Accurate Background Subtraction Using Dynamic Object Presence Probability in Sports Scenes
Ryosuke Watanabe,
Jun Chen,
Tomoaki Konno,
Sei Naito

Auto-TLDR; DOPP: Dynamic Object Presence Probabilistic Background Subtraction for Foreground Segmentation
Similar papers
Coarse-To-Fine Foreground Segmentation Based on Co-Occurrence Pixel-Block and Spatio-Temporal Attention Model

Auto-TLDR; Foreground Segmentation from coarse to Fine Using Co-occurrence Pixel-Block Model for Dynamic Scene
Abstract Slides Poster Similar
GraphBGS: Background Subtraction Via Recovery of Graph Signals
Jhony Heriberto Giraldo Zuluaga, Thierry Bouwmans

Auto-TLDR; Graph BackGround Subtraction using Graph Signals
Abstract Slides Poster Similar
Unsupervised Moving Object Detection through Background Models for PTZ Camera
Kimin Yun, Hyung-Il Kim, Kangmin Bae, Jongyoul Park

Auto-TLDR; Unsupervised Moving Object Detection in a PTZ Camera through Two Background Models
Abstract Slides Poster Similar
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
Tracking Fast Moving Objects by Segmentation Network

Auto-TLDR; Fast Moving Objects Tracking by Segmentation Using Deep Learning
Abstract Slides Poster Similar
Multi-Camera Sports Players 3D Localization with Identification Reasoning
Yukun Yang, Ruiheng Zhang, Wanneng Wu, Yu Peng, Xu Min

Auto-TLDR; Probabilistic and Identified Occupancy Map for Sports Players 3D Localization
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
Edge-Aware Monocular Dense Depth Estimation with Morphology
Zhi Li, Xiaoyang Zhu, Haitao Yu, Qi Zhang, Yongshi Jiang

Auto-TLDR; Spatio-Temporally Smooth Dense Depth Maps Using Only a CPU
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Video Semantic Segmentation Using Deep Multi-View Representation Learning
Akrem Sellami, Salvatore Tabbone

Auto-TLDR; Deep Multi-view Representation Learning for Video Object Segmentation
Abstract Slides Poster Similar
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Renshu Gu, Gaoang Wang, Jenq-Neng Hwang

Auto-TLDR; 3D Human Pose Estimation for Multi-Human Videos with Occlusion
Reducing False Positives in Object Tracking with Siamese Network
Takuya Ogawa, Takashi Shibata, Shoji Yachida, Toshinori Hosoi

Auto-TLDR; Robust Long-Term Object Tracking with Adaptive Search based on Motion Models
Abstract Slides Poster Similar
Extracting and Interpreting Unknown Factors with Classifier for Foot Strike Types in Running
Chanjin Seo, Masato Sabanai, Yuta Goto, Koji Tagami, Hiroyuki Ogata, Kazuyuki Kanosue, Jun Ohya

Auto-TLDR; Deep Learning for Foot Strike Classification using Accelerometer Data
Abstract Slides Poster Similar
IPT: A Dataset for Identity Preserved Tracking in Closed Domains
Thomas Heitzinger, Martin Kampel

Auto-TLDR; Identity Preserved Tracking Using Depth Data for Privacy and Privacy
Abstract Slides Poster Similar
Image Sequence Based Cyclist Action Recognition Using Multi-Stream 3D Convolution
Stefan Zernetsch, Steven Schreck, Viktor Kress, Konrad Doll, Bernhard Sick

Auto-TLDR; 3D-ConvNet: A Multi-stream 3D Convolutional Neural Network for Detecting Cyclists in Real World Traffic Situations
Abstract Slides Poster Similar
PA-FlowNet: Pose-Auxiliary Optical Flow Network for Spacecraft Relative Pose Estimation
Zhi Yu Chen, Po-Heng Chen, Kuan-Wen Chen, Chen-Yu Chan

Auto-TLDR; PA-FlowNet: An End-to-End Pose-auxiliary Optical Flow Network for Space Travel and Landing
Abstract Slides Poster Similar
Siamese Dynamic Mask Estimation Network for Fast Video Object Segmentation
Dexiang Hong, Guorong Li, Kai Xu, Li Su, Qingming Huang

Auto-TLDR; Siamese Dynamic Mask Estimation for Video Object Segmentation
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Maximilian Kraus, Seyed Majid Azimi, Emec Ercelik, Reza Bahmanyar, Peter Reinartz, Alois Knoll

Auto-TLDR; AerialMPTNet: A novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features
Abstract Slides Poster Similar
Ground-truthing Large Human Behavior Monitoring Datasets
Tehreem Qasim, Robert Fisher, Naeem Bhatti

