Visual Object Tracking in Drone Images with Deep Reinforcement Learning

Auto-TLDR; A Deep Reinforcement Learning based Single Object Tracker for Drone Applications
Similar papers
RSINet: Rotation-Scale Invariant Network for Online Visual Tracking
Yang Fang, Geunsik Jo, Chang-Hee Lee

Auto-TLDR; RSINet: Rotation-Scale Invariant Network for Adaptive Tracking
Abstract Slides Poster Similar
Model Decay in Long-Term Tracking
Efstratios Gavves, Ran Tao, Deepak Gupta, Arnold Smeulders
Auto-TLDR; Model Bias in Long-Term Tracking
Abstract Slides Poster Similar
Siamese Fully Convolutional Tracker with Motion Correction
Mathew Francis, Prithwijit Guha

Auto-TLDR; A Siamese Ensemble for Visual Tracking with Appearance and Motion Components
Abstract Slides Poster Similar
DAL: A Deep Depth-Aware Long-Term Tracker
Yanlin Qian, Song Yan, Alan Lukežič, Matej Kristan, Joni-Kristian Kamarainen, Jiri Matas

Auto-TLDR; Deep Depth-Aware Long-Term RGBD Tracking with Deep Discriminative Correlation Filter
Abstract Slides Poster Similar
VTT: Long-Term Visual Tracking with Transformers
Tianling Bian, Yang Hua, Tao Song, Zhengui Xue, Ruhui Ma, Neil Robertson, Haibing Guan

Auto-TLDR; Visual Tracking Transformer with transformers for long-term visual tracking
Tackling Occlusion in Siamese Tracking with Structured Dropouts
Deepak Gupta, Efstratios Gavves, Arnold Smeulders
Auto-TLDR; Structured Dropout for Occlusion in latent space
Abstract Slides Poster Similar
TSDM: Tracking by SiamRPN++ with a Depth-Refiner and a Mask-Generator
Pengyao Zhao, Quanli Liu, Wei Wang, Qiang Guo

Auto-TLDR; TSDM: A Depth-D Tracker for 3D Object Tracking
Abstract Slides Poster Similar
Adaptive Context-Aware Discriminative Correlation Filters for Robust Visual Object Tracking
Tianyang Xu, Zhenhua Feng, Xiaojun Wu, Josef Kittler

Auto-TLDR; ACA-DCF: Adaptive Context-Aware Discriminative Correlation Filter with complementary attention mechanisms
Abstract Slides Poster Similar
MFST: Multi-Features Siamese Tracker
Zhenxi Li, Guillaume-Alexandre Bilodeau, Wassim Bouachir

Auto-TLDR; Multi-Features Siamese Tracker for Robust Deep Similarity Tracking
Robust Visual Object Tracking with Two-Stream Residual Convolutional Networks
Ning Zhang, Jingen Liu, Ke Wang, Dan Zeng, Tao Mei

Auto-TLDR; Two-Stream Residual Convolutional Network for Visual Tracking
Abstract Slides Poster Similar
Efficient Correlation Filter Tracking with Adaptive Training Sample Update Scheme
Shan Jiang, Shuxiao Li, Chengfei Zhu, Nan Yan

Auto-TLDR; Adaptive Training Sample Update Scheme of Correlation Filter Based Trackers for Visual Tracking
Abstract Slides Poster Similar
Reducing False Positives in Object Tracking with Siamese Network
Takuya Ogawa, Takashi Shibata, Shoji Yachida, Toshinori Hosoi

Auto-TLDR; Robust Long-Term Object Tracking with Adaptive Search based on Motion Models
Abstract Slides Poster Similar
SiamMT: Real-Time Arbitrary Multi-Object Tracking
Lorenzo Vaquero, Manuel Mucientes, Victor Brea

Auto-TLDR; SiamMT: A Deep-Learning-based Arbitrary Multi-Object Tracking System for Video
Abstract Slides Poster Similar
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Maximilian Kraus, Seyed Majid Azimi, Emec Ercelik, Reza Bahmanyar, Peter Reinartz, Alois Knoll

Auto-TLDR; AerialMPTNet: A novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features
Abstract Slides Poster Similar
Exploiting Distilled Learning for Deep Siamese Tracking
Chengxin Liu, Zhiguo Cao, Wei Li, Yang Xiao, Shuaiyuan Du, Angfan Zhu

Auto-TLDR; Distilled Learning Framework for Siamese Tracking
Abstract Slides Poster Similar
Compact and Discriminative Multi-Object Tracking with Siamese CNNs
Claire Labit-Bonis, Jérôme Thomas, Frederic Lerasle

Auto-TLDR; Fast, Light-Weight and All-in-One Single Object Tracking for Multi-Target Management
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
SyNet: An Ensemble Network for Object Detection in UAV Images

