From Human Pose to On-Body Devices for Human-Activity Recognition
Fernando Moya Rueda,
Gernot Fink
Auto-TLDR; Transfer Learning from Human Pose Estimation for Human Activity Recognition using Inertial Measurements from On-Body Devices
Similar papers
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
Conditional-UNet: A Condition-Aware Deep Model for Coherent Human Activity Recognition from Wearables
Liming Zhang, Wenbin Zhang, Nathalie Japkowicz

Auto-TLDR; Coherent Human Activity Recognition from Multi-Channel Time Series Data
Abstract Slides Poster Similar
Pose-Based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Zhengyuan Yang, Amanda Kay, Yuncheng Li, Wendi Cross, Jiebo Luo

Auto-TLDR; Body Language Based Emotion Recognition for Psychiatric Symptoms Prediction
Abstract Slides Poster Similar
Anticipating Activity from Multimodal Signals
Tiziana Rotondo, Giovanni Maria Farinella, Davide Giacalone, Sebastiano Mauro Strano, Valeria Tomaselli, Sebastiano Battiato

Auto-TLDR; Exploiting Multimodal Signal Embedding Space for Multi-Action Prediction
Abstract Slides Poster Similar
Vision-Based Multi-Modal Framework for Action Recognition
Djamila Romaissa Beddiar, Mourad Oussalah, Brahim Nini

Auto-TLDR; Multi-modal Framework for Human Activity Recognition Using RGB, Depth and Skeleton Data
Abstract Slides Poster Similar
Attention-Driven Body Pose Encoding for Human Activity Recognition
Bappaditya Debnath, Swagat Kumar, Marry O'Brien, Ardhendu Behera

Auto-TLDR; Attention-based Body Pose Encoding for Human Activity Recognition
Abstract Slides Poster Similar
A Detection-Based Approach to Multiview Action Classification in Infants
Carolina Pacheco, Effrosyni Mavroudi, Elena Kokkoni, Herbert Tanner, Rene Vidal

Auto-TLDR; Multiview Action Classification for Infants in a Pediatric Rehabilitation Environment
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Rotational Adjoint Methods for Learning-Free 3D Human Pose Estimation from IMU Data
Caterina Emilia Agelide Buizza, Yiannis Demiris

Auto-TLDR; Learning-free 3D Human Pose Estimation from Inertial Measurement Unit Data
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
Single View Learning in Action Recognition
Gaurvi Goyal, Nicoletta Noceti, Francesca Odone

Auto-TLDR; Cross-View Action Recognition Using Domain Adaptation for Knowledge Transfer
Abstract Slides Poster Similar
Translation Resilient Opportunistic WiFi Sensing
Mohammud Junaid Bocus, Wenda Li, Jonas Paulavičius, Ryan Mcconville, Raul Santos-Rodriguez, Kevin Chetty, Robert Piechocki

Auto-TLDR; Activity Recognition using Fine-Grained WiFi Channel State Information using WiFi CSI
Abstract Slides Poster Similar
Activity Recognition Using First-Person-View Cameras Based on Sparse Optical Flows
Peng-Yuan Kao, Yan-Jing Lei, Chia-Hao Chang, Chu-Song Chen, Ming-Sui Lee, Yi-Ping Hung

Auto-TLDR; 3D Convolutional Neural Network for Activity Recognition with FPV Videos
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
SL-DML: Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Raphael Memmesheimer, Nick Theisen, Dietrich Paulus

Auto-TLDR; One-Shot Action Recognition using Metric Learning
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
3D Attention Mechanism for Fine-Grained Classification of Table Tennis Strokes Using a Twin Spatio-Temporal Convolutional Neural Networks
Pierre-Etienne Martin, Jenny Benois-Pineau, Renaud Péteri, Julien Morlier

Auto-TLDR; Attentional Blocks for Action Recognition in Table Tennis Strokes
Abstract Slides Poster Similar
RefiNet: 3D Human Pose Refinement with Depth Maps
Andrea D'Eusanio, Stefano Pini, Guido Borghi, Roberto Vezzani, Rita Cucchiara

Auto-TLDR; RefiNet: A Multi-stage Framework for 3D Human Pose Estimation
Late Fusion of Bayesian and Convolutional Models for Action Recognition
Camille Maurice, Francisco Madrigal, Frederic Lerasle

