An Intelligent Photographing Guidance System Based on Compositional Deep Features and Intepretable Machine Learning Model
Chin-Shyurng Fahn,
Meng-Luen Wu,
Sheng-Kuei Tsau

Auto-TLDR; Photography Guidance Using Interpretable Machine Learning
Similar papers
A Heuristic-Based Decision Tree for Connected Components Labeling of 3D Volumes
Maximilian Söchting, Stefano Allegretti, Federico Bolelli, Costantino Grana

Auto-TLDR; Entropy Partitioning Decision Tree for Connected Components Labeling
Abstract Slides Poster Similar
Merged 1D-2D Deep Convolutional Neural Networks for Nerve Detection in Ultrasound Images
Mohammad Alkhatib, Adel Hafiane, Pierre Vieyres

Auto-TLDR; A Deep Neural Network for Deep Neural Networks to Detect Median Nerve in Ultrasound-Guided Regional Anesthesia
Abstract Slides Poster Similar
CNN-Based Repetitive Self-Revised Learning for Photos’ Aesthetics Imbalanced Classification

Auto-TLDR; Automatic Aesthetic Assessment Using Recurrent Self-revised Learning
Color, Edge, and Pixel-Wise Explanation of Predictions Based onInterpretable Neural Network Model

Auto-TLDR; Explainable Deep Neural Network with Edge Detecting Filters
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Image Representation Learning by Transformation Regression
Xifeng Guo, Jiyuan Liu, Sihang Zhou, En Zhu, Shihao Dong

Auto-TLDR; Self-supervised Image Representation Learning using Continuous Parameter Prediction
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
MFPP: Morphological Fragmental Perturbation Pyramid for Black-Box Model Explanations
Qing Yang, Xia Zhu, Jong-Kae Fwu, Yun Ye, Ganmei You, Yuan Zhu

Auto-TLDR; Morphological Fragmental Perturbation Pyramid for Explainable Deep Neural Network
Abstract Slides Poster Similar
Explainable Online Validation of Machine Learning Models for Practical Applications
Wolfgang Fuhl, Yao Rong, Thomas Motz, Michael Scheidt, Andreas Markus Hartel, Andreas Koch, Enkelejda Kasneci

Auto-TLDR; A Reformulation of Regression and Classification for Machine Learning Algorithm Validation
Abstract Slides Poster Similar
Classifying Eye-Tracking Data Using Saliency Maps
Shafin Rahman, Sejuti Rahman, Omar Shahid, Md. Tahmeed Abdullah, Jubair Ahmed Sourov

Auto-TLDR; Saliency-based Feature Extraction for Automatic Classification of Eye-tracking Data
Abstract Slides Poster Similar
Saliency Prediction on Omnidirectional Images with Brain-Like Shallow Neural Network
Zhu Dandan, Chen Yongqing, Min Xiongkuo, Zhao Defang, Zhu Yucheng, Zhou Qiangqiang, Yang Xiaokang, Tian Han

Auto-TLDR; A Brain-like Neural Network for Saliency Prediction of Head Fixations on Omnidirectional Images
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
Coarse to Fine: Progressive and Multi-Task Learning for Salient Object Detection
Dong-Goo Kang, Sangwoo Park, Joonki Paik

Auto-TLDR; Progressive and mutl-task learning scheme for salient object detection
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
Lane Detection Based on Object Detection and Image-To-Image Translation
Hiroyuki Komori, Kazunori Onoguchi

Auto-TLDR; Lane Marking and Road Boundary Detection from Monocular Camera Images using Inverse Perspective Mapping
Abstract Slides Poster Similar
Dynamic Low-Light Image Enhancement for Object Detection Via End-To-End Training
Haifeng Guo, Yirui Wu, Tong Lu

Auto-TLDR; Object Detection using Low-Light Image Enhancement for End-to-End Training
Abstract Slides Poster Similar
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
Mobile Phone Surface Defect Detection Based on Improved Faster R-CNN
Tao Wang, Can Zhang, Runwei Ding, Ge Yang

Auto-TLDR; Faster R-CNN for Mobile Phone Surface Defect Detection
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Enhancing Deep Semantic Segmentation of RGB-D Data with Entangled Forests
Matteo Terreran, Elia Bonetto, Stefano Ghidoni