Auto-TLDR; Semi-automated Groundtruthing for Large Video Datasets
Abstract Slides Poster Similar
Online Object Recognition Using CNN-Based Algorithm on High-Speed Camera Imaging
Shigeaki Namiki, Keiko Yokoyama, Shoji Yachida, Takashi Shibata, Hiroyoshi Miyano, Masatoshi Ishikawa

Auto-TLDR; Real-Time Object Recognition with High-Speed Camera Imaging with Population Data Clearing and Data Ensemble
Abstract Slides Poster Similar
An Adaptive Fusion Model Based on Kalman Filtering and LSTM for Fast Tracking of Road Signs
Chengliang Wang, Xin Xie, Chao Liao

Auto-TLDR; Fusion of ThunderNet and Region Growing Detector for Road Sign Detection and Tracking
Abstract Slides Poster Similar
Learning to Segment Dynamic Objects Using SLAM Outliers
Dupont Romain, Mohamed Tamaazousti, Hervé Le Borgne

Auto-TLDR; Automatic Segmentation of Dynamic Objects Using SLAM Outliers Using Consensus Inversion
Abstract Slides Poster Similar
Learning Defects in Old Movies from Manually Assisted Restoration
Arthur Renaudeau, Travis Seng, Axel Carlier, Jean-Denis Durou, Fabien Pierre, Francois Lauze, Jean-François Aujol

Auto-TLDR; U-Net: Detecting Defects in Old Movies by Inpainting Techniques
Abstract Slides Poster Similar
Real Time Fencing Move Classification and Detection at Touch Time During a Fencing Match
Cem Ekin Sunal, Chris G. Willcocks, Boguslaw Obara

Auto-TLDR; Fencing Body Move Classification and Detection Using Deep Learning
Gender Classification Using Video Sequences of Body Sway Recorded by Overhead Camera
Takuya Kamitani, Yuta Yamaguchi, Shintaro Nakatani, Masashi Nishiyama, Yoshio Iwai

Auto-TLDR; Spatio-Temporal Feature for Gender Classification of a Standing Person Using Body Stance Using Time-Series Signals
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Detecting Anomalies from Video-Sequences: A Novel Descriptor
Giulia Orrù, Davide Ghiani, Maura Pintor, Gian Luca Marcialis, Fabio Roli

Auto-TLDR; Trit-based Measurement of Group Dynamics for Crowd Behavior Analysis and Anomaly Detection
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
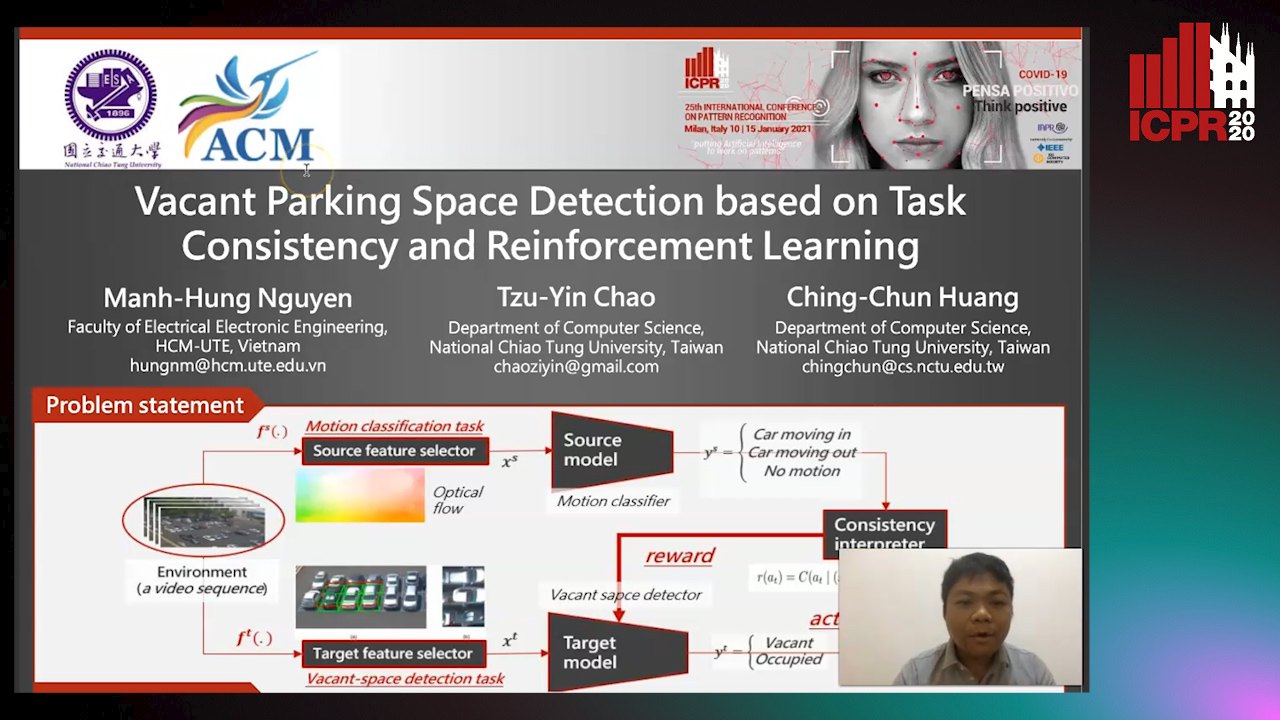
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Pierre Godet, Alexandre Boulch, Aurélien Plyer, Guy Le Besnerais

