XGBoost to Interpret the Opioid Patients’ StateBased on Cognitive and Physiological Measures
Arash Shokouhmand,
Omid Dehzangi,
Jad Ramadan,
Victor Finomore,
Nasser M. Nasarabadi,
Ali Rezai
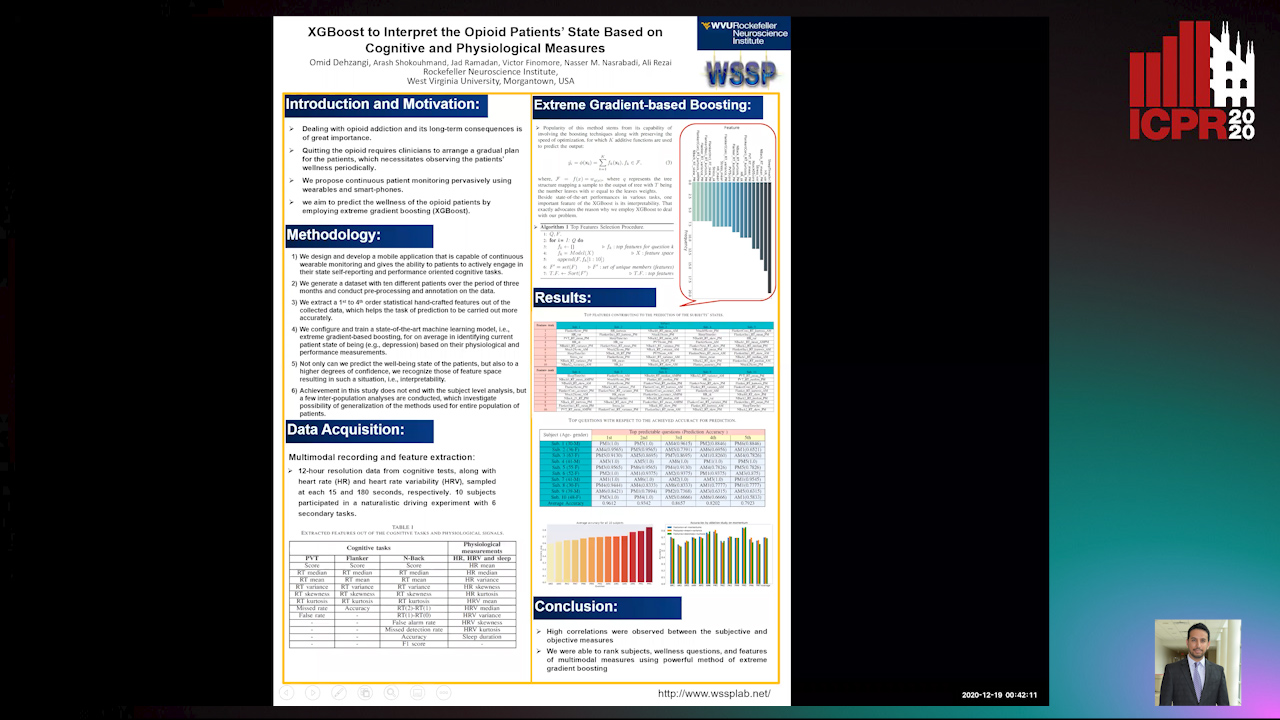
Auto-TLDR; Predicting the Wellness of Opioid Addictions Using Multi-modal Sensor Data
Similar papers
Deep Learning Based Sepsis Intervention: The Modelling and Prediction of Severe Sepsis Onset

Auto-TLDR; Predicting Sepsis onset by up to six hours prior using a boosted cascading training methodology and adjustable margin hinge loss function
Abstract Slides Poster Similar
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Video Analytics Gait Trend Measurement for Fall Prevention and Health Monitoring
Lawrence O'Gorman, Xinyi Liu, Md Imran Sarker, Mariofanna Milanova

Auto-TLDR; Towards Health Monitoring of Gait with Deep Learning
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Quantified Facial Temporal-Expressiveness Dynamics for Affect Analysis
Md Taufeeq Uddin, Shaun Canavan

Auto-TLDR; quantified facial Temporal-expressiveness Dynamics for quantified affect analysis
Location Prediction in Real Homes of Older Adults based on K-Means in Low-Resolution Depth Videos
Simon Simonsson, Flávia Dias Casagrande, Evi Zouganeli

