Sparse Network Inversion for Key Instance Detection in Multiple Instance Learning
Beomjo Shin,
Junsu Cho,
Hwanjo Yu,
Seungjin Choi

Auto-TLDR; Improving Attention-based Deep Multiple Instance Learning for Key Instance Detection (KID)
Similar papers
Attention Based Multi-Instance Thyroid Cytopathological Diagnosis with Multi-Scale Feature Fusion
Shuhao Qiu, Yao Guo, Chuang Zhu, Wenli Zhou, Huang Chen

Auto-TLDR; A weakly supervised multi-instance learning framework based on attention mechanism with multi-scale feature fusion for thyroid cytopathological diagnosis
Abstract Slides Poster Similar
A New Convex Loss Function for Multiple Instance Support Vector Machines

Auto-TLDR; WR-SVM: A Novel Multiple Instance SVM for Video Classification
Abstract Slides Poster Similar
Deep Multiple Instance Learning with Spatial Attention for ROP Case Classification, Instance Selection and Abnormality Localization
Xirong Li, Wencui Wan, Yang Zhou, Jianchun Zhao, Qijie Wei, Junbo Rong, Pengyi Zhou, Limin Xu, Lijuan Lang, Yuying Liu, Chengzhi Niu, Dayong Ding, Xuemin Jin

Auto-TLDR; MIL-SA: Deep Multiple Instance Learning for Automated Screening of Retinopathy of Prematurity
DA-RefineNet: Dual-Inputs Attention RefineNet for Whole Slide Image Segmentation
Ziqiang Li, Rentuo Tao, Qianrun Wu, Bin Li

Auto-TLDR; DA-RefineNet: A dual-inputs attention network for whole slide image segmentation
Abstract Slides Poster Similar
Classify Breast Histopathology Images with Ductal Instance-Oriented Pipeline
Beibin Li, Ezgi Mercan, Sachin Mehta, Stevan Knezevich, Corey Arnold, Donald Weaver, Joann Elmore, Linda Shapiro

Auto-TLDR; DIOP: Ductal Instance-Oriented Pipeline for Diagnostic Classification
Abstract Slides Poster Similar
Hierarchical Multimodal Attention for Deep Video Summarization
Melissa Sanabria, Frederic Precioso, Thomas Menguy

Auto-TLDR; Automatic Summarization of Professional Soccer Matches Using Event-Stream Data and Multi- Instance Learning
Abstract Slides Poster Similar
Stochastic Runge-Kutta Methods and Adaptive SGD-G2 Stochastic Gradient Descent

Auto-TLDR; Adaptive Stochastic Runge Kutta for the Minimization of the Loss Function
Abstract Slides Poster Similar
IDA-GAN: A Novel Imbalanced Data Augmentation GAN

Auto-TLDR; IDA-GAN: Generative Adversarial Networks for Imbalanced Data Augmentation
Abstract Slides Poster Similar
Self-Supervised Learning with Graph Neural Networks for Region of Interest Retrieval in Histopathology
Yigit Ozen, Selim Aksoy, Kemal Kosemehmetoglu, Sevgen Onder, Aysegul Uner

Auto-TLDR; Self-supervised Contrastive Learning for Deep Representation Learning of Histopathology Images
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
Neuron-Based Network Pruning Based on Majority Voting
Ali Alqahtani, Xianghua Xie, Ehab Essa, Mark W. Jones

Auto-TLDR; Large-Scale Neural Network Pruning using Majority Voting
Abstract Slides Poster Similar
Learning Sparse Deep Neural Networks Using Efficient Structured Projections on Convex Constraints for Green AI
Michel Barlaud, Frederic Guyard

Auto-TLDR; Constrained Deep Neural Network with Constrained Splitting Projection
Abstract Slides Poster Similar
Attack-Agnostic Adversarial Detection on Medical Data Using Explainable Machine Learning
Matthew Watson, Noura Al Moubayed

Auto-TLDR; Explainability-based Detection of Adversarial Samples on EHR and Chest X-Ray Data
Abstract Slides Poster Similar
Ancient Document Layout Analysis: Autoencoders Meet Sparse Coding
Homa Davoudi, Marco Fiorucci, Arianna Traviglia

