Progressive Adversarial Semantic Segmentation
Abdullah-Al-Zubaer Imran,
Demetri Terzopoulos

Auto-TLDR; Progressive Adversarial Semantic Segmentation for End-to-End Medical Image Segmenting
Similar papers
MTGAN: Mask and Texture-Driven Generative Adversarial Network for Lung Nodule Segmentation
Wei Chen, Qiuli Wang, Kun Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; Mask and Texture-driven Generative Adversarial Network for Lung Nodule Segmentation
Abstract Slides Poster Similar
Transfer Learning through Weighted Loss Function and Group Normalization for Vessel Segmentation from Retinal Images
Abdullah Sarhan, Jon Rokne, Reda Alhajj, Andrew Crichton

Auto-TLDR; Deep Learning for Segmentation of Blood Vessels in Retinal Images
Abstract Slides Poster Similar
Semi-Supervised Generative Adversarial Networks with a Pair of Complementary Generators for Retinopathy Screening
Yingpeng Xie, Qiwei Wan, Hai Xie, En-Leng Tan, Yanwu Xu, Baiying Lei

Auto-TLDR; Generative Adversarial Networks for Retinopathy Diagnosis via Fundus Images
Abstract Slides Poster Similar
Unsupervised Domain Adaptation with Multiple Domain Discriminators and Adaptive Self-Training
Teo Spadotto, Marco Toldo, Umberto Michieli, Pietro Zanuttigh

Auto-TLDR; Unsupervised Domain Adaptation for Semantic Segmentation of Urban Scenes
Abstract Slides Poster Similar
Learn to Segment Retinal Lesions and Beyond
Qijie Wei, Xirong Li, Weihong Yu, Xiao Zhang, Yongpeng Zhang, Bojie Hu, Bin Mo, Di Gong, Ning Chen, Dayong Ding, Youxin Chen

Auto-TLDR; Multi-task Lesion Segmentation and Disease Classification for Diabetic Retinopathy Grading
PCANet: Pyramid Context-Aware Network for Retinal Vessel Segmentation
Yi Zhang, Yixuan Chen, Kai Zhang

Auto-TLDR; PCANet: Adaptive Context-Aware Network for Automated Retinal Vessel Segmentation
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation
Changlu Guo, Marton Szemenyei, Yugen Yi, Wenle Wang, Buer Chen, Changqi Fan

Auto-TLDR; Spatial Attention U-Net for Segmentation of Retinal Blood Vessels
Abstract Slides Poster Similar
BG-Net: Boundary-Guided Network for Lung Segmentation on Clinical CT Images
Rui Xu, Yi Wang, Tiantian Liu, Xinchen Ye, Lin Lin, Yen-Wei Chen, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; Boundary-Guided Network for Lung Segmentation on CT Images
Abstract Slides Poster Similar
Segmentation of Intracranial Aneurysm Remnant in MRA Using Dual-Attention Atrous Net
Subhashis Banerjee, Ashis Kumar Dhara, Johan Wikström, Robin Strand

Auto-TLDR; Dual-Attention Atrous Net for Segmentation of Intracranial Aneurysm Remnant from MRA Images
Abstract Slides Poster Similar
NephCNN: A Deep-Learning Framework for Vessel Segmentation in Nephrectomy Laparoscopic Videos
Alessandro Casella, Sara Moccia, Chiara Carlini, Emanuele Frontoni, Elena De Momi, Leonardo Mattos

Auto-TLDR; Adversarial Fully Convolutional Neural Networks for kidney vessel segmentation from nephrectomy laparoscopic videos
Abstract Slides Poster Similar
BiLuNet: A Multi-Path Network for Semantic Segmentation on X-Ray Images
Van Luan Tran, Huei-Yung Lin, Rachel Liu, Chun-Han Tseng, Chun-Han Tseng

Auto-TLDR; BiLuNet: Multi-path Convolutional Neural Network for Semantic Segmentation of Lumbar vertebrae, sacrum,
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
Unsupervised Detection of Pulmonary Opacities for Computer-Aided Diagnosis of COVID-19 on CT Images
Rui Xu, Xiao Cao, Yufeng Wang, Yen-Wei Chen, Xinchen Ye, Lin Lin, Wenchao Zhu, Chao Chen, Fangyi Xu, Yong Zhou, Hongjie Hu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A computer-aided diagnosis of COVID-19 from CT images using unsupervised pulmonary opacity detection
Abstract Slides Poster Similar
Unsupervised Multi-Task Domain Adaptation

Auto-TLDR; Unsupervised Domain Adaptation with Multi-task Learning for Image Recognition
Abstract Slides Poster Similar
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Martin Kolarik, Radim Burget, Carlos M. Travieso-Gonzalez, Jan Kocica

Auto-TLDR; Planar 3D Res-U-Net Network for Unbalanced 3D Image Segmentation using Fluid Attenuation Inversion Recover
CAggNet: Crossing Aggregation Network for Medical Image Segmentation

Auto-TLDR; Crossing Aggregation Network for Medical Image Segmentation
Abstract Slides Poster Similar
Robust Localization of Retinal Lesions Via Weakly-Supervised Learning

