Online Object Recognition Using CNN-Based Algorithm on High-Speed Camera Imaging
Shigeaki Namiki,
Keiko Yokoyama,
Shoji Yachida,
Takashi Shibata,
Hiroyoshi Miyano,
Masatoshi Ishikawa

Auto-TLDR; Real-Time Object Recognition with High-Speed Camera Imaging with Population Data Clearing and Data Ensemble
Similar papers
SynDHN: Multi-Object Fish Tracker Trained on Synthetic Underwater Videos
Mygel Andrei Martija, Prospero Naval

Auto-TLDR; Underwater Multi-Object Tracking in the Wild with Deep Hungarian Network
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
Dynamic Resource-Aware Corner Detection for Bio-Inspired Vision Sensors
Sherif Abdelmonem Sayed Mohamed, Jawad Yasin, Mohammad-Hashem Haghbayan, Antonio Miele, Jukka Veikko Heikkonen, Hannu Tenhunen, Juha Plosila

Auto-TLDR; Three Layer Filtering-Harris Algorithm for Event-based Cameras in Real-Time
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
SiamMT: Real-Time Arbitrary Multi-Object Tracking
Lorenzo Vaquero, Manuel Mucientes, Victor Brea

Auto-TLDR; SiamMT: A Deep-Learning-based Arbitrary Multi-Object Tracking System for Video
Abstract Slides Poster Similar
RONELD: Robust Neural Network Output Enhancement for Active Lane Detection
Zhe Ming Chng, Joseph Mun Hung Lew, Jimmy Addison Lee

Auto-TLDR; Real-Time Robust Neural Network Output Enhancement for Active Lane Detection
Abstract Slides Poster Similar
Tracking Fast Moving Objects by Segmentation Network

Auto-TLDR; Fast Moving Objects Tracking by Segmentation Using Deep Learning
Abstract Slides Poster Similar
Effective Deployment of CNNs for 3DoF Pose Estimation and Grasping in Industrial Settings
Daniele De Gregorio, Riccardo Zanella, Gianluca Palli, Luigi Di Stefano

Auto-TLDR; Automated Deep Learning for Robotic Grasping Applications
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
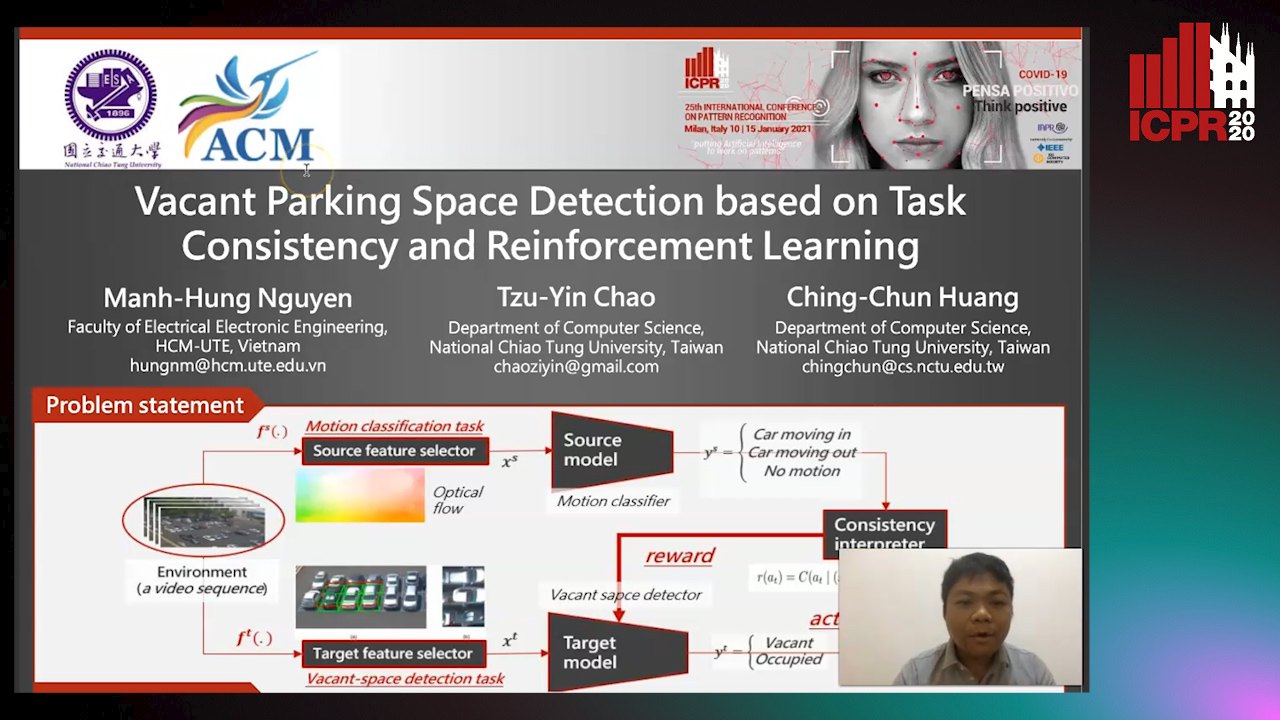
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
LFIR2Pose: Pose Estimation from an Extremely Low-Resolution FIR Image Sequence
Saki Iwata, Yasutomo Kawanishi, Daisuke Deguchi, Ichiro Ide, Hiroshi Murase, Tomoyoshi Aizawa