Auto-TLDR; Semi-supervised Learning for Location Recognition and Prediction in Smart Homes using Depth Video Cameras
Abstract Slides Poster Similar
A General End-To-End Method for Characterizing Neuropsychiatric Disorders Using Free-Viewing Visual Scanning Tasks
Hong Yue Sean Liu, Jonathan Chung, Moshe Eizenman

Auto-TLDR; A general, data-driven, end-to-end framework that extracts relevant features of attentional bias from visual scanning behaviour and uses these features
Abstract Slides Poster Similar
A Low-Complexity R-Peak Detection Algorithm with Adaptive Thresholding for Wearable Devices
Tiago Rodrigues, Hugo Plácido Da Silva, Ana Luisa Nobre Fred, Sirisack Samoutphonh

Auto-TLDR; Real-Time and Low-Complexity R-peak Detection for Single Lead ECG Signals
Abstract Slides Poster Similar
Tensor Factorization of Brain Structural Graph for Unsupervised Classification in Multiple Sclerosis
Berardino Barile, Marzullo Aldo, Claudio Stamile, Françoise Durand-Dubief, Dominique Sappey-Marinier

Auto-TLDR; A Fully Automated Tensor-based Algorithm for Multiple Sclerosis Classification based on Structural Connectivity Graph of the White Matter Network
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Assessing the Severity of Health States Based on Social Media Posts
Shweta Yadav, Joy Prakash Sain, Amit Sheth, Asif Ekbal, Sriparna Saha, Pushpak Bhattacharyya

Auto-TLDR; A Multiview Learning Framework for Assessment of Health State in Online Health Communities
Abstract Slides Poster Similar
Using Machine Learning to Refer Patients with Chronic Kidney Disease to Secondary Care
Lee Au-Yeung, Xianghua Xie, Timothy Marcus Scale, James Anthony Chess

Auto-TLDR; A Machine Learning Approach for Chronic Kidney Disease Prediction using Blood Test Data
Abstract Slides Poster Similar
Epileptic Seizure Prediction: A Semi-Dilated Convolutional Neural Network Architecture
Ramy Hussein, Rabab K. Ward, Soojin Lee, Martin Mckeown

Auto-TLDR; Semi-Dilated Convolutional Network for Seizure Prediction using EEG Scalograms
Can Reinforcement Learning Lead to Healthy Life?: Simulation Study Based on User Activity Logs
Masami Takahashi, Masahiro Kohjima, Takeshi Kurashima, Hiroyuki Toda

Auto-TLDR; Reinforcement Learning for Healthy Daily Life
Abstract Slides Poster Similar
Algorithm Recommendation for Data Streams
Jáder Martins Camboim De Sá, Andre Luis Debiaso Rossi, Gustavo Enrique De Almeida Prado Alves Batista, Luís Paulo Faina Garcia

Auto-TLDR; Meta-Learning for Algorithm Selection in Time-Changing Data Streams
Abstract Slides Poster Similar
Automatic Classification of Human Granulosa Cells in Assisted Reproductive Technology Using Vibrational Spectroscopy Imaging
Marina Paolanti, Emanuele Frontoni, Giorgia Gioacchini, Giorgini Elisabetta, Notarstefano Valentina, Zacà Carlotta, Carnevali Oliana, Andrea Borini, Marco Mameli

Auto-TLDR; Predicting Oocyte Quality in Assisted Reproductive Technology Using Machine Learning Techniques
Abstract Slides Poster Similar
EEG-Based Cognitive State Assessment Using Deep Ensemble Model and Filter Bank Common Spatial Pattern
Debashis Das Chakladar, Shubhashis Dey, Partha Pratim Roy, Masakazu Iwamura

Auto-TLDR; A Deep Ensemble Model for Cognitive State Assessment using EEG-based Cognitive State Analysis
Abstract Slides Poster Similar
Deep Transfer Learning for Alzheimer’s Disease Detection
Nicole Cilia, Claudio De Stefano, Francesco Fontanella, Claudio Marrocco, Mario Molinara, Alessandra Scotto Di Freca

Auto-TLDR; Automatic Detection of Handwriting Alterations for Alzheimer's Disease Diagnosis using Dynamic Features
Abstract Slides Poster Similar
Fingerprints, Forever Young?
Roman Kessler, Olaf Henniger, Christoph Busch