Auto-TLDR; Unsupervised Unsupervised Representation Learning for Document Layout Analysis
Abstract Slides Poster Similar
Color, Edge, and Pixel-Wise Explanation of Predictions Based onInterpretable Neural Network Model

Auto-TLDR; Explainable Deep Neural Network with Edge Detecting Filters
Multi-Label Contrastive Focal Loss for Pedestrian Attribute Recognition
Xiaoqiang Zheng, Zhenxia Yu, Lin Chen, Fan Zhu, Shilong Wang

Auto-TLDR; Multi-label Contrastive Focal Loss for Pedestrian Attribute Recognition
Abstract Slides Poster Similar
Explainable Feature Embedding Using Convolutional Neural Networks for Pathological Image Analysis
Kazuki Uehara, Masahiro Murakawa, Hirokazu Nosato, Hidenori Sakanashi

Auto-TLDR; Explainable Diagnosis Using Convolutional Neural Networks for Pathological Image Analysis
Abstract Slides Poster Similar
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
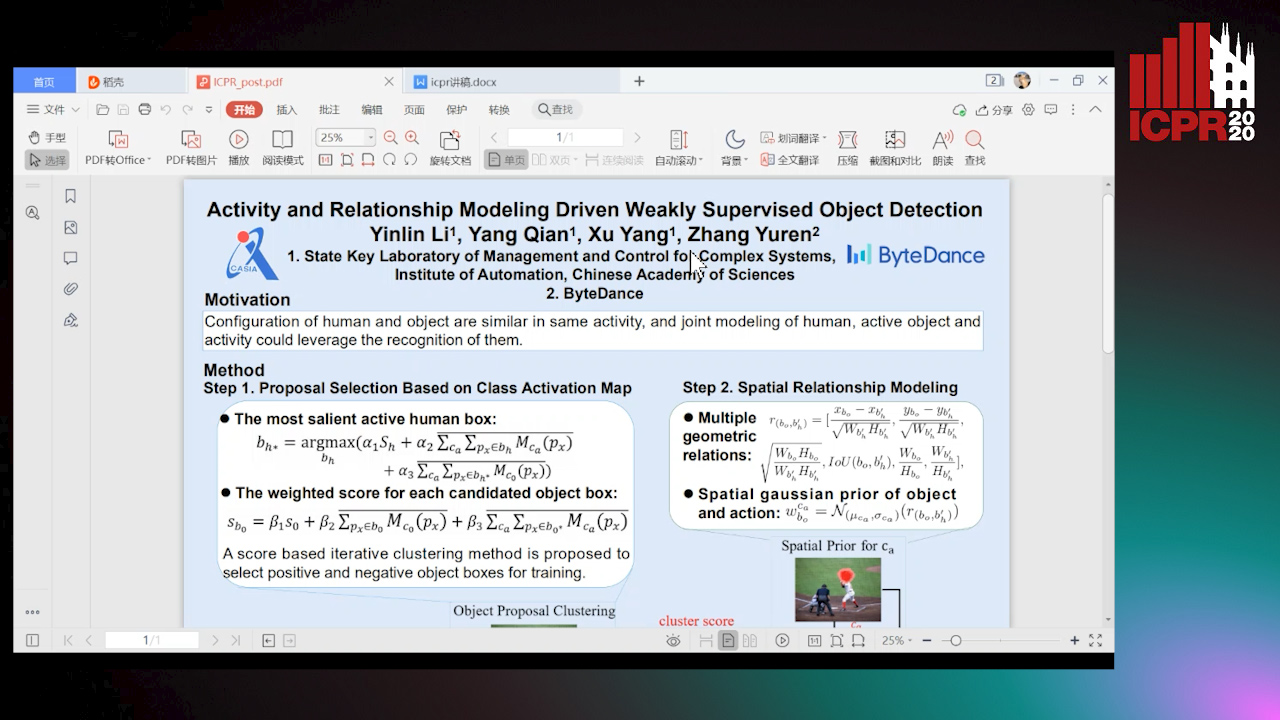
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
Dependently Coupled Principal Component Analysis for Bivariate Inversion Problems
Navdeep Dahiya, Yifei Fan, Samuel Bignardi, Tony Yezzi, Romeil Sandhu

