Trajectory Representation Learning for Multi-Task NMRDP Planning
Firas Jarboui,
Vianney Perchet

Auto-TLDR; Exploring Non Markovian Reward Decision Processes for Reinforcement Learning
Similar papers
Low Dimensional State Representation Learning with Reward-Shaped Priors
Nicolò Botteghi, Ruben Obbink, Daan Geijs, Mannes Poel, Beril Sirmacek, Christoph Brune, Abeje Mersha, Stefano Stramigioli

Auto-TLDR; Unsupervised Learning for Unsupervised Reinforcement Learning in Robotics
Deep Reinforcement Learning on a Budget: 3D Control and Reasoning without a Supercomputer
Edward Beeching, Jilles Steeve Dibangoye, Olivier Simonin, Christian Wolf

Auto-TLDR; Deep Reinforcement Learning in Mobile Robots Using 3D Environment Scenarios
Abstract Slides Poster Similar
AVD-Net: Attention Value Decomposition Network for Deep Multi-Agent Reinforcement Learning
Zhang Yuanxin, Huimin Ma, Yu Wang

Auto-TLDR; Attention Value Decomposition Network for Cooperative Multi-agent Reinforcement Learning
Abstract Slides Poster Similar
Can Reinforcement Learning Lead to Healthy Life?: Simulation Study Based on User Activity Logs
Masami Takahashi, Masahiro Kohjima, Takeshi Kurashima, Hiroyuki Toda

Auto-TLDR; Reinforcement Learning for Healthy Daily Life
Abstract Slides Poster Similar
The Effect of Multi-Step Methods on Overestimation in Deep Reinforcement Learning
Lingheng Meng, Rob Gorbet, Dana Kulić

Auto-TLDR; Multi-Step DDPG for Deep Reinforcement Learning
Abstract Slides Poster Similar
Object-Oriented Map Exploration and Construction Based on Auxiliary Task Aided DRL
Junzhe Xu, Jianhua Zhang, Shengyong Chen, Honghai Liu

Auto-TLDR; Auxiliary Task Aided Deep Reinforcement Learning for Environment Exploration by Autonomous Robots
Meta Learning Via Learned Loss
Sarah Bechtle, Artem Molchanov, Yevgen Chebotar, Edward Thomas Grefenstette, Ludovic Righetti, Gaurav Sukhatme, Franziska Meier

Auto-TLDR; meta-learning for learning parametric loss functions that generalize across different tasks and model architectures
Detecting and Adapting to Crisis Pattern with Context Based Deep Reinforcement Learning
Eric Benhamou, David Saltiel Saltiel, Jean-Jacques Ohana Ohana, Jamal Atif Atif

Auto-TLDR; Deep Reinforcement Learning for Financial Crisis Detection and Dis-Investment
Abstract Slides Poster Similar
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Zahra Gharaee, Karl Holmquist, Linbo He, Michael Felsberg

Auto-TLDR; Bayesian Reinforcement Learning for Autonomous Driving
Abstract Slides Poster Similar
Learning from Learners: Adapting Reinforcement Learning Agents to Be Competitive in a Card Game
Pablo Vinicius Alves De Barros, Ana Tanevska, Alessandra Sciutti

Auto-TLDR; Adaptive Reinforcement Learning for Competitive Card Games
Abstract Slides Poster Similar
Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Hongli Zhou, Guanwen Zhang, Wei Zhou

Auto-TLDR; Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Abstract Slides Poster Similar
DAG-Net: Double Attentive Graph Neural Network for Trajectory Forecasting
Alessio Monti, Alessia Bertugli, Simone Calderara, Rita Cucchiara

