Efficient High-Resolution High-Level-Semantic Representation Learning for Human Pose Estimation

Auto-TLDR; Spatial enhanced separated temporal spatial convolutional neural network
Similar papers
P2 Net: Augmented Parallel-Pyramid Net for Attention Guided Pose Estimation
Luanxuan Hou, Jie Cao, Yuan Zhao, Haifeng Shen, Jian Tang, Ran He

Auto-TLDR; Parallel-Pyramid Net with Partial Attention for Human Pose Estimation
Abstract Slides Poster Similar
Simple Multi-Resolution Representation Learning for Human Pose Estimation
Trung Tran Quang, Van Giang Nguyen, Daeyoung Kim

Auto-TLDR; Multi-resolution Heatmap Learning for Human Pose Estimation
Abstract Slides Poster Similar
StrongPose: Bottom-up and Strong Keypoint Heat Map Based Pose Estimation

Auto-TLDR; StrongPose: A bottom-up box-free approach for human pose estimation and action recognition
Abstract Slides Poster Similar
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Semantic Segmentation
Zhuoying Wang, Yongtao Wang, Zhi Tang, Yangyan Li, Ying Chen, Haibin Ling, Weisi Lin

Auto-TLDR; Gated Scale-Transfer Operation for Semantic Segmentation
Abstract Slides Poster Similar
Bidirectional Matrix Feature Pyramid Network for Object Detection

Auto-TLDR; BMFPN: Bidirectional Matrix Feature Pyramid Network for Object Detection
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
PRF-Ped: Multi-Scale Pedestrian Detector with Prior-Based Receptive Field
Yuzhi Tan, Hongxun Yao, Haoran Li, Xiusheng Lu, Haozhe Xie

Auto-TLDR; Bidirectional Feature Enhancement Module for Multi-Scale Pedestrian Detection
Abstract Slides Poster Similar
Enhanced Feature Pyramid Network for Semantic Segmentation
Mucong Ye, Ouyang Jinpeng, Ge Chen, Jing Zhang, Xiaogang Yu

Auto-TLDR; EFPN: Enhanced Feature Pyramid Network for Semantic Segmentation
Abstract Slides Poster Similar
Tilting at Windmills: Data Augmentation for Deeppose Estimation Does Not Help with Occlusions
Rafal Pytel, Osman Semih Kayhan, Jan Van Gemert

Auto-TLDR; Targeted Keypoint and Body Part Occlusion Attacks for Human Pose Estimation
Abstract Slides Poster Similar
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
Context-Aware Residual Module for Image Classification

Auto-TLDR; Context-Aware Residual Module for Image Classification
Abstract Slides Poster Similar
SFPN: Semantic Feature Pyramid Network for Object Detection

Auto-TLDR; SFPN: Semantic Feature Pyramid Network to Address Information Dilution Issue in FPN
Abstract Slides Poster Similar
Light3DPose: Real-Time Multi-Person 3D Pose Estimation from Multiple Views
Alessio Elmi, Davide Mazzini, Pietro Tortella

Auto-TLDR; 3D Pose Estimation of Multiple People from a Few calibrated Camera Views using Deep Learning
Abstract Slides Poster Similar
Efficient Grouping for Keypoint Detection
Alexey Sidnev, Ekaterina Krasikova, Maxim Kazakov
Auto-TLDR; Automatic Keypoint Grouping for DeepFashion2 Dataset
Abstract Slides Poster Similar
Learning a Dynamic High-Resolution Network for Multi-Scale Pedestrian Detection
Mengyuan Ding, Shanshan Zhang, Jian Yang

Auto-TLDR; Learningable Dynamic HRNet for Pedestrian Detection
Abstract Slides Poster Similar
Multi-Direction Convolution for Semantic Segmentation
Dehui Li, Zhiguo Cao, Ke Xian, Xinyuan Qi, Chao Zhang, Hao Lu

Auto-TLDR; Multi-Direction Convolution for Contextual Segmentation
Real-Time Semantic Segmentation Via Region and Pixel Context Network
Yajun Li, Yazhou Liu, Quansen Sun

Auto-TLDR; A Dual Context Network for Real-Time Semantic Segmentation
Abstract Slides Poster Similar
RefiNet: 3D Human Pose Refinement with Depth Maps
Andrea D'Eusanio, Stefano Pini, Guido Borghi, Roberto Vezzani, Rita Cucchiara