Auto-TLDR; Weakly Learning of Lesions in Fundus Images Using Multi-level Feature Maps and Classification Score
Abstract Slides Poster Similar
Cross-Domain Semantic Segmentation of Urban Scenes Via Multi-Level Feature Alignment
Bin Zhang, Shengjie Zhao, Rongqing Zhang

Auto-TLDR; Cross-Domain Semantic Segmentation Using Generative Adversarial Networks
Abstract Slides Poster Similar
Shape Consistent 2D Keypoint Estimation under Domain Shift
Levi Vasconcelos, Massimiliano Mancini, Davide Boscaini, Barbara Caputo, Elisa Ricci

Auto-TLDR; Deep Adaptation for Keypoint Prediction under Domain Shift
Abstract Slides Poster Similar
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar
Foreground-Focused Domain Adaption for Object Detection

Auto-TLDR; Unsupervised Domain Adaptation for Unsupervised Object Detection
Learning to Segment Clustered Amoeboid Cells from Brightfield Microscopy Via Multi-Task Learning with Adaptive Weight Selection
Rituparna Sarkar, Suvadip Mukherjee, Elisabeth Labruyere, Jean-Christophe Olivo-Marin

Auto-TLDR; Supervised Cell Segmentation from Microscopy Images using Multi-task Learning in a Multi-Task Learning Paradigm
Deep Recurrent-Convolutional Model for AutomatedSegmentation of Craniomaxillofacial CT Scans
Francesca Murabito, Simone Palazzo, Federica Salanitri Proietto, Francesco Rundo, Ulas Bagci, Daniela Giordano, Rosalia Leonardi, Concetto Spampinato

Auto-TLDR; Automated Segmentation of Anatomical Structures in Craniomaxillofacial CT Scans using Fully Convolutional Deep Networks
Abstract Slides Poster Similar
BCAU-Net: A Novel Architecture with Binary Channel Attention Module for MRI Brain Segmentation
Yongpei Zhu, Zicong Zhou, Guojun Liao, Kehong Yuan

Auto-TLDR; BCAU-Net: Binary Channel Attention U-Net for MRI brain segmentation
Abstract Slides Poster Similar
Semi-Supervised Domain Adaptation Via Selective Pseudo Labeling and Progressive Self-Training

Auto-TLDR; Semi-supervised Domain Adaptation with Pseudo Labels
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
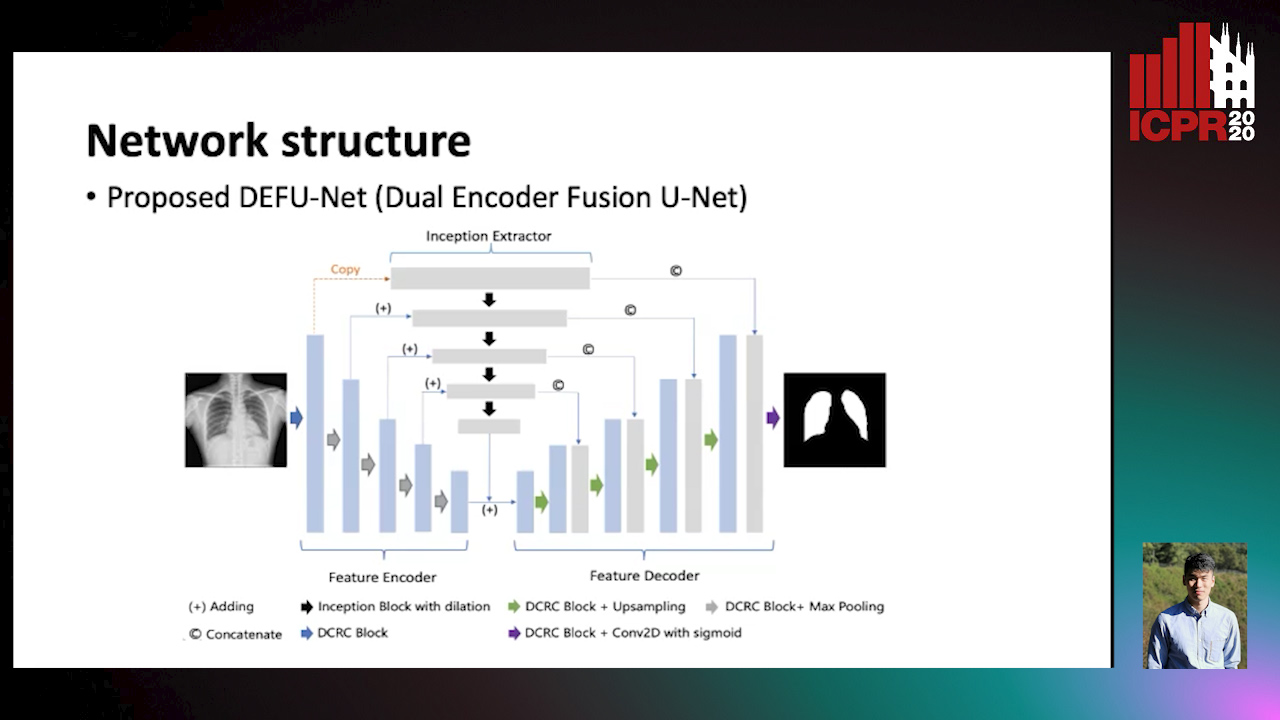
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
Do Not Treat Boundaries and Regions Differently: An Example on Heart Left Atrial Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; Attention Full Convolutional Network for Atrial Segmentation using ResNet-101 Architecture
Attention2AngioGAN: Synthesizing Fluorescein Angiography from Retinal Fundus Images Using Generative Adversarial Networks
Sharif Amit Kamran, Khondker Fariha Hossain, Alireza Tavakkoli, Stewart Lee Zuckerbrod