Auto-TLDR; SyNet: Combining Multi-Stage and Single-Stage Object Detection for Aerial Images
Object-Oriented Map Exploration and Construction Based on Auxiliary Task Aided DRL
Junzhe Xu, Jianhua Zhang, Shengyong Chen, Honghai Liu

Auto-TLDR; Auxiliary Task Aided Deep Reinforcement Learning for Environment Exploration by Autonomous Robots
Tracking Fast Moving Objects by Segmentation Network

Auto-TLDR; Fast Moving Objects Tracking by Segmentation Using Deep Learning
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
Low Dimensional State Representation Learning with Reward-Shaped Priors
Nicolò Botteghi, Ruben Obbink, Daan Geijs, Mannes Poel, Beril Sirmacek, Christoph Brune, Abeje Mersha, Stefano Stramigioli

Auto-TLDR; Unsupervised Learning for Unsupervised Reinforcement Learning in Robotics
Siamese Dynamic Mask Estimation Network for Fast Video Object Segmentation
Dexiang Hong, Guorong Li, Kai Xu, Li Su, Qingming Huang

Auto-TLDR; Siamese Dynamic Mask Estimation for Video Object Segmentation
Abstract Slides Poster Similar
SynDHN: Multi-Object Fish Tracker Trained on Synthetic Underwater Videos
Mygel Andrei Martija, Prospero Naval

Auto-TLDR; Underwater Multi-Object Tracking in the Wild with Deep Hungarian Network
Abstract Slides Poster Similar
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Zahra Gharaee, Karl Holmquist, Linbo He, Michael Felsberg

Auto-TLDR; Bayesian Reinforcement Learning for Autonomous Driving
Abstract Slides Poster Similar
IPT: A Dataset for Identity Preserved Tracking in Closed Domains
Thomas Heitzinger, Martin Kampel

Auto-TLDR; Identity Preserved Tracking Using Depth Data for Privacy and Privacy
Abstract Slides Poster Similar
Vehicle Lane Merge Visual Benchmark

Auto-TLDR; A Benchmark for Automated Cooperative Maneuvering Using Multi-view Video Streams and Ground Truth Vehicle Description
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
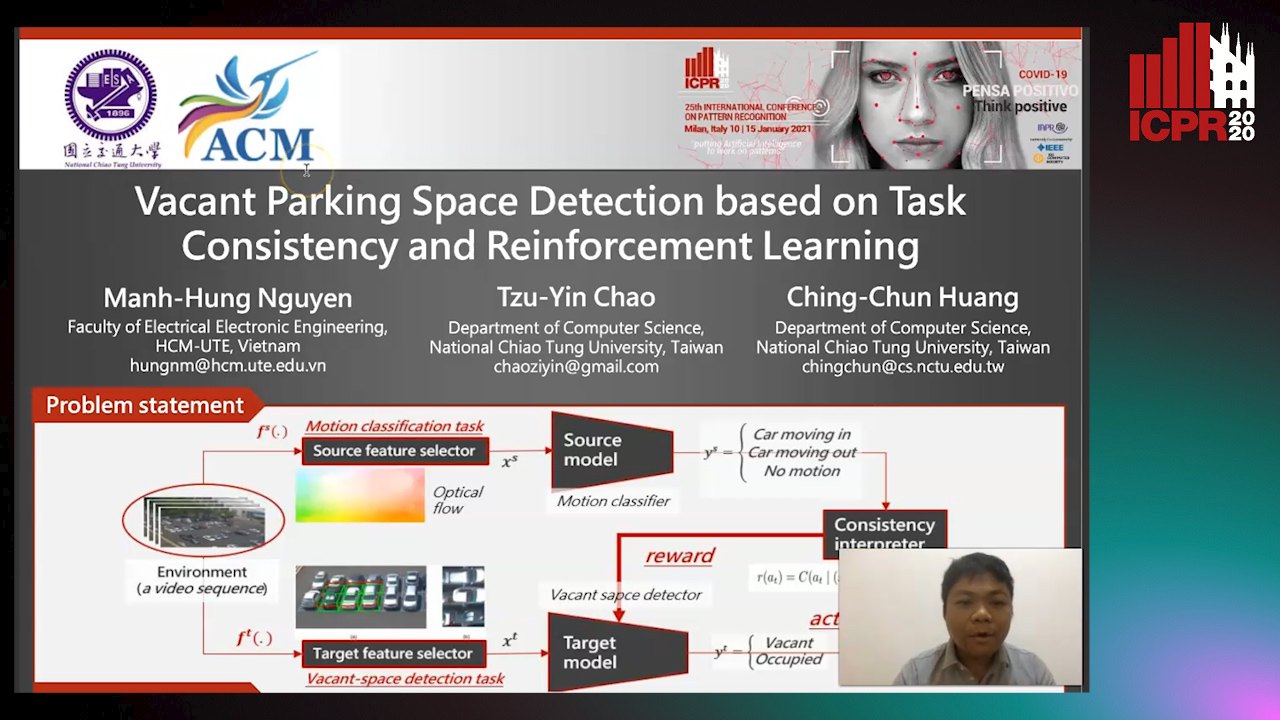
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
Visual Saliency Oriented Vehicle Scale Estimation
Qixin Chen, Tie Liu, Jiali Ding, Zejian Yuan, Yuanyuan Shang