Auto-TLDR; Mated Similarity Scores for Fingerprint Recognition: A Hierarchical Linear Model
Abstract Slides Poster Similar
Prediction of Obstructive Coronary Artery Disease from Myocardial Perfusion Scintigraphy using Deep Neural Networks
Ida Arvidsson, Niels Christian Overgaard, Miguel Ochoa Figueroa, Jeronimo Rose, Anette Davidsson, Kalle Åström, Anders Heyden

Auto-TLDR; A Deep Learning Algorithm for Multi-label Classification of Myocardial Perfusion Scintigraphy for Stable Ischemic Heart Disease
Abstract Slides Poster Similar
Dealing with Scarce Labelled Data: Semi-Supervised Deep Learning with Mix Match for Covid-19 Detection Using Chest X-Ray Images
Saúl Calderón Ramirez, Raghvendra Giri, Shengxiang Yang, Armaghan Moemeni, Mario Umaña, David Elizondo, Jordina Torrents-Barrena, Miguel A. Molina-Cabello

Auto-TLDR; Semi-supervised Deep Learning for Covid-19 Detection using Chest X-rays
Abstract Slides Poster Similar
Classifying Eye-Tracking Data Using Saliency Maps
Shafin Rahman, Sejuti Rahman, Omar Shahid, Md. Tahmeed Abdullah, Jubair Ahmed Sourov

Auto-TLDR; Saliency-based Feature Extraction for Automatic Classification of Eye-tracking Data
Abstract Slides Poster Similar
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
Fall Detection by Human Pose Estimation and Kinematic Theory
Vincenzo Dentamaro, Donato Impedovo, Giuseppe Pirlo

Auto-TLDR; A Decision Support System for Automatic Fall Detection on Le2i and URFD Datasets
Abstract Slides Poster Similar
Extracting and Interpreting Unknown Factors with Classifier for Foot Strike Types in Running
Chanjin Seo, Masato Sabanai, Yuta Goto, Koji Tagami, Hiroyuki Ogata, Kazuyuki Kanosue, Jun Ohya

Auto-TLDR; Deep Learning for Foot Strike Classification using Accelerometer Data
Abstract Slides Poster Similar
Using Meta Labels for the Training of Weighting Models in a Sample-Specific Late Fusion Classification Architecture
Peter Bellmann, Patrick Thiam, Friedhelm Schwenker

Auto-TLDR; A Late Fusion Architecture for Multiple Classifier Systems
Abstract Slides Poster Similar
Detecting Rare Cell Populations in Flow Cytometry Data Using UMAP
Lisa Weijler, Markus Diem, Michael Reiter

Auto-TLDR; Unsupervised Manifold Approximation and Projection for Small Cell Population Detection in Flow cytometry Data
Abstract Slides Poster Similar
A Lumen Segmentation Method in Ureteroscopy Images Based on a Deep Residual U-Net Architecture
Jorge Lazo, Marzullo Aldo, Sara Moccia, Michele Catellani, Benoit Rosa, Elena De Momi, Michel De Mathelin, Francesco Calimeri

Auto-TLDR; A Deep Neural Network for Ureteroscopy with Residual Units
Abstract Slides Poster Similar
Attack-Agnostic Adversarial Detection on Medical Data Using Explainable Machine Learning
Matthew Watson, Noura Al Moubayed

Auto-TLDR; Explainability-based Detection of Adversarial Samples on EHR and Chest X-Ray Data
Abstract Slides Poster Similar
EasiECG: A Novel Inter-Patient Arrhythmia Classification Method Using ECG Waves
Chuanqi Han, Ruoran Huang, Fang Yu, Xi Huang, Li Cui

Auto-TLDR; EasiECG: Attention-based Convolution Factorization Machines for Arrhythmia Classification
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
VR Sickness Assessment with Perception Prior and Hybrid Temporal Features
Po-Chen Kuo, Li-Chung Chuang, Dong-Yi Lin, Ming-Sui Lee

Auto-TLDR; A novel content-based VR sickness assessment method which considers both the perception prior and hybrid temporal features
Abstract Slides Poster Similar
A Systematic Investigation on Deep Architectures for Automatic Skin Lesions Classification
Pierluigi Carcagni, Marco Leo, Andrea Cuna, Giuseppe Celeste, Cosimo Distante

Auto-TLDR; RegNet: Deep Investigation of Convolutional Neural Networks for Automatic Classification of Skin Lesions
Abstract Slides Poster Similar
How to Define a Rejection Class Based on Model Learning?
Sarah Laroui, Xavier Descombes, Aurelia Vernay, Florent Villiers, Francois Villalba, Eric Debreuve