Auto-TLDR; Asymmetric Principal Component Analysis between Paired Data in an Asymmetric manner
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Feature Extraction and Selection Via Robust Discriminant Analysis and Class Sparsity

Auto-TLDR; Hybrid Linear Discriminant Embedding for supervised multi-class classification
Abstract Slides Poster Similar
Discriminative Multi-Level Reconstruction under Compact Latent Space for One-Class Novelty Detection
Jaewoo Park, Yoon Gyo Jung, Andrew Teoh

Auto-TLDR; Discriminative Compact AE for One-Class novelty detection and Adversarial Example Detection
Learning to Segment Clustered Amoeboid Cells from Brightfield Microscopy Via Multi-Task Learning with Adaptive Weight Selection
Rituparna Sarkar, Suvadip Mukherjee, Elisabeth Labruyere, Jean-Christophe Olivo-Marin

Auto-TLDR; Supervised Cell Segmentation from Microscopy Images using Multi-task Learning in a Multi-Task Learning Paradigm
Separation of Aleatoric and Epistemic Uncertainty in Deterministic Deep Neural Networks
Denis Huseljic, Bernhard Sick, Marek Herde, Daniel Kottke

Auto-TLDR; AE-DNN: Modeling Uncertainty in Deep Neural Networks
Abstract Slides Poster Similar
Classification of Intestinal Gland Cell-Graphs Using Graph Neural Networks
Linda Studer, Jannis Wallau, Heather Dawson, Inti Zlobec, Andreas Fischer

Auto-TLDR; Graph Neural Networks for Classification of Dysplastic Gland Glands using Graph Neural Networks
Abstract Slides Poster Similar
Weakly Supervised Learning through Rank-Based Contextual Measures
João Gabriel Camacho Presotto, Lucas Pascotti Valem, Nikolas Gomes De Sá, Daniel Carlos Guimaraes Pedronette, Joao Paulo Papa

Auto-TLDR; Exploiting Unlabeled Data for Weakly Supervised Classification of Multimedia Data
Abstract Slides Poster Similar
Dealing with Scarce Labelled Data: Semi-Supervised Deep Learning with Mix Match for Covid-19 Detection Using Chest X-Ray Images
Saúl Calderón Ramirez, Raghvendra Giri, Shengxiang Yang, Armaghan Moemeni, Mario Umaña, David Elizondo, Jordina Torrents-Barrena, Miguel A. Molina-Cabello

Auto-TLDR; Semi-supervised Deep Learning for Covid-19 Detection using Chest X-rays
Abstract Slides Poster Similar
Improving Model Accuracy for Imbalanced Image Classification Tasks by Adding a Final Batch Normalization Layer: An Empirical Study
Veysel Kocaman, Ofer M. Shir, Thomas Baeck

Auto-TLDR; Exploiting Batch Normalization before the Output Layer in Deep Learning for Minority Class Detection in Imbalanced Data Sets
Abstract Slides Poster Similar
Malware Detection by Exploiting Deep Learning over Binary Programs
Panpan Qi, Zhaoqi Zhang, Wei Wang, Chang Yao

Auto-TLDR; End-to-End Malware Detection without Feature Engineering
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
EasiECG: A Novel Inter-Patient Arrhythmia Classification Method Using ECG Waves
Chuanqi Han, Ruoran Huang, Fang Yu, Xi Huang, Li Cui

Auto-TLDR; EasiECG: Attention-based Convolution Factorization Machines for Arrhythmia Classification
Abstract Slides Poster Similar
Multi-Modal Deep Clustering: Unsupervised Partitioning of Images

Auto-TLDR; Multi-Modal Deep Clustering for Unlabeled Images
Abstract Slides Poster Similar
RNN Training along Locally Optimal Trajectories via Frank-Wolfe Algorithm
Yun Yue, Ming Li, Venkatesh Saligrama, Ziming Zhang

Auto-TLDR; Frank-Wolfe Algorithm for Efficient Training of RNNs
Abstract Slides Poster Similar
Low-Cost Lipschitz-Independent Adaptive Importance Sampling of Stochastic Gradients
Huikang Liu, Xiaolu Wang, Jiajin Li, Man-Cho Anthony So

Auto-TLDR; Adaptive Importance Sampling for Stochastic Gradient Descent
Soft Label and Discriminant Embedding Estimation for Semi-Supervised Classification
Fadi Dornaika, Abdullah Baradaaji, Youssof El Traboulsi

Auto-TLDR; Semi-supervised Semi-Supervised Learning for Linear Feature Extraction and Label Propagation
Abstract Slides Poster Similar
Supporting Skin Lesion Diagnosis with Content-Based Image Retrieval
Stefano Allegretti, Federico Bolelli, Federico Pollastri, Sabrina Longhitano, Giovanni Pellacani, Costantino Grana

Auto-TLDR; Skin Images Retrieval Using Convolutional Neural Networks for Skin Lesion Classification and Segmentation
Abstract Slides Poster Similar
Multi-Scale and Attention Based ResNet for Heartbeat Classification
Haojie Zhang, Gongping Yang, Yuwen Huang, Feng Yuan, Yilong Yin

Auto-TLDR; A Multi-Scale and Attention based ResNet for ECG heartbeat classification in intra-patient and inter-patient paradigms
Abstract Slides Poster Similar
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
Feature-Aware Unsupervised Learning with Joint Variational Attention and Automatic Clustering
Wang Ru, Lin Li, Peipei Wang, Liu Peiyu

Auto-TLDR; Deep Variational Attention Encoder-Decoder for Clustering
Abstract Slides Poster Similar
Evaluation of Anomaly Detection Algorithms for the Real-World Applications
Marija Ivanovska, Domen Tabernik, Danijel Skocaj, Janez Pers

Auto-TLDR; Evaluating Anomaly Detection Algorithms for Practical Applications
Abstract Slides Poster Similar
Investigating and Exploiting Image Resolution for Transfer Learning-Based Skin Lesion Classification
Amirreza Mahbod, Gerald Schaefer, Chunliang Wang, Rupert Ecker, Georg Dorffner, Isabella Ellinger

Auto-TLDR; Fine-tuned Neural Networks for Skin Lesion Classification Using Dermoscopic Images
Abstract Slides Poster Similar
Confidence Calibration for Deep Renal Biopsy Immunofluorescence Image Classification
Federico Pollastri, Juan Maroñas, Federico Bolelli, Giulia Ligabue, Roberto Paredes, Riccardo Magistroni, Costantino Grana

Auto-TLDR; A Probabilistic Convolutional Neural Network for Immunofluorescence Classification in Renal Biopsy
Abstract Slides Poster Similar
The eXPose Approach to Crosslier Detection
Antonio Barata, Frank Takes, Hendrik Van Den Herik, Cor Veenman

Auto-TLDR; EXPose: Crosslier Detection Based on Supervised Category Modeling
Abstract Slides Poster Similar
Deep Ordinal Regression with Label Diversity
Axel Berg, Magnus Oskarsson, Mark Oconnor

Auto-TLDR; Discrete Regression via Classification for Neural Network Learning
An Efficient Empirical Solver for Localized Multiple Kernel Learning Via DNNs

Auto-TLDR; Localized Multiple Kernel Learning using LMKL-Net
Abstract Slides Poster Similar
Image Representation Learning by Transformation Regression
Xifeng Guo, Jiyuan Liu, Sihang Zhou, En Zhu, Shihao Dong

Auto-TLDR; Self-supervised Image Representation Learning using Continuous Parameter Prediction
Abstract Slides Poster Similar
Cross-View Relation Networks for Mammogram Mass Detection
Ma Jiechao, Xiang Li, Hongwei Li, Ruixuan Wang, Bjoern Menze, Wei-Shi Zheng

Auto-TLDR; Multi-view Modeling for Mass Detection in Mammogram
Abstract Slides Poster Similar