Auto-TLDR; FuseNet: A Lighter Deep Learning Model for Semantic Segmentation
Abstract Slides Poster Similar
Malware Detection by Exploiting Deep Learning over Binary Programs
Panpan Qi, Zhaoqi Zhang, Wei Wang, Chang Yao

Auto-TLDR; End-to-End Malware Detection without Feature Engineering
Abstract Slides Poster Similar
Responsive Social Smile: A Machine-Learning Based Multimodal Behavior Assessment Framework towards Early Stage Autism Screening
Yueran Pan, Kunjing Cai, Ming Cheng, Xiaobing Zou, Ming Li

Auto-TLDR; Responsive Social Smile: A Machine Learningbased Assessment Framework for Early ASD Screening
Face Anti-Spoofing Using Spatial Pyramid Pooling
Lei Shi, Zhuo Zhou, Zhenhua Guo

Auto-TLDR; Spatial Pyramid Pooling for Face Anti-Spoofing
Abstract Slides Poster Similar
Automatic Annotation of Corpora for Emotion Recognition through Facial Expressions Analysis
Alex Mircoli, Claudia Diamantini, Domenico Potena, Emanuele Storti

Auto-TLDR; Automatic annotation of video subtitles on the basis of facial expressions using machine learning algorithms
Abstract Slides Poster Similar
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
AdaFilter: Adaptive Filter Design with Local Image Basis Decomposition for Optimizing Image Recognition Preprocessing
Aiga Suzuki, Keiichi Ito, Takahide Ibe, Nobuyuki Otsu

Auto-TLDR; Optimal Preprocessing Filtering for Pattern Recognition Using Higher-Order Local Auto-Correlation
Abstract Slides Poster Similar
Decision Snippet Features
Pascal Welke, Fouad Alkhoury, Christian Bauckhage, Stefan Wrobel

Auto-TLDR; Decision Snippet Features for Interpretability
Abstract Slides Poster Similar
Siamese Graph Convolution Network for Face Sketch Recognition
Liang Fan, Xianfang Sun, Paul Rosin

Auto-TLDR; A novel Siamese graph convolution network for face sketch recognition
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar
FastSal: A Computationally Efficient Network for Visual Saliency Prediction

Auto-TLDR; MobileNetV2: A Convolutional Neural Network for Saliency Prediction
Abstract Slides Poster Similar
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
Algorithm Recommendation for Data Streams
Jáder Martins Camboim De Sá, Andre Luis Debiaso Rossi, Gustavo Enrique De Almeida Prado Alves Batista, Luís Paulo Faina Garcia

Auto-TLDR; Meta-Learning for Algorithm Selection in Time-Changing Data Streams
Abstract Slides Poster Similar
Walk the Lines: Object Contour Tracing CNN for Contour Completion of Ships

Auto-TLDR; Walk the Lines: A Convolutional Neural Network trained to follow object contours
Abstract Slides Poster Similar
Uncertainty-Sensitive Activity Recognition: A Reliability Benchmark and the CARING Models
Alina Roitberg, Monica Haurilet, Manuel Martinez, Rainer Stiefelhagen

Auto-TLDR; CARING: Calibrated Action Recognition with Input Guidance
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Facial Expression Recognition Using Residual Masking Network
Luan Pham, Vu Huynh, Tuan Anh Tran

Auto-TLDR; Deep Residual Masking for Automatic Facial Expression Recognition
Abstract Slides Poster Similar
Verifying the Causes of Adversarial Examples
Honglin Li, Yifei Fan, Frieder Ganz, Tony Yezzi, Payam Barnaghi

Auto-TLDR; Exploring the Causes of Adversarial Examples in Neural Networks
Abstract Slides Poster Similar
Depth Videos for the Classification of Micro-Expressions
Ankith Jain Rakesh Kumar, Bir Bhanu, Christopher Casey, Sierra Cheung, Aaron Seitz

Auto-TLDR; RGB-D Dataset for the Classification of Facial Micro-expressions
Abstract Slides Poster Similar
Detecting Marine Species in Echograms Via Traditional, Hybrid, and Deep Learning Frameworks
Porto Marques Tunai, Alireza Rezvanifar, Melissa Cote, Alexandra Branzan Albu, Kaan Ersahin, Todd Mudge, Stephane Gauthier