Auto-TLDR; Fluorescein Angiography from Fundus Images using Attention-based Generative Networks
Abstract Slides Poster Similar
Dealing with Scarce Labelled Data: Semi-Supervised Deep Learning with Mix Match for Covid-19 Detection Using Chest X-Ray Images
Saúl Calderón Ramirez, Raghvendra Giri, Shengxiang Yang, Armaghan Moemeni, Mario Umaña, David Elizondo, Jordina Torrents-Barrena, Miguel A. Molina-Cabello

Auto-TLDR; Semi-supervised Deep Learning for Covid-19 Detection using Chest X-rays
Abstract Slides Poster Similar
Efficient Shadow Detection and Removal Using Synthetic Data with Domain Adaptation
Rui Guo, Babajide Ayinde, Hao Sun

Auto-TLDR; Shadow Detection and Removal with Domain Adaptation and Synthetic Image Database
Energy-Constrained Self-Training for Unsupervised Domain Adaptation
Xiaofeng Liu, Xiongchang Liu, Bo Hu, Jun Lu, Jonghye Woo, Jane You

Auto-TLDR; Unsupervised Domain Adaptation with Energy Function Minimization
Abstract Slides Poster Similar
Joint Supervised and Self-Supervised Learning for 3D Real World Challenges
Antonio Alliegro, Davide Boscaini, Tatiana Tommasi

Auto-TLDR; Self-supervision for 3D Shape Classification and Segmentation in Point Clouds
A Transformer-Based Network for Anisotropic 3D Medical Image Segmentation
Guo Danfeng, Demetri Terzopoulos

Auto-TLDR; A transformer-based model to tackle the anisotropy problem in 3D medical image analysis
Abstract Slides Poster Similar
Teacher-Student Competition for Unsupervised Domain Adaptation
Ruixin Xiao, Zhilei Liu, Baoyuan Wu

Auto-TLDR; Unsupervised Domain Adaption with Teacher-Student Competition
Abstract Slides Poster Similar
Self-Supervised Domain Adaptation with Consistency Training
Liang Xiao, Jiaolong Xu, Dawei Zhao, Zhiyu Wang, Li Wang, Yiming Nie, Bin Dai

Auto-TLDR; Unsupervised Domain Adaptation for Image Classification
Abstract Slides Poster Similar
Enlarging Discriminative Power by Adding an Extra Class in Unsupervised Domain Adaptation
Hai Tran, Sumyeong Ahn, Taeyoung Lee, Yung Yi

Auto-TLDR; Unsupervised Domain Adaptation using Artificial Classes
Abstract Slides Poster Similar
Mask-Based Style-Controlled Image Synthesis Using a Mask Style Encoder
Jaehyeong Cho, Wataru Shimoda, Keiji Yanai

Auto-TLDR; Style-controlled Image Synthesis from Semantic Segmentation masks using GANs
Abstract Slides Poster Similar
GAP: Quantifying the Generative Adversarial Set and Class Feature Applicability of Deep Neural Networks
Edward Collier, Supratik Mukhopadhyay

Auto-TLDR; Approximating Adversarial Learning in Deep Neural Networks Using Set and Class Adversaries
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
DARN: Deep Attentive Refinement Network for Liver Tumor Segmentation from 3D CT Volume
Yao Zhang, Jiang Tian, Cheng Zhong, Yang Zhang, Zhongchao Shi, Zhiqiang He

Auto-TLDR; Deep Attentive Refinement Network for Liver Tumor Segmentation from 3D Computed Tomography Using Multi-Level Features
Abstract Slides Poster Similar
OCT Image Segmentation Using NeuralArchitecture Search and SRGAN
Saba Heidari, Omid Dehzangi, Nasser M. Nasarabadi, Ali Rezai

Auto-TLDR; Automatic Segmentation of Retinal Layers in Optical Coherence Tomography using Neural Architecture Search
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
Fine-Tuning Convolutional Neural Networks: A Comprehensive Guide and Benchmark Analysis for Glaucoma Screening
Amed Mvoulana, Rostom Kachouri, Mohamed Akil

Auto-TLDR; Fine-tuning Convolutional Neural Networks for Glaucoma Screening
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Aerial Road Segmentation in the Presence of Topological Label Noise
Corentin Henry, Friedrich Fraundorfer, Eleonora Vig

Auto-TLDR; Improving Road Segmentation with Noise-Aware U-Nets for Fine-Grained Topology delineation
Abstract Slides Poster Similar