Auto-TLDR; Recurrent Generative Model for Multi-modal Human Motion Behaviour in Urban Environments
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
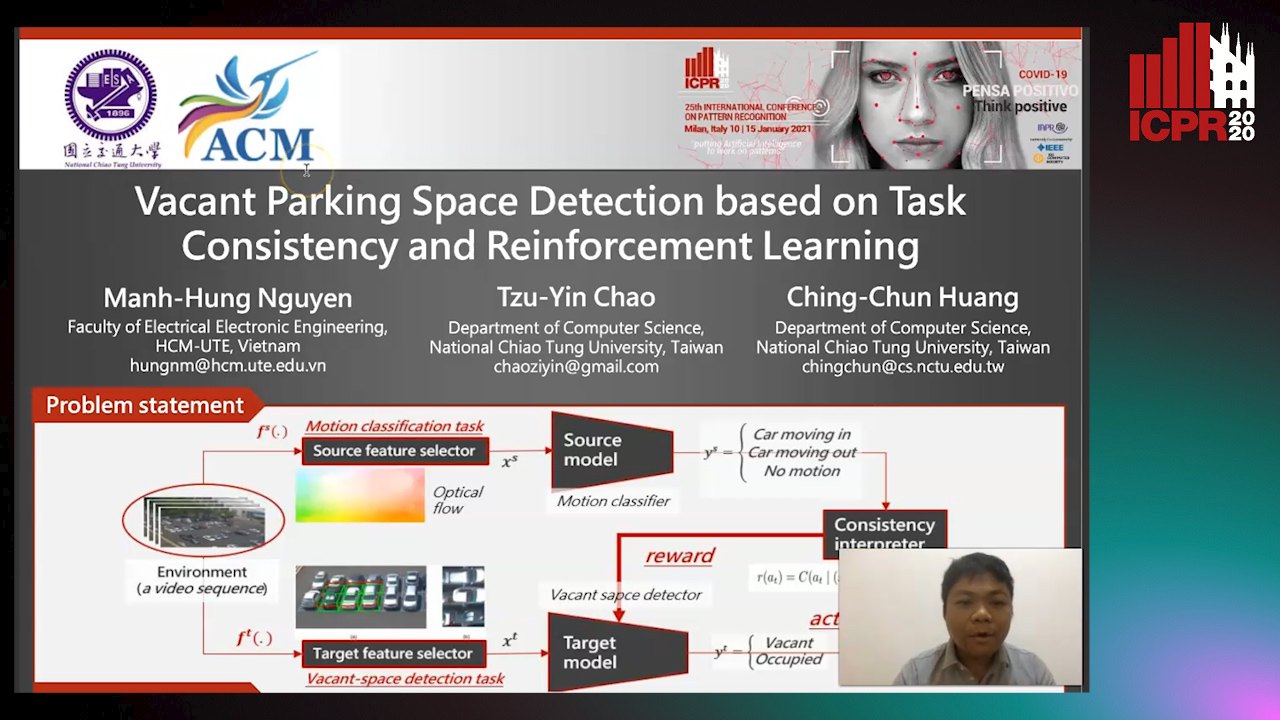
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
Trajectory-User Link with Attention Recurrent Networks
Tao Sun, Yongjun Xu, Fei Wang, Lin Wu, 塘文 钱, Zezhi Shao

Auto-TLDR; TULAR: Trajectory-User Link with Attention Recurrent Neural Networks
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
Switching Dynamical Systems with Deep Neural Networks
Cesar Ali Ojeda Marin, Kostadin Cvejoski, Bogdan Georgiev, Ramses J. Sanchez

Auto-TLDR; Variational RNN for Switching Dynamics
Abstract Slides Poster Similar
Recurrent Deep Attention Network for Person Re-Identification
Changhao Wang, Jun Zhou, Xianfei Duan, Guanwen Zhang, Wei Zhou

Auto-TLDR; Recurrent Deep Attention Network for Person Re-identification
Abstract Slides Poster Similar
Self-Play or Group Practice: Learning to Play Alternating Markov Game in Multi-Agent System
Chin-Wing Leung, Shuyue Hu, Ho-Fung Leung

Auto-TLDR; Group Practice for Deep Reinforcement Learning
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
Map-Based Temporally Consistent Geolocalization through Learning Motion Trajectories

Auto-TLDR; Exploiting Motion Trajectories for Geolocalization of Object on Topological Map using Recurrent Neural Network
Abstract Slides Poster Similar
Explore and Explain: Self-Supervised Navigation and Recounting
Roberto Bigazzi, Federico Landi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Exploring a Photorealistic Environment for Explanation and Navigation
AG-GAN: An Attentive Group-Aware GAN for Pedestrian Trajectory Prediction
Yue Song, Niccolò Bisagno, Syed Zohaib Hassan, Nicola Conci

Auto-TLDR; An attentive group-aware GAN for motion prediction in crowded scenarios
Abstract Slides Poster Similar
A Novel Actor Dual-Critic Model for Remote Sensing Image Captioning
Ruchika Chavhan, Biplab Banerjee, Xiao Xiang Zhu, Subhasis Chaudhuri

Auto-TLDR; Actor Dual-Critic Training for Remote Sensing Image Captioning Using Deep Reinforcement Learning
Abstract Slides Poster Similar
Deep Next-Best-View Planner for Cross-Season Visual Route Classification

Auto-TLDR; Active Visual Place Recognition using Deep Convolutional Neural Network
Abstract Slides Poster Similar
Road Network Metric Learning for Estimated Time of Arrival
Yiwen Sun, Kun Fu, Zheng Wang, Changshui Zhang, Jieping Ye

Auto-TLDR; Road Network Metric Learning for Estimated Time of Arrival (RNML-ETA)
Abstract Slides Poster Similar
Visual Object Tracking in Drone Images with Deep Reinforcement Learning

Auto-TLDR; A Deep Reinforcement Learning based Single Object Tracker for Drone Applications
Abstract Slides Poster Similar
AOAM: Automatic Optimization of Adjacency Matrix for Graph Convolutional Network
Yuhang Zhang, Hongshuai Ren, Jiexia Ye, Xitong Gao, Yang Wang, Kejiang Ye, Cheng-Zhong Xu

Auto-TLDR; Adjacency Matrix for Graph Convolutional Network in Non-Euclidean Space
Abstract Slides Poster Similar
Transformer Networks for Trajectory Forecasting
Francesco Giuliari, Hasan Irtiza, Marco Cristani, Fabio Galasso

