Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Hongli Zhou,
Guanwen Zhang,
Wei Zhou

Auto-TLDR; Deep Reinforcement Learning for Autonomous Driving by Transferring Visual Features
Similar papers
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Zahra Gharaee, Karl Holmquist, Linbo He, Michael Felsberg

Auto-TLDR; Bayesian Reinforcement Learning for Autonomous Driving
Abstract Slides Poster Similar
Cross-Domain Semantic Segmentation of Urban Scenes Via Multi-Level Feature Alignment
Bin Zhang, Shengjie Zhao, Rongqing Zhang

Auto-TLDR; Cross-Domain Semantic Segmentation Using Generative Adversarial Networks
Abstract Slides Poster Similar
Unsupervised Multi-Task Domain Adaptation

Auto-TLDR; Unsupervised Domain Adaptation with Multi-task Learning for Image Recognition
Abstract Slides Poster Similar
AVD-Net: Attention Value Decomposition Network for Deep Multi-Agent Reinforcement Learning
Zhang Yuanxin, Huimin Ma, Yu Wang

Auto-TLDR; Attention Value Decomposition Network for Cooperative Multi-agent Reinforcement Learning
Abstract Slides Poster Similar
Low Dimensional State Representation Learning with Reward-Shaped Priors
Nicolò Botteghi, Ruben Obbink, Daan Geijs, Mannes Poel, Beril Sirmacek, Christoph Brune, Abeje Mersha, Stefano Stramigioli

Auto-TLDR; Unsupervised Learning for Unsupervised Reinforcement Learning in Robotics
Object-Oriented Map Exploration and Construction Based on Auxiliary Task Aided DRL
Junzhe Xu, Jianhua Zhang, Shengyong Chen, Honghai Liu

Auto-TLDR; Auxiliary Task Aided Deep Reinforcement Learning for Environment Exploration by Autonomous Robots
Learning from Learners: Adapting Reinforcement Learning Agents to Be Competitive in a Card Game
Pablo Vinicius Alves De Barros, Ana Tanevska, Alessandra Sciutti

Auto-TLDR; Adaptive Reinforcement Learning for Competitive Card Games
Abstract Slides Poster Similar
The Effect of Multi-Step Methods on Overestimation in Deep Reinforcement Learning
Lingheng Meng, Rob Gorbet, Dana Kulić

Auto-TLDR; Multi-Step DDPG for Deep Reinforcement Learning
Abstract Slides Poster Similar
On Embodied Visual Navigation in Real Environments through Habitat
Marco Rosano, Antonino Furnari, Luigi Gulino, Giovanni Maria Farinella

Auto-TLDR; Learning Navigation Policies on Real World Observations using Real World Images and Sensor and Actuation Noise
Abstract Slides Poster Similar
Detail Fusion GAN: High-Quality Translation for Unpaired Images with GAN-Based Data Augmentation
Ling Li, Yaochen Li, Chuan Wu, Hang Dong, Peilin Jiang, Fei Wang

Auto-TLDR; Data Augmentation with GAN-based Generative Adversarial Network
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
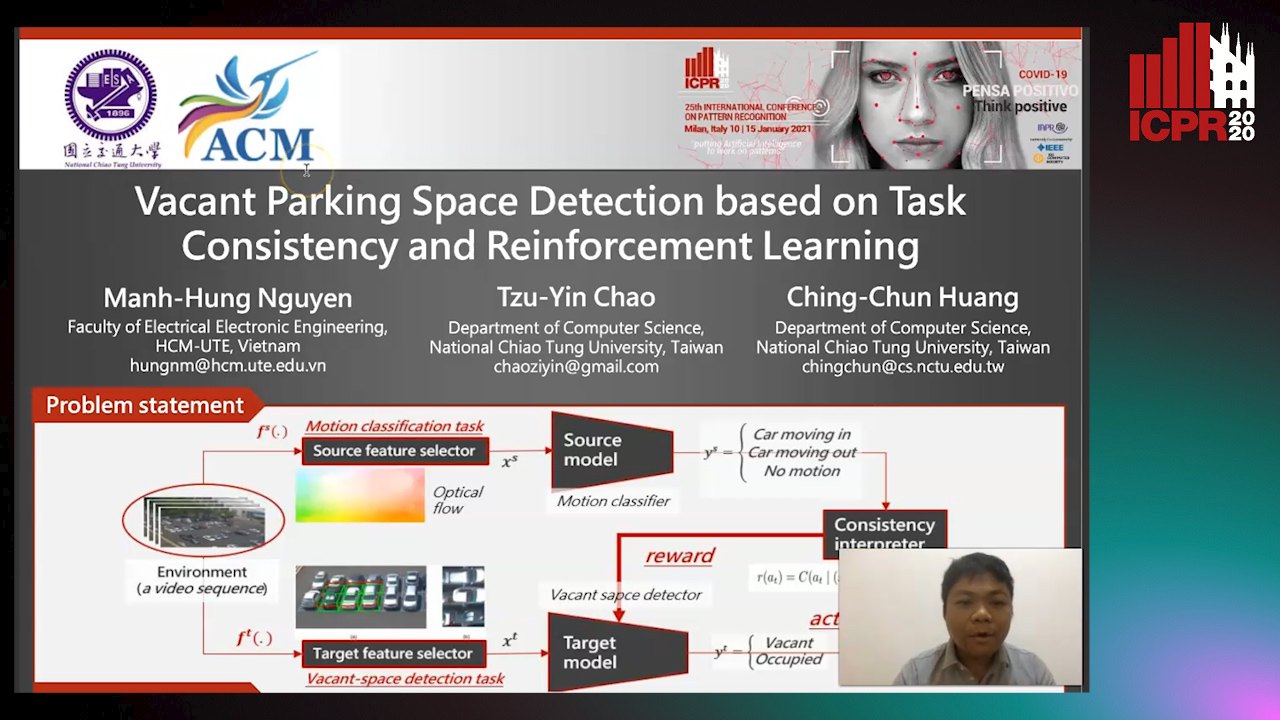
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
DAPC: Domain Adaptation People Counting Via Style-Level Transfer Learning and Scene-Aware Estimation
Na Jiang, Xingsen Wen, Zhiping Shi

Auto-TLDR; Domain Adaptation People counting via Style-Level Transfer Learning and Scene-Aware Estimation
Abstract Slides Poster Similar
Deep Reinforcement Learning on a Budget: 3D Control and Reasoning without a Supercomputer
Edward Beeching, Jilles Steeve Dibangoye, Olivier Simonin, Christian Wolf

Auto-TLDR; Deep Reinforcement Learning in Mobile Robots Using 3D Environment Scenarios
Abstract Slides Poster Similar
Detecting and Adapting to Crisis Pattern with Context Based Deep Reinforcement Learning
Eric Benhamou, David Saltiel Saltiel, Jean-Jacques Ohana Ohana, Jamal Atif Atif

Auto-TLDR; Deep Reinforcement Learning for Financial Crisis Detection and Dis-Investment
Abstract Slides Poster Similar
Trajectory Representation Learning for Multi-Task NMRDP Planning
Firas Jarboui, Vianney Perchet

Auto-TLDR; Exploring Non Markovian Reward Decision Processes for Reinforcement Learning
Abstract Slides Poster Similar
Unsupervised Domain Adaptation with Multiple Domain Discriminators and Adaptive Self-Training
Teo Spadotto, Marco Toldo, Umberto Michieli, Pietro Zanuttigh

Auto-TLDR; Unsupervised Domain Adaptation for Semantic Segmentation of Urban Scenes
Abstract Slides Poster Similar
DEN: Disentangling and Exchanging Network for Depth Completion
You-Feng Wu, Vu-Hoang Tran, Ting-Wei Chang, Wei-Chen Chiu, Ching-Chun Huang

Auto-TLDR; Disentangling and Exchanging Network for Depth Completion
Meta Learning Via Learned Loss
Sarah Bechtle, Artem Molchanov, Yevgen Chebotar, Edward Thomas Grefenstette, Ludovic Righetti, Gaurav Sukhatme, Franziska Meier

Auto-TLDR; meta-learning for learning parametric loss functions that generalize across different tasks and model architectures
Self-Play or Group Practice: Learning to Play Alternating Markov Game in Multi-Agent System
Chin-Wing Leung, Shuyue Hu, Ho-Fung Leung

Auto-TLDR; Group Practice for Deep Reinforcement Learning
Abstract Slides Poster Similar
Shape Consistent 2D Keypoint Estimation under Domain Shift
Levi Vasconcelos, Massimiliano Mancini, Davide Boscaini, Barbara Caputo, Elisa Ricci

Auto-TLDR; Deep Adaptation for Keypoint Prediction under Domain Shift
Abstract Slides Poster Similar
Galaxy Image Translation with Semi-Supervised Noise-Reconstructed Generative Adversarial Networks
Qiufan Lin, Dominique Fouchez, Jérôme Pasquet

Auto-TLDR; Semi-supervised Image Translation with Generative Adversarial Networks Using Paired and Unpaired Images
Abstract Slides Poster Similar
GAP: Quantifying the Generative Adversarial Set and Class Feature Applicability of Deep Neural Networks
Edward Collier, Supratik Mukhopadhyay

Auto-TLDR; Approximating Adversarial Learning in Deep Neural Networks Using Set and Class Adversaries
Abstract Slides Poster Similar
Randomized Transferable Machine

Auto-TLDR; Randomized Transferable Machine for Suboptimal Feature-based Transfer Learning
Abstract Slides Poster Similar
Local Facial Attribute Transfer through Inpainting
Ricard Durall, Franz-Josef Pfreundt, Janis Keuper

Auto-TLDR; Attribute Transfer Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
Cycle-Consistent Adversarial Networks and Fast Adaptive Bi-Dimensional Empirical Mode Decomposition for Style Transfer
Elissavet Batziou, Petros Alvanitopoulos, Konstantinos Ioannidis, Ioannis Patras, Stefanos Vrochidis, Ioannis Kompatsiaris

Auto-TLDR; FABEMD: Fast and Adaptive Bidimensional Empirical Mode Decomposition for Style Transfer on Images
Abstract Slides Poster Similar
Unsupervised Contrastive Photo-To-Caricature Translation Based on Auto-Distortion
Yuhe Ding, Xin Ma, Mandi Luo, Aihua Zheng, Ran He

Auto-TLDR; Unsupervised contrastive photo-to-caricature translation with style loss
Abstract Slides Poster Similar
A Simple Domain Shifting Network for Generating Low Quality Images
Guruprasad Hegde, Avinash Nittur Ramesh, Kanchana Vaishnavi Gandikota, Michael Möller, Roman Obermaisser

Auto-TLDR; Robotic Image Classification Using Quality degrading networks
Abstract Slides Poster Similar
Enlarging Discriminative Power by Adding an Extra Class in Unsupervised Domain Adaptation
Hai Tran, Sumyeong Ahn, Taeyoung Lee, Yung Yi

Auto-TLDR; Unsupervised Domain Adaptation using Artificial Classes
Abstract Slides Poster Similar
Augmented Cyclic Consistency Regularization for Unpaired Image-To-Image Translation
Takehiko Ohkawa, Naoto Inoue, Hirokatsu Kataoka, Nakamasa Inoue

Auto-TLDR; Augmented Cyclic Consistency Regularization for Unpaired Image-to-Image Translation
Abstract Slides Poster Similar
Data Augmentation Via Mixed Class Interpolation Using Cycle-Consistent Generative Adversarial Networks Applied to Cross-Domain Imagery
Hiroshi Sasaki, Chris G. Willcocks, Toby Breckon

Auto-TLDR; C2GMA: A Generative Domain Transfer Model for Non-visible Domain Classification
Abstract Slides Poster Similar
Dual-MTGAN: Stochastic and Deterministic Motion Transfer for Image-To-Video Synthesis
Fu-En Yang, Jing-Cheng Chang, Yuan-Hao Lee, Yu-Chiang Frank Wang

Auto-TLDR; Dual Motion Transfer GAN for Convolutional Neural Networks
Abstract Slides Poster Similar
Foreground-Focused Domain Adaption for Object Detection

Auto-TLDR; Unsupervised Domain Adaptation for Unsupervised Object Detection
Efficient Shadow Detection and Removal Using Synthetic Data with Domain Adaptation
Rui Guo, Babajide Ayinde, Hao Sun

Auto-TLDR; Shadow Detection and Removal with Domain Adaptation and Synthetic Image Database
A Unified Framework for Distance-Aware Domain Adaptation
Fei Wang, Youdong Ding, Huan Liang, Yuzhen Gao, Wenqi Che

Auto-TLDR; distance-aware domain adaptation
Abstract Slides Poster Similar
Spatial-Aware GAN for Unsupervised Person Re-Identification
Fangneng Zhan, Changgong Zhang

Auto-TLDR; Unsupervised Unsupervised Domain Adaptation for Person Re-Identification
Class Conditional Alignment for Partial Domain Adaptation
Mohsen Kheirandishfard, Fariba Zohrizadeh, Farhad Kamangar

Auto-TLDR; Multi-class Adversarial Adaptation for Partial Domain Adaptation
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
Explore and Explain: Self-Supervised Navigation and Recounting
Roberto Bigazzi, Federico Landi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Exploring a Photorealistic Environment for Explanation and Navigation
Learning Low-Shot Generative Networks for Cross-Domain Data
Hsuan-Kai Kao, Cheng-Che Lee, Wei-Chen Chiu

Auto-TLDR; Learning Generators for Cross-Domain Data under Low-Shot Learning
Abstract Slides Poster Similar
Energy-Constrained Self-Training for Unsupervised Domain Adaptation
Xiaofeng Liu, Xiongchang Liu, Bo Hu, Jun Lu, Jonghye Woo, Jane You

Auto-TLDR; Unsupervised Domain Adaptation with Energy Function Minimization
Abstract Slides Poster Similar
Supervised Domain Adaptation Using Graph Embedding
Lukas Hedegaard, Omar Ali Sheikh-Omar, Alexandros Iosifidis

Auto-TLDR; Domain Adaptation from the Perspective of Multi-view Graph Embedding and Dimensionality Reduction
Abstract Slides Poster Similar
Manual-Label Free 3D Detection Via an Open-Source Simulator
Zhen Yang, Chi Zhang, Zhaoxiang Zhang, Huiming Guo

Auto-TLDR; DA-VoxelNet: A Novel Domain Adaptive VoxelNet for LIDAR-based 3D Object Detection
Abstract Slides Poster Similar
Visual Object Tracking in Drone Images with Deep Reinforcement Learning

Auto-TLDR; A Deep Reinforcement Learning based Single Object Tracker for Drone Applications
Abstract Slides Poster Similar
Deep Next-Best-View Planner for Cross-Season Visual Route Classification

Auto-TLDR; Active Visual Place Recognition using Deep Convolutional Neural Network
Abstract Slides Poster Similar
Multi-Domain Image-To-Image Translation with Adaptive Inference Graph
The Phuc Nguyen, Stéphane Lathuiliere, Elisa Ricci

Auto-TLDR; Adaptive Graph Structure for Multi-Domain Image-to-Image Translation
Abstract Slides Poster Similar
Teacher-Student Competition for Unsupervised Domain Adaptation
Ruixin Xiao, Zhilei Liu, Baoyuan Wu

Auto-TLDR; Unsupervised Domain Adaption with Teacher-Student Competition
Abstract Slides Poster Similar
Self-Supervised Domain Adaptation with Consistency Training
Liang Xiao, Jiaolong Xu, Dawei Zhao, Zhiyu Wang, Li Wang, Yiming Nie, Bin Dai

Auto-TLDR; Unsupervised Domain Adaptation for Image Classification
Abstract Slides Poster Similar