Multi-Scale Deep Pixel Distribution Learning for Concrete Crack Detection
Xuanyi Wu,
Jianfei Ma,
Yu Sun,
Chenqiu Zhao,
Anup Basu

Auto-TLDR; Multi-scale Deep Learning for Concrete Crack Detection
Similar papers
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
A Versatile Crack Inspection Portable System Based on Classifier Ensemble and Controlled Illumination
Milind Gajanan Padalkar, Carlos Beltran-Gonzalez, Matteo Bustreo, Alessio Del Bue, Vittorio Murino

Auto-TLDR; Lighting Conditions for Crack Detection in Ceramic Tile
Abstract Slides Poster Similar
Crack Detection As a Weakly-Supervised Problem: Towards Achieving Less Annotation-Intensive Crack Detectors

Auto-TLDR; A Weakly-supervised Framework for Automatic Crack Detection
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
CT-UNet: An Improved Neural Network Based on U-Net for Building Segmentation in Remote Sensing Images
Huanran Ye, Sheng Liu, Kun Jin, Haohao Cheng

Auto-TLDR; Context-Transfer-UNet: A UNet-based Network for Building Segmentation in Remote Sensing Images
Abstract Slides Poster Similar
Attention Based Coupled Framework for Road and Pothole Segmentation
Shaik Masihullah, Ritu Garg, Prerana Mukherjee, Anupama Ray

Auto-TLDR; Few Shot Learning for Road and Pothole Segmentation on KITTI and IDD
Abstract Slides Poster Similar
Aerial Road Segmentation in the Presence of Topological Label Noise
Corentin Henry, Friedrich Fraundorfer, Eleonora Vig

Auto-TLDR; Improving Road Segmentation with Noise-Aware U-Nets for Fine-Grained Topology delineation
Abstract Slides Poster Similar
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
Lane Detection Based on Object Detection and Image-To-Image Translation
Hiroyuki Komori, Kazunori Onoguchi

Auto-TLDR; Lane Marking and Road Boundary Detection from Monocular Camera Images using Inverse Perspective Mapping
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Enhancing Semantic Segmentation of Aerial Images with Inhibitory Neurons
Ihsan Ullah, Sean Reilly, Michael Madden

Auto-TLDR; Lateral Inhibition in Deep Neural Networks for Object Recognition and Semantic Segmentation
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Complex-Object Visual Inspection: Empirical Studies on a Multiple Lighting Solution
Maya Aghaei, Matteo Bustreo, Pietro Morerio, Nicolò Carissimi, Alessio Del Bue, Vittorio Murino

Auto-TLDR; A Novel Illumination Setup for Automatic Visual Inspection of Complex Objects
Abstract Slides Poster Similar
Mobile Phone Surface Defect Detection Based on Improved Faster R-CNN
Tao Wang, Can Zhang, Runwei Ding, Ge Yang

Auto-TLDR; Faster R-CNN for Mobile Phone Surface Defect Detection
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
A Novel Disaster Image Data-Set and Characteristics Analysis Using Attention Model
Fahim Faisal Niloy, Arif ., Abu Bakar Siddik Nayem, Anis Sarker, Ovi Paul, M Ashraful Amin, Amin Ahsan Ali, Moinul Islam Zaber, Akmmahbubur Rahman

Auto-TLDR; Attentive Attention Model for Disaster Classification
Abstract Slides Poster Similar
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
ACRM: Attention Cascade R-CNN with Mix-NMS for Metallic Surface Defect Detection
Junting Fang, Xiaoyang Tan, Yuhui Wang

Auto-TLDR; Attention Cascade R-CNN with Mix Non-Maximum Suppression for Robust Metal Defect Detection
Abstract Slides Poster Similar
Attention Based Multi-Instance Thyroid Cytopathological Diagnosis with Multi-Scale Feature Fusion
Shuhao Qiu, Yao Guo, Chuang Zhu, Wenli Zhou, Huang Chen

Auto-TLDR; A weakly supervised multi-instance learning framework based on attention mechanism with multi-scale feature fusion for thyroid cytopathological diagnosis
Abstract Slides Poster Similar
RescueNet: Joint Building Segmentation and Damage Assessment from Satellite Imagery