Auto-TLDR; TransformerNetworks for Trajectory Prediction of People Interactions
Abstract Slides Poster Similar
On Embodied Visual Navigation in Real Environments through Habitat
Marco Rosano, Antonino Furnari, Luigi Gulino, Giovanni Maria Farinella

Auto-TLDR; Learning Navigation Policies on Real World Observations using Real World Images and Sensor and Actuation Noise
Abstract Slides Poster Similar
Interpolation in Auto Encoders with Bridge Processes
Carl Ringqvist, Henrik Hult, Judith Butepage, Hedvig Kjellstrom

Auto-TLDR; Stochastic interpolations from auto encoders trained on flattened sequences
Abstract Slides Poster Similar
Progressive Learning Algorithm for Efficient Person Re-Identification
Zhen Li, Hanyang Shao, Liang Niu, Nian Xue

Auto-TLDR; Progressive Learning Algorithm for Large-Scale Person Re-Identification
Abstract Slides Poster Similar
ILS-SUMM: Iterated Local Search for Unsupervised Video Summarization
Yair Shemer, Daniel Rotman, Nahum Shimkin

Auto-TLDR; ILS-SUMM: Iterated Local Search for Video Summarization
Naturally Constrained Online Expectation Maximization
Daniela Pamplona, Antoine Manzanera

Auto-TLDR; Constrained Online Expectation-Maximization for Probabilistic Principal Components Analysis
Abstract Slides Poster Similar
SAILenv: Learning in Virtual Visual Environments Made Simple
Enrico Meloni, Luca Pasqualini, Matteo Tiezzi, Marco Gori, Stefano Melacci

Auto-TLDR; SAILenv: A Simple and Customized Platform for Visual Recognition in Virtual 3D Environment
Abstract Slides Poster Similar
Beyond Cross-Entropy: Learning Highly Separable Feature Distributions for Robust and Accurate Classification
Arslan Ali, Andrea Migliorati, Tiziano Bianchi, Enrico Magli

Auto-TLDR; Gaussian class-conditional simplex loss for adversarial robust multiclass classifiers
Abstract Slides Poster Similar
Learning Embeddings for Image Clustering: An Empirical Study of Triplet Loss Approaches
Kalun Ho, Janis Keuper, Franz-Josef Pfreundt, Margret Keuper

Auto-TLDR; Clustering Objectives for K-means and Correlation Clustering Using Triplet Loss
Abstract Slides Poster Similar
Class-Incremental Learning with Pre-Allocated Fixed Classifiers
Federico Pernici, Matteo Bruni, Claudio Baecchi, Francesco Turchini, Alberto Del Bimbo

Auto-TLDR; Class-Incremental Learning with Pre-allocated Output Nodes for Fixed Classifier
Abstract Slides Poster Similar
Aggregating Dependent Gaussian Experts in Local Approximation

Auto-TLDR; A novel approach for aggregating the Gaussian experts by detecting strong violations of conditional independence
Abstract Slides Poster Similar
Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Nuo Xu, Chunlei Huo, Chunhong Pan

Auto-TLDR; Adaptive Image Attribute Learning for Active Object Detection
Equation Attention Relationship Network (EARN) : A Geometric Deep Metric Framework for Learning Similar Math Expression Embedding
Saleem Ahmed, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; Representational Learning for Similarity Based Retrieval of Mathematical Expressions
Abstract Slides Poster Similar
Deep Top-Rank Counter Metric for Person Re-Identification
Chen Chen, Hao Dou, Xiyuan Hu, Silong Peng

Auto-TLDR; Deep Top-Rank Counter Metric for Person Re-identification
Abstract Slides Poster Similar
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Kernel-based Graph Convolutional Networks

Auto-TLDR; Spatial Graph Convolutional Networks in Recurrent Kernel Hilbert Space
Abstract Slides Poster Similar
Temporally Coherent Embeddings for Self-Supervised Video Representation Learning
Joshua Knights, Ben Harwood, Daniel Ward, Anthony Vanderkop, Olivia Mackenzie-Ross, Peyman Moghadam

Auto-TLDR; Temporally Coherent Embeddings for Self-supervised Video Representation Learning
Abstract Slides Poster Similar
Loop-closure detection by LiDAR scan re-identification
Jukka Peltomäki, Xingyang Ni, Jussi Puura, Joni-Kristian Kamarainen, Heikki Juhani Huttunen

Auto-TLDR; Loop-Closing Detection from LiDAR Scans Using Convolutional Neural Networks
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
SL-DML: Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Raphael Memmesheimer, Nick Theisen, Dietrich Paulus

Auto-TLDR; One-Shot Action Recognition using Metric Learning
RNN Training along Locally Optimal Trajectories via Frank-Wolfe Algorithm
Yun Yue, Ming Li, Venkatesh Saligrama, Ziming Zhang

Auto-TLDR; Frank-Wolfe Algorithm for Efficient Training of RNNs
Abstract Slides Poster Similar