measurement Unit Data
Single View Learning in Action Recognition
Gaurvi Goyal, Nicoletta Noceti, Francesca Odone

Auto-TLDR; Cross-View Action Recognition Using Domain Adaptation for Knowledge Transfer
Abstract Slides Poster Similar