Auto-TLDR; Fusion of Deep Neural Network and Bayesian-based Approach for Temporal Action Recognition
Abstract Slides Poster Similar
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
Extracting Action Hierarchies from Action Labels and their Use in Deep Action Recognition
Konstadinos Bacharidis, Antonis Argyros

Auto-TLDR; Exploiting the Information Content of Language Label Associations for Human Action Recognition
Abstract Slides Poster Similar
Feature-Supervised Action Modality Transfer
Fida Mohammad Thoker, Cees Snoek

Auto-TLDR; Cross-Modal Action Recognition and Detection in Non-RGB Video Modalities by Learning from Large-Scale Labeled RGB Data
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
IPT: A Dataset for Identity Preserved Tracking in Closed Domains
Thomas Heitzinger, Martin Kampel

Auto-TLDR; Identity Preserved Tracking Using Depth Data for Privacy and Privacy
Abstract Slides Poster Similar
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Gibran Benitez-Garcia, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; IPN Hand: A Benchmark Dataset for Continuous Hand Gesture Recognition
Abstract Slides Poster Similar
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar
Exploiting the Logits: Joint Sign Language Recognition and Spell-Correction
Christina Runkel, Stefan Dorenkamp, Hartmut Bauermeister, Michael Möller

Auto-TLDR; A Convolutional Neural Network for Spell-correction in Sign Language Videos
Abstract Slides Poster Similar
ESResNet: Environmental Sound Classification Based on Visual Domain Models
Andrey Guzhov, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Environmental Sound Classification with Short-Time Fourier Transform Spectrograms
Abstract Slides Poster Similar
LFIR2Pose: Pose Estimation from an Extremely Low-Resolution FIR Image Sequence
Saki Iwata, Yasutomo Kawanishi, Daisuke Deguchi, Ichiro Ide, Hiroshi Murase, Tomoyoshi Aizawa

Auto-TLDR; LFIR2Pose: Human Pose Estimation from a Low-Resolution Far-InfraRed Image Sequence
Abstract Slides Poster Similar
Learning Group Activities from Skeletons without Individual Action Labels
Fabio Zappardino, Tiberio Uricchio, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Lean Pose Only for Group Activity Recognition
Human or Machine? It Is Not What You Write, but How You Write It
Luis Leiva, Moises Diaz, M.A. Ferrer, Réjean Plamondon

Auto-TLDR; Behavioral Biometrics via Handwritten Symbols for Identification and Verification
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
A Two-Stream Recurrent Network for Skeleton-Based Human Interaction Recognition
Qianhui Men, Edmond S. L. Ho, Shum Hubert P. H., Howard Leung

Auto-TLDR; Two-Stream Recurrent Neural Network for Human-Human Interaction Recognition
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Relevance Detection in Cataract Surgery Videos by Spatio-Temporal Action Localization
Negin Ghamsarian, Mario Taschwer, Doris Putzgruber, Stephanie. Sarny, Klaus Schoeffmann

Auto-TLDR; relevance-based retrieval in cataract surgery videos
Lightweight Low-Resolution Face Recognition for Surveillance Applications
Yoanna Martínez-Díaz, Heydi Mendez-Vazquez, Luis S. Luevano, Leonardo Chang, Miguel Gonzalez-Mendoza

Auto-TLDR; Efficiency of Lightweight Deep Face Networks on Low-Resolution Surveillance Imagery
Abstract Slides Poster Similar
Extracting and Interpreting Unknown Factors with Classifier for Foot Strike Types in Running
Chanjin Seo, Masato Sabanai, Yuta Goto, Koji Tagami, Hiroyuki Ogata, Kazuyuki Kanosue, Jun Ohya

Auto-TLDR; Deep Learning for Foot Strike Classification using Accelerometer Data
Abstract Slides Poster Similar
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
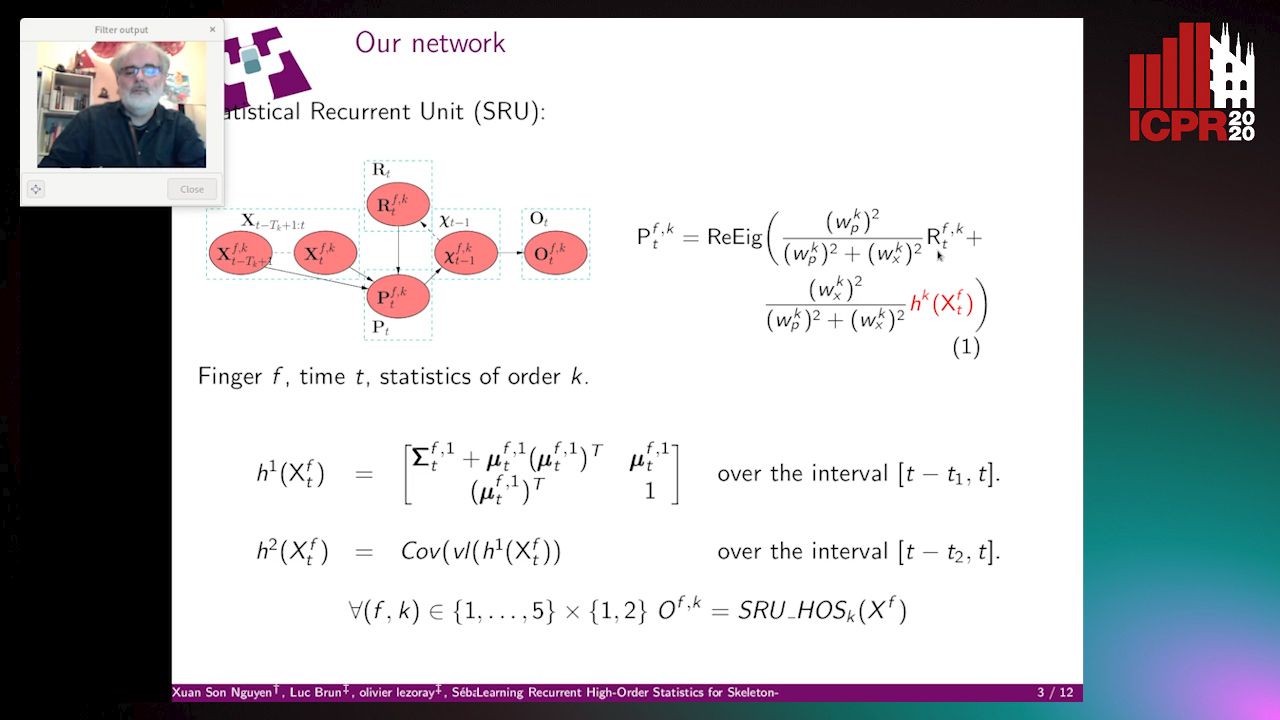
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
JT-MGCN: Joint-Temporal Motion Graph Convolutional Network for Skeleton-Based Action Recognition

Auto-TLDR; Joint-temporal Motion Graph Convolutional Networks for Action Recognition
Fall Detection by Human Pose Estimation and Kinematic Theory
Vincenzo Dentamaro, Donato Impedovo, Giuseppe Pirlo

Auto-TLDR; A Decision Support System for Automatic Fall Detection on Le2i and URFD Datasets
Abstract Slides Poster Similar
Learning Dictionaries of Kinematic Primitives for Action Classification
Alessia Vignolo, Nicoletta Noceti, Alessandra Sciutti, Francesca Odone, Giulio Sandini

Auto-TLDR; Action Understanding using Visual Motion Primitives
Abstract Slides Poster Similar
Radar Image Reconstruction from Raw ADC Data Using Parametric Variational Autoencoder with Domain Adaptation
Michael Stephan, Thomas Stadelmayer, Avik Santra, Georg Fischer, Robert Weigel, Fabian Lurz

Auto-TLDR; Parametric Variational Autoencoder-based Human Target Detection and Localization for Frequency Modulated Continuous Wave Radar
Abstract Slides Poster Similar
Knowledge Distillation for Action Anticipation Via Label Smoothing
Guglielmo Camporese, Pasquale Coscia, Antonino Furnari, Giovanni Maria Farinella, Lamberto Ballan

Auto-TLDR; A Multi-Modal Framework for Action Anticipation using Long Short-Term Memory Networks
Abstract Slides Poster Similar
Location Prediction in Real Homes of Older Adults based on K-Means in Low-Resolution Depth Videos
Simon Simonsson, Flávia Dias Casagrande, Evi Zouganeli

Auto-TLDR; Semi-supervised Learning for Location Recognition and Prediction in Smart Homes using Depth Video Cameras
Abstract Slides Poster Similar