Auto-TLDR; Regularized Intensity Matching for Vehicle Scale Estimation with salient object detection
Abstract Slides Poster Similar
Utilising Visual Attention Cues for Vehicle Detection and Tracking
Feiyan Hu, Venkatesh Gurram Munirathnam, Noel E O'Connor, Alan Smeaton, Suzanne Little

Auto-TLDR; Visual Attention for Object Detection and Tracking in Driver-Assistance Systems
Abstract Slides Poster Similar
Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Nuo Xu, Chunlei Huo, Chunhong Pan

Auto-TLDR; Adaptive Image Attribute Learning for Active Object Detection
Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Security Videos
Mamshad Nayeem Rizve, Ugur Demir, Praveen Praveen Tirupattur, Aayush Jung Rana, Kevin Duarte, Ishan Rajendrakumar Dave, Yogesh Rawat, Mubarak Shah

Auto-TLDR; Gabriella: A Real-Time Online System for Activity Detection in Surveillance Videos
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
An Adaptive Fusion Model Based on Kalman Filtering and LSTM for Fast Tracking of Road Signs
Chengliang Wang, Xin Xie, Chao Liao

Auto-TLDR; Fusion of ThunderNet and Region Growing Detector for Road Sign Detection and Tracking
Abstract Slides Poster Similar
Mobile Augmented Reality: Fast, Precise, and Smooth Planar Object Tracking
Dmitrii Matveichev, Daw-Tung Lin

Auto-TLDR; Planar Object Tracking with Sparse Optical Flow Tracking and Descriptor Matching
Abstract Slides Poster Similar
Meta Learning Via Learned Loss
Sarah Bechtle, Artem Molchanov, Yevgen Chebotar, Edward Thomas Grefenstette, Ludovic Righetti, Gaurav Sukhatme, Franziska Meier

Auto-TLDR; meta-learning for learning parametric loss functions that generalize across different tasks and model architectures
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Anomaly Detection, Localization and Classification for Railway Inspection
Riccardo Gasparini, Andrea D'Eusanio, Guido Borghi, Stefano Pini, Giuseppe Scaglione, Simone Calderara, Eugenio Fedeli, Rita Cucchiara

Auto-TLDR; Anomaly Detection and Localization using thermal images in the lowlight environment
Precise Temporal Action Localization with Quantified Temporal Structure of Actions
Chongkai Lu, Ruimin Li, Hong Fu, Bin Fu, Yihao Wang, Wai Lun Lo, Zheru Chi

Auto-TLDR; Action progression networks for temporal action detection
Abstract Slides Poster Similar
Can Reinforcement Learning Lead to Healthy Life?: Simulation Study Based on User Activity Logs
Masami Takahashi, Masahiro Kohjima, Takeshi Kurashima, Hiroyuki Toda

Auto-TLDR; Reinforcement Learning for Healthy Daily Life
Abstract Slides Poster Similar
Improving Robotic Grasping on Monocular Images Via Multi-Task Learning and Positional Loss
William Prew, Toby Breckon, Magnus Bordewich, Ulrik Beierholm

Auto-TLDR; Improving grasping performance from monocularcolour images in an end-to-end CNN architecture with multi-task learning
Abstract Slides Poster Similar
Real-Time Drone Detection and Tracking with Visible, Thermal and Acoustic Sensors
Fredrik Svanström, Cristofer Englund, Fernando Alonso-Fernandez

Auto-TLDR; Automatic multi-sensor drone detection using sensor fusion
Abstract Slides Poster Similar
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Learning Object Deformation and Motion Adaption for Semi-Supervised Video Object Segmentation
Xiaoyang Zheng, Xin Tan, Jianming Guo, Lizhuang Ma

Auto-TLDR; Semi-supervised Video Object Segmentation with Mask-propagation-based Model
Abstract Slides Poster Similar
Detecting and Adapting to Crisis Pattern with Context Based Deep Reinforcement Learning
Eric Benhamou, David Saltiel Saltiel, Jean-Jacques Ohana Ohana, Jamal Atif Atif

Auto-TLDR; Deep Reinforcement Learning for Financial Crisis Detection and Dis-Investment
Abstract Slides Poster Similar
Iterative Bounding Box Annotation for Object Detection
Bishwo Adhikari, Heikki Juhani Huttunen

Auto-TLDR; Semi-Automatic Bounding Box Annotation for Object Detection in Digital Images
Abstract Slides Poster Similar