Auto-TLDR; An innovative learning strategy for supervised classification that is able, by design, to reject a sample as not belonging to any of the known classes
Abstract Slides Poster Similar
Influence of Event Duration on Automatic Wheeze Classification
Bruno M Rocha, Diogo Pessoa, Alda Marques, Paulo Carvalho, Rui Pedro Paiva

Auto-TLDR; Experimental Design of the Non-wheeze Class for Wheeze Classification
Abstract Slides Poster Similar
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
Explainable Online Validation of Machine Learning Models for Practical Applications
Wolfgang Fuhl, Yao Rong, Thomas Motz, Michael Scheidt, Andreas Markus Hartel, Andreas Koch, Enkelejda Kasneci

Auto-TLDR; A Reformulation of Regression and Classification for Machine Learning Algorithm Validation
Abstract Slides Poster Similar
A Deep Learning-Based Method for Predicting Volumes of Nasopharyngeal Carcinoma for Adaptive Radiation Therapy Treatment
Bilel Daoud, Ken'Ichi Morooka, Shoko Miyauchi, Ryo Kurazume, Wafa Mnejja, Leila Farhat, Jamel Daoud

Auto-TLDR; TEP-Net: Tumor Evolution Prediction of Nasopharyngeal Carcinoma and Organ-at-risks Using CT Images
Abstract Slides Poster Similar
Estimation of Clinical Tremor Using Spatio-Temporal Adversarial AutoEncoder
Li Zhang, Vidya Koesmahargyo, Isaac Galatzer-Levy

Auto-TLDR; ST-AAE: Spatio-temporal Adversarial Autoencoder for Clinical Assessment of Hand Tremor Frequency and Severity
Abstract Slides Poster Similar
PIF: Anomaly detection via preference embedding
Filippo Leveni, Luca Magri, Giacomo Boracchi, Cesare Alippi

Auto-TLDR; PIF: Anomaly Detection with Preference Embedding for Structured Patterns
Abstract Slides Poster Similar
Inferring Functional Properties from Fluid Dynamics Features
Andrea Schillaci, Maurizio Quadrio, Carlotta Pipolo, Marcello Restelli, Giacomo Boracchi

Auto-TLDR; Exploiting Convective Properties of Computational Fluid Dynamics for Medical Diagnosis
Abstract Slides Poster Similar
A Versatile Crack Inspection Portable System Based on Classifier Ensemble and Controlled Illumination
Milind Gajanan Padalkar, Carlos Beltran-Gonzalez, Matteo Bustreo, Alessio Del Bue, Vittorio Murino

Auto-TLDR; Lighting Conditions for Crack Detection in Ceramic Tile
Abstract Slides Poster Similar
Creating Classifier Ensembles through Meta-Heuristic Algorithms for Aerial Scene Classification
Álvaro Roberto Ferreira Jr., Gustavo Gustavo Henrique De Rosa, Joao Paulo Papa, Gustavo Carneiro, Fabio Augusto Faria

Auto-TLDR; Univariate Marginal Distribution Algorithm for Aerial Scene Classification Using Meta-Heuristic Optimization
Abstract Slides Poster Similar
Real-Time Driver Drowsiness Detection Using Facial Action Units
Malaika Vijay, Nandagopal Netrakanti Vinayak, Maanvi Nunna, Subramanyam Natarajan

Auto-TLDR; Real-Time Detection of Driver Drowsiness using Facial Action Units using Extreme Gradient Boosting
Abstract Slides Poster Similar
BAT Optimized CNN Model Identifies Water Stress in Chickpea Plant Shoot Images
Shiva Azimi, Taranjit Kaur, Tapan Gandhi

Auto-TLDR; BAT Optimized ResNet-18 for Stress Classification of chickpea shoot images under water deficiency
Abstract Slides Poster Similar
Dual-Memory Model for Incremental Learning: The Handwriting Recognition Use Case
Mélanie Piot, Bérangère Bourdoulous, Aurelia Deshayes, Lionel Prevost

Auto-TLDR; A dual memory model for handwriting recognition
Handwritten Signature and Text Based User Verification Using Smartwatch
Raghavendra Ramachandra, Sushma Venkatesh, Raja Kiran, Christoph Busch
Auto-TLDR; A novel technique for user verification using a smartwatch based on writing pattern or signing pattern
Abstract Slides Poster Similar