Auto-TLDR; RefiNet: A Multi-stage Framework for 3D Human Pose Estimation
HPERL: 3D Human Pose Estimastion from RGB and LiDAR
Michael Fürst, Shriya T.P. Gupta, René Schuster, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; 3D Human Pose Estimation Using RGB and LiDAR Using Weakly-Supervised Approach
Abstract Slides Poster Similar
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Renshu Gu, Gaoang Wang, Jenq-Neng Hwang

Auto-TLDR; 3D Human Pose Estimation for Multi-Human Videos with Occlusion
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
Spatial-Related and Scale-Aware Network for Crowd Counting
Lei Li, Yuan Dong, Hongliang Bai

Auto-TLDR; Spatial Attention for Crowd Counting
Abstract Slides Poster Similar
Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation
Jing Liu, Xiaona Zhang, Zhaoxin Li, Tianlu Mao

Auto-TLDR; Multi-scale Residual Pyramid Attention Network for Monocular Depth Estimation
Abstract Slides Poster Similar
Orthographic Projection Linear Regression for Single Image 3D Human Pose Estimation
Yahui Zhang, Shaodi You, Theo Gevers

Auto-TLDR; A Deep Neural Network for 3D Human Pose Estimation from a Single 2D Image in the Wild
Abstract Slides Poster Similar
Attention Stereo Matching Network
Doudou Zhang, Jing Cai, Yanbing Xue, Zan Gao, Hua Zhang

Auto-TLDR; ASM-Net: Attention Stereo Matching with Disparity Refinement
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
CenterRepp: Predict Central Representative Point Set's Distribution for Detection
Yulin He, Limeng Zhang, Wei Chen, Xin Luo, Chen Li, Xiaogang Jia

Auto-TLDR; CRPDet: CenterRepp Detector for Object Detection
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Fast and Accurate Real-Time Semantic Segmentation with Dilated Asymmetric Convolutions
Leonel Rosas-Arias, Gibran Benitez-Garcia, Jose Portillo-Portillo, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; FASSD-Net: Dilated Asymmetric Pyramidal Fusion for Real-Time Semantic Segmentation
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
Temporal Attention-Augmented Graph Convolutional Network for Efficient Skeleton-Based Human Action Recognition
Negar Heidari, Alexandros Iosifidis

Auto-TLDR; Temporal Attention Module for Efficient Graph Convolutional Network-based Action Recognition
Abstract Slides Poster Similar
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Pongpisit Thanasutives, Ken-Ichi Fukui, Masayuki Numao, Boonserm Kijsirikul

Auto-TLDR; M-SFANet and M-SegNet for Crowd Counting Using Multi-Scale Fusion Networks
Abstract Slides Poster Similar
Small Object Detection by Generative and Discriminative Learning
Yi Gu, Jie Li, Chentao Wu, Weijia Jia, Jianping Chen

Auto-TLDR; Generative and Discriminative Learning for Small Object Detection
Abstract Slides Poster Similar
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
A Multi-Task Neural Network for Action Recognition with 3D Key-Points
Rongxiao Tang, Wang Luyang, Zhenhua Guo

Auto-TLDR; Multi-task Neural Network for Action Recognition and 3D Human Pose Estimation
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
Nighttime Pedestrian Detection Based on Feature Attention and Transformation
Gang Li, Shanshan Zhang, Jian Yang

Auto-TLDR; FAM and FTM: Enhanced Feature Attention Module and Feature Transformation Module for nighttime pedestrian detection
Abstract Slides Poster Similar
FastCompletion: A Cascade Network with Multiscale Group-Fused Inputs for Real-Time Depth Completion
Ang Li, Zejian Yuan, Yonggen Ling, Wanchao Chi, Shenghao Zhang, Chong Zhang

Auto-TLDR; Efficient Depth Completion with Clustered Hourglass Networks
Abstract Slides Poster Similar
PEAN: 3D Hand Pose Estimation Adversarial Network
Linhui Sun, Yifan Zhang, Jing Lu, Jian Cheng, Hanqing Lu

Auto-TLDR; PEAN: 3D Hand Pose Estimation with Adversarial Learning Framework
Abstract Slides Poster Similar
Learning to Implicitly Represent 3D Human Body from Multi-Scale Features and Multi-View Images
Zhongguo Li, Magnus Oskarsson, Anders Heyden

Auto-TLDR; Reconstruction of 3D human bodies from multi-view images using multi-stage end-to-end neural networks
Abstract Slides Poster Similar
Deeply-Fused Attentive Network for Stereo Matching
Zuliu Yang, Xindong Ai, Weida Yang, Yong Zhao, Qifei Dai, Fuchi Li