Auto-TLDR; RescueNet: End-to-End Building Segmentation and Damage Classification for Humanitarian Aid and Disaster Response
Abstract Slides Poster Similar
Coarse-To-Fine Foreground Segmentation Based on Co-Occurrence Pixel-Block and Spatio-Temporal Attention Model

Auto-TLDR; Foreground Segmentation from coarse to Fine Using Co-occurrence Pixel-Block Model for Dynamic Scene
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
Holistic Grid Fusion Based Stop Line Estimation
Runsheng Xu, Faezeh Tafazzoli, Li Zhang, Timo Rehfeld, Gunther Krehl, Arunava Seal

Auto-TLDR; Fused Multi-Sensory Data for Stop Lines Detection in Intersection Scenarios
Facial Expression Recognition Using Residual Masking Network
Luan Pham, Vu Huynh, Tuan Anh Tran

Auto-TLDR; Deep Residual Masking for Automatic Facial Expression Recognition
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
End-To-End Training of a Two-Stage Neural Network for Defect Detection
Jakob Božič, Domen Tabernik, Danijel Skocaj

Auto-TLDR; End-to-End Training of Segmentation-based Neural Network for Surface Defect Detection
Abstract Slides Poster Similar
Detection and Correspondence Matching of Corneal Reflections for Eye Tracking Using Deep Learning
Soumil Chugh, Braiden Brousseau, Jonathan Rose, Moshe Eizenman

Auto-TLDR; A Fully Convolutional Neural Network for Corneal Reflection Detection and Matching in Extended Reality Eye Tracking Systems
Abstract Slides Poster Similar
Tracking Fast Moving Objects by Segmentation Network

Auto-TLDR; Fast Moving Objects Tracking by Segmentation Using Deep Learning
Abstract Slides Poster Similar
GraphBGS: Background Subtraction Via Recovery of Graph Signals
Jhony Heriberto Giraldo Zuluaga, Thierry Bouwmans

Auto-TLDR; Graph BackGround Subtraction using Graph Signals
Abstract Slides Poster Similar
MRP-Net: A Light Multiple Region Perception Neural Network for Multi-Label AU Detection
Yang Tang, Shuang Chen, Honggang Zhang, Gang Wang, Rui Yang

Auto-TLDR; MRP-Net: A Fast and Light Neural Network for Facial Action Unit Detection
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Accurate Cell Segmentation in Digital Pathology Images Via Attention Enforced Networks
Zeyi Yao, Kaiqi Li, Guanhong Zhang, Yiwen Luo, Xiaoguang Zhou, Muyi Sun

Auto-TLDR; AENet: Attention Enforced Network for Automatic Cell Segmentation
Abstract Slides Poster Similar
Utilising Visual Attention Cues for Vehicle Detection and Tracking
Feiyan Hu, Venkatesh Gurram Munirathnam, Noel E O'Connor, Alan Smeaton, Suzanne Little

Auto-TLDR; Visual Attention for Object Detection and Tracking in Driver-Assistance Systems
Abstract Slides Poster Similar
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
Machine-Learned Regularization and Polygonization of Building Segmentation Masks
Stefano Zorzi, Ksenia Bittner, Friedrich Fraundorfer

Auto-TLDR; Automatic Regularization and Polygonization of Building Segmentation masks using Generative Adversarial Network
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
Transfer Learning through Weighted Loss Function and Group Normalization for Vessel Segmentation from Retinal Images
Abdullah Sarhan, Jon Rokne, Reda Alhajj, Andrew Crichton

Auto-TLDR; Deep Learning for Segmentation of Blood Vessels in Retinal Images
Abstract Slides Poster Similar
Automatically Gather Address Specific Dwelling Images Using Google Street View

Auto-TLDR; Automatic Address Specific Dwelling Image Collection Using Google Street View Data
Abstract Slides Poster Similar
Detecting Marine Species in Echograms Via Traditional, Hybrid, and Deep Learning Frameworks
Porto Marques Tunai, Alireza Rezvanifar, Melissa Cote, Alexandra Branzan Albu, Kaan Ersahin, Todd Mudge, Stephane Gauthier

Auto-TLDR; End-to-End Deep Learning for Echogram Interpretation of Marine Species in Echograms
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
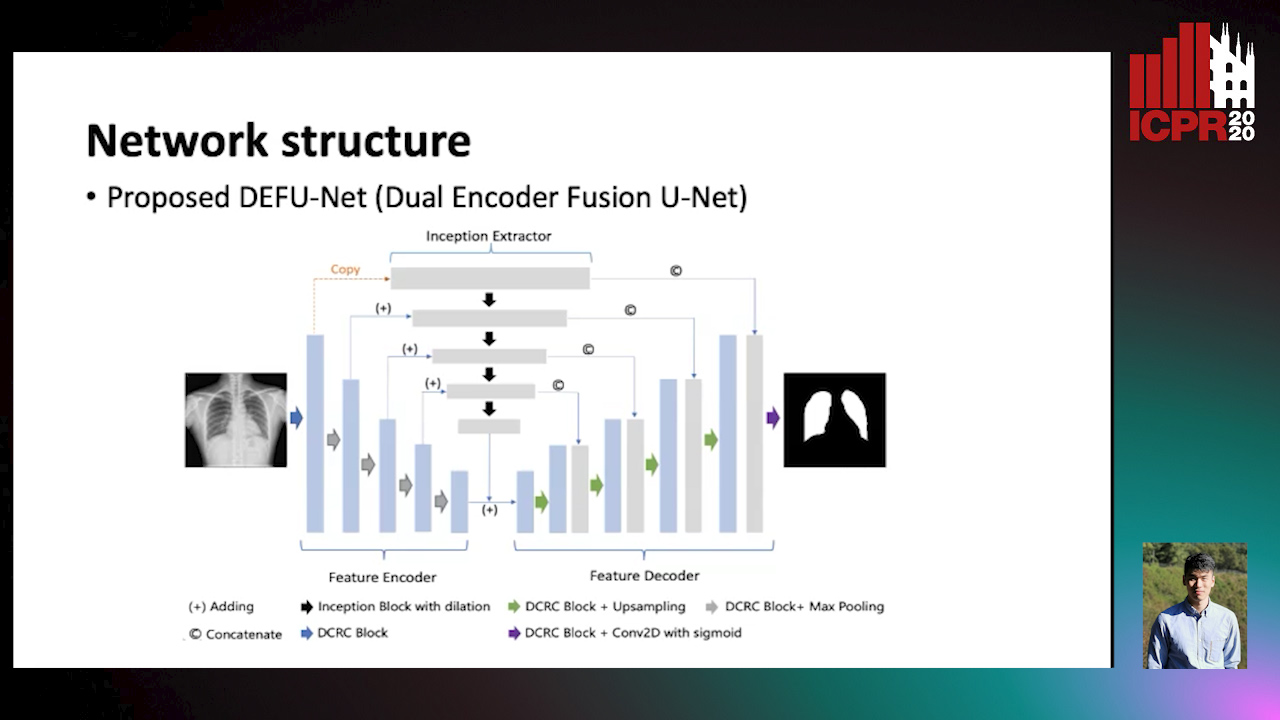
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
Fusion of Global-Local Features for Image Quality Inspection of Shipping Label
Sungho Suh, Paul Lukowicz, Yong Oh Lee

Auto-TLDR; Input Image Quality Verification for Automated Shipping Address Recognition and Verification
Abstract Slides Poster Similar
Video Semantic Segmentation Using Deep Multi-View Representation Learning
Akrem Sellami, Salvatore Tabbone

Auto-TLDR; Deep Multi-view Representation Learning for Video Object Segmentation
Abstract Slides Poster Similar
An Integrated Approach of Deep Learning and Symbolic Analysis for Digital PDF Table Extraction
Mengshi Zhang, Daniel Perelman, Vu Le, Sumit Gulwani

Auto-TLDR; Deep Learning and Symbolic Reasoning for Unstructured PDF Table Extraction
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
PCANet: Pyramid Context-Aware Network for Retinal Vessel Segmentation
Yi Zhang, Yixuan Chen, Kai Zhang

Auto-TLDR; PCANet: Adaptive Context-Aware Network for Automated Retinal Vessel Segmentation
Abstract Slides Poster Similar