Auto-TLDR; STaRFlow: A lightweight CNN-based algorithm for optical flow estimation
Abstract Slides Poster Similar
Visual Saliency Oriented Vehicle Scale Estimation
Qixin Chen, Tie Liu, Jiali Ding, Zejian Yuan, Yuanyuan Shang

Auto-TLDR; Regularized Intensity Matching for Vehicle Scale Estimation with salient object detection
Abstract Slides Poster Similar
Video Anomaly Detection by Estimating Likelihood of Representations

Auto-TLDR; Video Anomaly Detection in the latent feature space using a deep probabilistic model
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Utilising Visual Attention Cues for Vehicle Detection and Tracking
Feiyan Hu, Venkatesh Gurram Munirathnam, Noel E O'Connor, Alan Smeaton, Suzanne Little

Auto-TLDR; Visual Attention for Object Detection and Tracking in Driver-Assistance Systems
Abstract Slides Poster Similar
Global Feature Aggregation for Accident Anticipation
Mishal Fatima, Umar Karim Khan, Chong Min Kyung

Auto-TLDR; Feature Aggregation for Predicting Accidents in Video Sequences
LFIR2Pose: Pose Estimation from an Extremely Low-Resolution FIR Image Sequence
Saki Iwata, Yasutomo Kawanishi, Daisuke Deguchi, Ichiro Ide, Hiroshi Murase, Tomoyoshi Aizawa

Auto-TLDR; LFIR2Pose: Human Pose Estimation from a Low-Resolution Far-InfraRed Image Sequence
Abstract Slides Poster Similar
PHNet: Parasite-Host Network for Video Crowd Counting
Shiqiao Meng, Jiajie Li, Weiwei Guo, Jinfeng Jiang, Lai Ye

Auto-TLDR; PHNet: A Parasite-Host Network for Video Crowd Counting
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Siamese Fully Convolutional Tracker with Motion Correction
Mathew Francis, Prithwijit Guha

Auto-TLDR; A Siamese Ensemble for Visual Tracking with Appearance and Motion Components
Abstract Slides Poster Similar
Deep Photo Relighting by Integrating Both 2D and 3D Lighting Information
Takashi Machida, Satoru Nakanishi

Auto-TLDR; DPR: Deep Photorelighting for Image Detection/Classification and Data Augmentation
Abstract Slides Poster Similar
Motion and Region Aware Adversarial Learning for Fall Detection with Thermal Imaging
Vineet Mehta, Abhinav Dhall, Sujata Pal, Shehroz Khan

Auto-TLDR; Automatic Fall Detection with Adversarial Network using Thermal Imaging Camera
Abstract Slides Poster Similar
Towards Practical Compressed Video Action Recognition: A Temporal Enhanced Multi-Stream Network
Bing Li, Longteng Kong, Dongming Zhang, Xiuguo Bao, Di Huang, Yunhong Wang

Auto-TLDR; TEMSN: Temporal Enhanced Multi-Stream Network for Compressed Video Action Recognition
Abstract Slides Poster Similar
A Boundary-Aware Distillation Network for Compressed Video Semantic Segmentation

Auto-TLDR; A Boundary-Aware Distillation Network for Video Semantic Segmentation
Abstract Slides Poster Similar
Human Segmentation with Dynamic LiDAR Data
Tao Zhong, Wonjik Kim, Masayuki Tanaka, Masatoshi Okutomi

Auto-TLDR; Spatiotemporal Neural Network for Human Segmentation with Dynamic Point Clouds
Correlation-Based ConvNet for Small Object Detection in Videos
Brais Bosquet, Manuel Mucientes, Victor Brea

Auto-TLDR; STDnet-ST: An End-to-End Spatio-Temporal Convolutional Neural Network for Small Object Detection in Video
Abstract Slides Poster Similar