Auto-TLDR; DF-Net: Deep Learning-based Network for Stereo Matching
Abstract Slides Poster Similar
HANet: Hybrid Attention-Aware Network for Crowd Counting
Xinxing Su, Yuchen Yuan, Xiangbo Su, Zhikang Zou, Shilei Wen, Pan Zhou

Auto-TLDR; HANet: Hybrid Attention-Aware Network for Crowd Counting with Adaptive Compensation Loss
Image-Based Table Cell Detection: A New Dataset and an Improved Detection Method
Dafeng Wei, Hongtao Lu, Yi Zhou, Kai Chen

Auto-TLDR; TableCell: A Semi-supervised Dataset for Table-wise Detection and Recognition
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
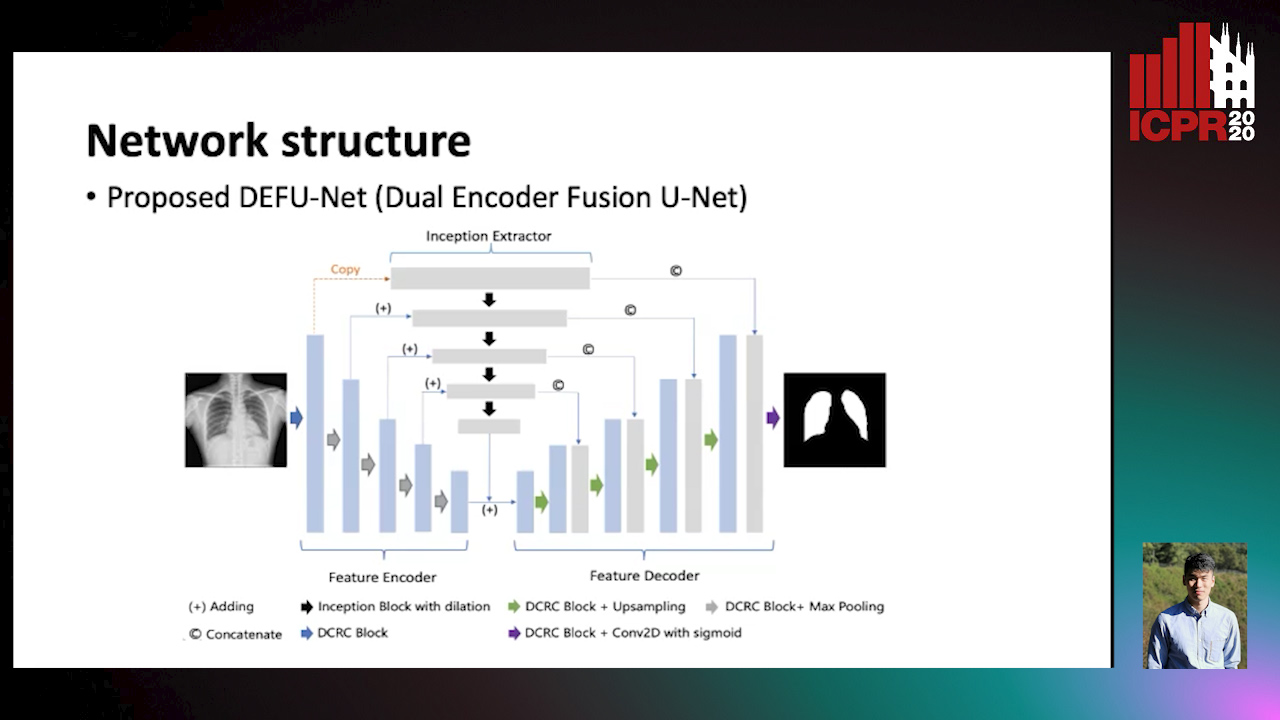
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
DeepPear: Deep Pose Estimation and Action Recognition
Wen-Jiin Tsai, You-Ying Jhuang

Auto-TLDR; Human Action Recognition Using RGB Video Using 3D Human Pose and Appearance Features
Abstract Slides Poster Similar
ScarfNet: Multi-Scale Features with Deeply Fused and Redistributed Semantics for Enhanced Object Detection
Jin Hyeok Yoo, Dongsuk Kum, Jun Won Choi

Auto-TLDR; Semantic Fusion of Multi-scale Feature Maps for Object Detection
Abstract Slides Poster Similar