Auto-TLDR; End-to-End Deep Learning for Echogram Interpretation of Marine Species in Echograms
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
How Does DCNN Make Decisions?
Yi Lin, Namin Wang, Xiaoqing Ma, Ziwei Li, Gang Bai

Auto-TLDR; Exploring Deep Convolutional Neural Network's Decision-Making Interpretability
Abstract Slides Poster Similar
Two-Level Attention-Based Fusion Learning for RGB-D Face Recognition
Hardik Uppal, Alireza Sepas-Moghaddam, Michael Greenspan, Ali Etemad

Auto-TLDR; Fused RGB-D Facial Recognition using Attention-Aware Feature Fusion
Abstract Slides Poster Similar
Object-Oriented Map Exploration and Construction Based on Auxiliary Task Aided DRL
Junzhe Xu, Jianhua Zhang, Shengyong Chen, Honghai Liu

Auto-TLDR; Auxiliary Task Aided Deep Reinforcement Learning for Environment Exploration by Autonomous Robots
RWMF: A Real-World Multimodal Foodlog Database
Pengfei Zhou, Cong Bai, Kaining Ying, Jie Xia, Lixin Huang
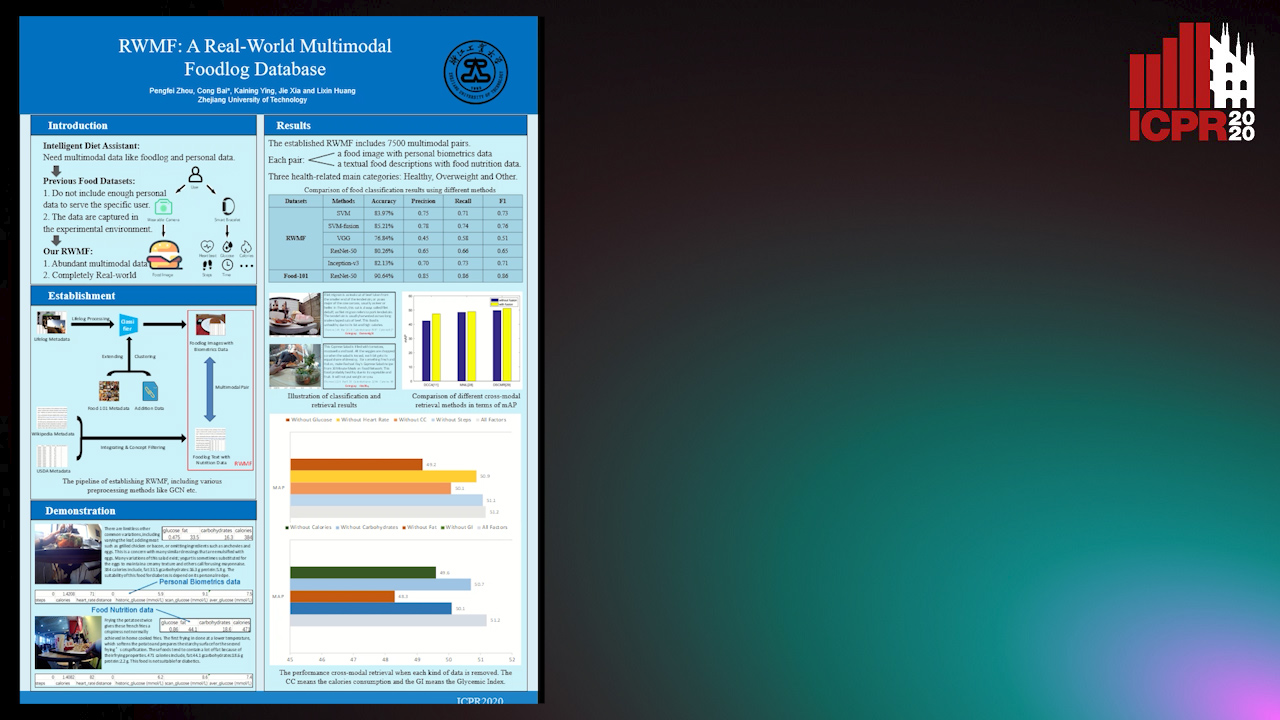
Auto-TLDR; Real-World Multimodal Foodlog: A Real-World Foodlog Database for Diet Assistant
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar