Second-Order Attention Guided Convolutional Activations for Visual Recognition
Shannan Chen,
Qian Wang,
Qiule Sun,
Bin Liu,
Jianxin Zhang,
Qiang Zhang

Auto-TLDR; Second-order Attention Guided Network for Convolutional Neural Networks for Visual Recognition
Similar papers
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Attention As Activation
Yimian Dai, Stefan Oehmcke, Fabian Gieseke, Yiquan Wu, Kobus Barnard

Auto-TLDR; Attentional Activation Units for Convolutional Networks
Multi-Order Feature Statistical Model for Fine-Grained Visual Categorization
Qingtao Wang, Ke Zhang, Shaoli Huang, Lianbo Zhang, Jin Fan

Auto-TLDR; Multi-Order Feature Statistical Method for Fine-Grained Visual Categorization
Abstract Slides Poster Similar
Dual-Attention Guided Dropblock Module for Weakly Supervised Object Localization
Junhui Yin, Siqing Zhang, Dongliang Chang, Zhanyu Ma, Jun Guo

Auto-TLDR; Dual-Attention Guided Dropblock for Weakly Supervised Object Localization
Abstract Slides Poster Similar
Improved Residual Networks for Image and Video Recognition
Ionut Cosmin Duta, Li Liu, Fan Zhu, Ling Shao

Auto-TLDR; Residual Networks for Deep Learning
Abstract Slides Poster Similar
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
HANet: Hybrid Attention-Aware Network for Crowd Counting
Xinxing Su, Yuchen Yuan, Xiangbo Su, Zhikang Zou, Shilei Wen, Pan Zhou

Auto-TLDR; HANet: Hybrid Attention-Aware Network for Crowd Counting with Adaptive Compensation Loss
Region-Based Non-Local Operation for Video Classification

Auto-TLDR; Regional-based Non-Local Operation for Deep Self-Attention in Convolutional Neural Networks
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
SCA Net: Sparse Channel Attention Module for Action Recognition
Hang Song, Yonghong Song, Yuanlin Zhang

Auto-TLDR; SCA Net: Efficient Group Convolution for Sparse Channel Attention
Abstract Slides Poster Similar
An Improved Bilinear Pooling Method for Image-Based Action Recognition

Auto-TLDR; An improved bilinear pooling method for image-based action recognition
Abstract Slides Poster Similar
Self and Channel Attention Network for Person Re-Identification
Asad Munir, Niki Martinel, Christian Micheloni

Auto-TLDR; SCAN: Self and Channel Attention Network for Person Re-identification
Abstract Slides Poster Similar
Semantic Bilinear Pooling for Fine-Grained Recognition
Xinjie Li, Chun Yang, Song-Lu Chen, Chao Zhu, Xu-Cheng Yin

Auto-TLDR; Semantic bilinear pooling for fine-grained recognition with hierarchical label tree
Abstract Slides Poster Similar
Context-Aware Residual Module for Image Classification

Auto-TLDR; Context-Aware Residual Module for Image Classification
Abstract Slides Poster Similar
Dynamic Multi-Path Neural Network
Yingcheng Su, Yichao Wu, Ken Chen, Ding Liang, Xiaolin Hu

Auto-TLDR; Dynamic Multi-path Neural Network
WeightAlign: Normalizing Activations by Weight Alignment
Xiangwei Shi, Yunqiang Li, Xin Liu, Jan Van Gemert

Auto-TLDR; WeightAlign: Normalization of Activations without Sample Statistics
Abstract Slides Poster Similar
Transitional Asymmetric Non-Local Neural Networks for Real-World Dirt Road Segmentation

Auto-TLDR; Transitional Asymmetric Non-Local Neural Networks for Semantic Segmentation on Dirt Roads
Abstract Slides Poster Similar
Cross-Layer Information Refining Network for Single Image Super-Resolution
Hongyi Zhang, Wen Lu, Xiaopeng Sun

Auto-TLDR; Interlaced Spatial Attention Block for Single Image Super-Resolution
Abstract Slides Poster Similar
ACRM: Attention Cascade R-CNN with Mix-NMS for Metallic Surface Defect Detection
Junting Fang, Xiaoyang Tan, Yuhui Wang

Auto-TLDR; Attention Cascade R-CNN with Mix Non-Maximum Suppression for Robust Metal Defect Detection
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
Progressive Scene Segmentation Based on Self-Attention Mechanism
Yunyi Pan, Yuan Gan, Kun Liu, Yan Zhang

Auto-TLDR; Two-Stage Semantic Scene Segmentation with Self-Attention
Abstract Slides Poster Similar
Arbitrary Style Transfer with Parallel Self-Attention
Tiange Zhang, Ying Gao, Feng Gao, Lin Qi, Junyu Dong

Auto-TLDR; Self-Attention-Based Arbitrary Style Transfer Using Adaptive Instance Normalization
Abstract Slides Poster Similar
Feature-Dependent Cross-Connections in Multi-Path Neural Networks
Dumindu Tissera, Kasun Vithanage, Rukshan Wijesinghe, Kumara Kahatapitiya, Subha Fernando, Ranga Rodrigo

Auto-TLDR; Multi-path Networks for Adaptive Feature Extraction
Abstract Slides Poster Similar
Attention Stereo Matching Network
Doudou Zhang, Jing Cai, Yanbing Xue, Zan Gao, Hua Zhang

Auto-TLDR; ASM-Net: Attention Stereo Matching with Disparity Refinement
Abstract Slides Poster Similar
Learnable Higher-Order Representation for Action Recognition

Auto-TLDR; Learningable Higher-Order Operations for Spatiotemporal Dynamics in Video Recognition
CQNN: Convolutional Quadratic Neural Networks

Auto-TLDR; Quadratic Neural Network for Image Classification
Abstract Slides Poster Similar
Dynamic Guided Network for Monocular Depth Estimation
Xiaoxia Xing, Yinghao Cai, Yiping Yang, Dayong Wen

Auto-TLDR; DGNet: Dynamic Guidance Upsampling for Self-attention-Decoding for Monocular Depth Estimation
Abstract Slides Poster Similar
Real-Time Semantic Segmentation Via Region and Pixel Context Network
Yajun Li, Yazhou Liu, Quansen Sun

Auto-TLDR; A Dual Context Network for Real-Time Semantic Segmentation
Abstract Slides Poster Similar
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Semantic Segmentation
Zhuoying Wang, Yongtao Wang, Zhi Tang, Yangyan Li, Ying Chen, Haibin Ling, Weisi Lin

Auto-TLDR; Gated Scale-Transfer Operation for Semantic Segmentation
Abstract Slides Poster Similar
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution
Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation
Jing Liu, Xiaona Zhang, Zhaoxin Li, Tianlu Mao

Auto-TLDR; Multi-scale Residual Pyramid Attention Network for Monocular Depth Estimation
Abstract Slides Poster Similar
3D Attention Mechanism for Fine-Grained Classification of Table Tennis Strokes Using a Twin Spatio-Temporal Convolutional Neural Networks
Pierre-Etienne Martin, Jenny Benois-Pineau, Renaud Péteri, Julien Morlier

Auto-TLDR; Attentional Blocks for Action Recognition in Table Tennis Strokes
Abstract Slides Poster Similar
Aggregating Object Features Based on Attention Weights for Fine-Grained Image Retrieval
Hongli Lin, Yongqi Song, Zixuan Zeng, Weisheng Wang

Auto-TLDR; DSAW: Unsupervised Dual-selection for Fine-Grained Image Retrieval
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
DARN: Deep Attentive Refinement Network for Liver Tumor Segmentation from 3D CT Volume
Yao Zhang, Jiang Tian, Cheng Zhong, Yang Zhang, Zhongchao Shi, Zhiqiang He

Auto-TLDR; Deep Attentive Refinement Network for Liver Tumor Segmentation from 3D Computed Tomography Using Multi-Level Features
Abstract Slides Poster Similar
Improving Batch Normalization with Skewness Reduction for Deep Neural Networks
Pak Lun Kevin Ding, Martin Sarah, Baoxin Li

Auto-TLDR; Batch Normalization with Skewness Reduction
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
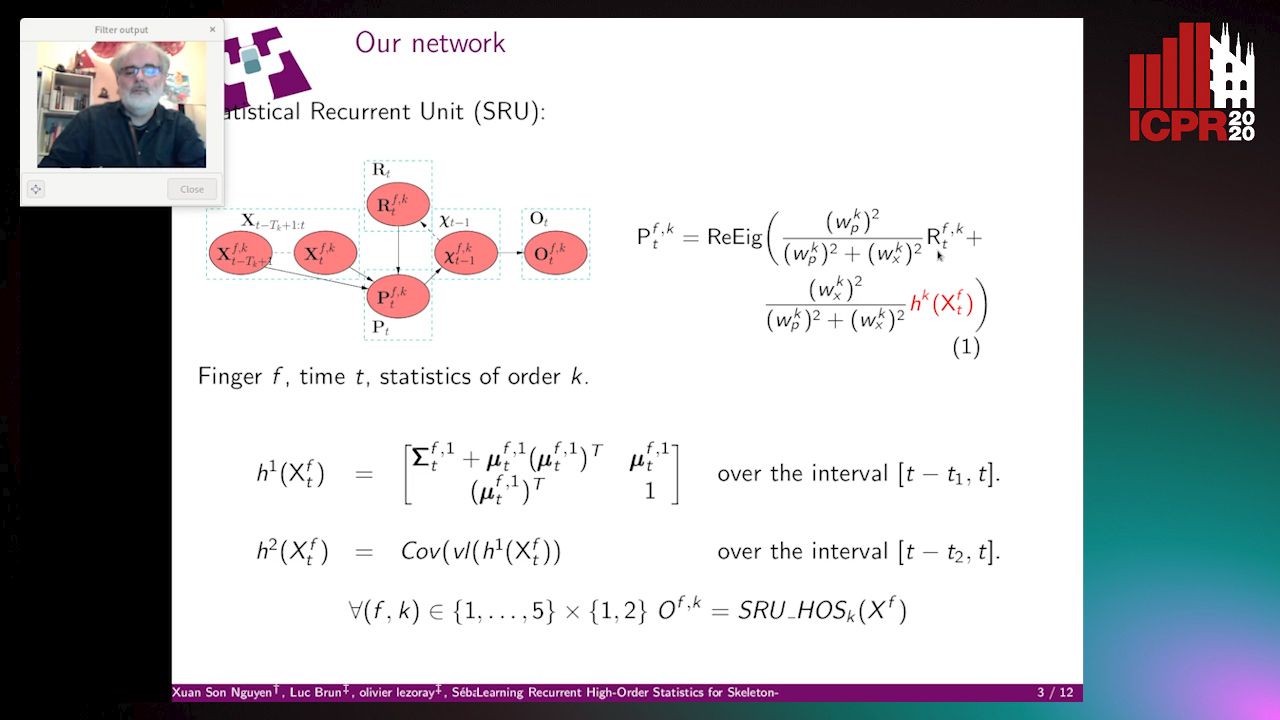
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
Deeply-Fused Attentive Network for Stereo Matching
Zuliu Yang, Xindong Ai, Weida Yang, Yong Zhao, Qifei Dai, Fuchi Li

Auto-TLDR; DF-Net: Deep Learning-based Network for Stereo Matching
Abstract Slides Poster Similar
Channel-Wise Dense Connection Graph Convolutional Network for Skeleton-Based Action Recognition
Michael Lao Banteng, Zhiyong Wu

Auto-TLDR; Two-stream channel-wise dense connection GCN for human action recognition
Abstract Slides Poster Similar
Learn to Segment Retinal Lesions and Beyond
Qijie Wei, Xirong Li, Weihong Yu, Xiao Zhang, Yongpeng Zhang, Bojie Hu, Bin Mo, Di Gong, Ning Chen, Dayong Ding, Youxin Chen

Auto-TLDR; Multi-task Lesion Segmentation and Disease Classification for Diabetic Retinopathy Grading
MFI: Multi-Range Feature Interchange for Video Action Recognition
Sikai Bai, Qi Wang, Xuelong Li

Auto-TLDR; Multi-range Feature Interchange Network for Action Recognition in Videos
Abstract Slides Poster Similar
ScarfNet: Multi-Scale Features with Deeply Fused and Redistributed Semantics for Enhanced Object Detection
Jin Hyeok Yoo, Dongsuk Kum, Jun Won Choi

Auto-TLDR; Semantic Fusion of Multi-scale Feature Maps for Object Detection
Abstract Slides Poster Similar
Collaborative Human Machine Attention Module for Character Recognition
Chetan Ralekar, Tapan Gandhi, Santanu Chaudhury

Auto-TLDR; A Collaborative Human-Machine Attention Module for Deep Neural Networks
Abstract Slides Poster Similar
Ordinal Depth Classification Using Region-Based Self-Attention
Minh Hieu Phan, Son Lam Phung, Abdesselam Bouzerdoum

Auto-TLDR; Region-based Self-Attention for Multi-scale Depth Estimation from a Single 2D Image
Abstract Slides Poster Similar
Fine-Tuning DARTS for Image Classification
Muhammad Suhaib Tanveer, Umar Karim Khan, Chong Min Kyung

Auto-TLDR; Fine-Tune Neural Architecture Search using Fixed Operations
Abstract Slides Poster Similar
FatNet: A Feature-Attentive Network for 3D Point Cloud Processing
Chaitanya Kaul, Nick Pears, Suresh Manandhar

Auto-TLDR; Feature-Attentive Neural Networks for Point Cloud Classification and Segmentation
Image Representation Learning by Transformation Regression
Xifeng Guo, Jiyuan Liu, Sihang Zhou, En Zhu, Shihao Dong

Auto-TLDR; Self-supervised Image Representation Learning using Continuous Parameter Prediction
Abstract Slides Poster Similar