Auto-TLDR; LFIR2Pose: Human Pose Estimation from a Low-Resolution Far-InfraRed Image Sequence
Abstract Slides Poster Similar
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Gibran Benitez-Garcia, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; IPN Hand: A Benchmark Dataset for Continuous Hand Gesture Recognition
Abstract Slides Poster Similar
Unsupervised Moving Object Detection through Background Models for PTZ Camera
Kimin Yun, Hyung-Il Kim, Kangmin Bae, Jongyoul Park

Auto-TLDR; Unsupervised Moving Object Detection in a PTZ Camera through Two Background Models
Abstract Slides Poster Similar
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
Dimche Kostadinov, Davide Scarammuza

Auto-TLDR; Unsupervised Representation Learning from Local Event Data for Pattern Recognition
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Temporal Pulses Driven Spiking Neural Network for Time and Power Efficient Object Recognition in Autonomous Driving
Wei Wang, Shibo Zhou, Jingxi Li, Xiaohua Li, Junsong Yuan, Zhanpeng Jin

Auto-TLDR; Spiking Neural Network for Real-Time Object Recognition on Temporal LiDAR Pulses
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
Real-Time Monocular Depth Estimation with Extremely Light-Weight Neural Network
Mian Jhong Chiu, Wei-Chen Chiu, Hua-Tsung Chen, Jen-Hui Chuang

Auto-TLDR; Real-Time Light-Weight Depth Prediction for Obstacle Avoidance and Environment Sensing with Deep Learning-based CNN
Abstract Slides Poster Similar
Video Analytics Gait Trend Measurement for Fall Prevention and Health Monitoring
Lawrence O'Gorman, Xinyi Liu, Md Imran Sarker, Mariofanna Milanova

Auto-TLDR; Towards Health Monitoring of Gait with Deep Learning
Abstract Slides Poster Similar
Deep Real-Time Hand Detection Using CFPN on Embedded Systems
Pirdiansyah Hendri, Jun-Wei Hsieh, Ping Yang Chen

Auto-TLDR; Concatenated Feature Pyramid Network for Small Hand Detection on Embedded Devices
Abstract Slides Poster Similar
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Maximilian Kraus, Seyed Majid Azimi, Emec Ercelik, Reza Bahmanyar, Peter Reinartz, Alois Knoll

Auto-TLDR; AerialMPTNet: A novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features
Abstract Slides Poster Similar
Anomaly Detection, Localization and Classification for Railway Inspection
Riccardo Gasparini, Andrea D'Eusanio, Guido Borghi, Stefano Pini, Giuseppe Scaglione, Simone Calderara, Eugenio Fedeli, Rita Cucchiara

Auto-TLDR; Anomaly Detection and Localization using thermal images in the lowlight environment
Siamese Fully Convolutional Tracker with Motion Correction
Mathew Francis, Prithwijit Guha

Auto-TLDR; A Siamese Ensemble for Visual Tracking with Appearance and Motion Components
Abstract Slides Poster Similar
Coarse-To-Fine Foreground Segmentation Based on Co-Occurrence Pixel-Block and Spatio-Temporal Attention Model

Auto-TLDR; Foreground Segmentation from coarse to Fine Using Co-occurrence Pixel-Block Model for Dynamic Scene
Abstract Slides Poster Similar
Robust Visual Object Tracking with Two-Stream Residual Convolutional Networks
Ning Zhang, Jingen Liu, Ke Wang, Dan Zeng, Tao Mei

Auto-TLDR; Two-Stream Residual Convolutional Network for Visual Tracking
Abstract Slides Poster Similar
Real Time Fencing Move Classification and Detection at Touch Time During a Fencing Match
Cem Ekin Sunal, Chris G. Willcocks, Boguslaw Obara

Auto-TLDR; Fencing Body Move Classification and Detection Using Deep Learning
Human Segmentation with Dynamic LiDAR Data
Tao Zhong, Wonjik Kim, Masayuki Tanaka, Masatoshi Okutomi

Auto-TLDR; Spatiotemporal Neural Network for Human Segmentation with Dynamic Point Clouds
Deep Gait Relative Attribute Using a Signed Quadratic Contrastive Loss
Yuta Hayashi, Shehata Allam, Yasushi Makihara, Daigo Muramatsu, Yasushi Yagi

Auto-TLDR; Signal-Contrastive Loss for Gait Attributes Estimation
Audio-Video Detection of the Active Speaker in Meetings
Francisco Madrigal, Frederic Lerasle, Lionel Pibre, Isabelle Ferrané

Auto-TLDR; Active Speaker Detection with Visual and Contextual Information from Meeting Context
Abstract Slides Poster Similar
An Adaptive Fusion Model Based on Kalman Filtering and LSTM for Fast Tracking of Road Signs
Chengliang Wang, Xin Xie, Chao Liao

Auto-TLDR; Fusion of ThunderNet and Region Growing Detector for Road Sign Detection and Tracking
Abstract Slides Poster Similar
Semantic Segmentation for Pedestrian Detection from Motion in Temporal Domain

Auto-TLDR; Motion Profile: Recognizing Pedestrians along with their Motion Directions in a Temporal Way
Abstract Slides Poster Similar
Utilising Visual Attention Cues for Vehicle Detection and Tracking
Feiyan Hu, Venkatesh Gurram Munirathnam, Noel E O'Connor, Alan Smeaton, Suzanne Little

Auto-TLDR; Visual Attention for Object Detection and Tracking in Driver-Assistance Systems
Abstract Slides Poster Similar
Fast Approximate Modelling of the Next Combination Result for Stopping the Text Recognition in a Video
Konstantin Bulatov, Nadezhda Fedotova, Vladimir V. Arlazarov

Auto-TLDR; Stopping Video Stream Recognition of a Text Field Using Optimized Computation Scheme
Abstract Slides Poster Similar
TSDM: Tracking by SiamRPN++ with a Depth-Refiner and a Mask-Generator
Pengyao Zhao, Quanli Liu, Wei Wang, Qiang Guo

Auto-TLDR; TSDM: A Depth-D Tracker for 3D Object Tracking
Abstract Slides Poster Similar
Lightweight Low-Resolution Face Recognition for Surveillance Applications
Yoanna Martínez-Díaz, Heydi Mendez-Vazquez, Luis S. Luevano, Leonardo Chang, Miguel Gonzalez-Mendoza

Auto-TLDR; Efficiency of Lightweight Deep Face Networks on Low-Resolution Surveillance Imagery
Abstract Slides Poster Similar
Toward Building a Data-Driven System ForDetecting Mounting Actions of Black Beef Cattle
Yuriko Kawano, Susumu Saito, Nakano Teppei, Ikumi Kondo, Ryota Yamazaki, Hiromi Kusaka, Minoru Sakaguchi, Tetsuji Ogawa

Auto-TLDR; Cattle Mounting Action Detection Using Crowdsourcing and Pattern Recognition
Probability Guided Maxout
Claudio Ferrari, Stefano Berretti, Alberto Del Bimbo

Auto-TLDR; Probability Guided Maxout for CNN Training
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Reducing False Positives in Object Tracking with Siamese Network
Takuya Ogawa, Takashi Shibata, Shoji Yachida, Toshinori Hosoi

Auto-TLDR; Robust Long-Term Object Tracking with Adaptive Search based on Motion Models
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
AttendAffectNet: Self-Attention Based Networks for Predicting Affective Responses from Movies
Thi Phuong Thao Ha, Bt Balamurali, Herremans Dorien, Roig Gemma

Auto-TLDR; AttendAffectNet: A Self-Attention Based Network for Emotion Prediction from Movies
Abstract Slides Poster Similar
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
Uncertainty-Aware Data Augmentation for Food Recognition
Eduardo Aguilar, Bhalaji Nagarajan, Rupali Khatun, Marc Bolaños, Petia Radeva

Auto-TLDR; Data Augmentation for Food Recognition Using Epistemic Uncertainty
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Polarimetric Image Augmentation
Marc Blanchon, Fabrice Meriaudeau, Olivier Morel, Ralph Seulin, Desire Sidibe

Auto-TLDR; Polarimetric Augmentation for Deep Learning in Robotics Applications