Boundaries of Single-Class Regions in the Input Space of Piece-Wise Linear Neural Networks

Auto-TLDR; Piece-wise Linear Neural Networks with Linear Constraints
Similar papers
Color, Edge, and Pixel-Wise Explanation of Predictions Based onInterpretable Neural Network Model

Auto-TLDR; Explainable Deep Neural Network with Edge Detecting Filters
Dimensionality Reduction for Data Visualization and Linear Classification, and the Trade-Off between Robustness and Classification Accuracy
Martin Becker, Jens Lippel, Thomas Zielke

Auto-TLDR; Robustness Assessment of Deep Autoencoder for Data Visualization using Scatter Plots
Abstract Slides Poster Similar
Towards Explaining Adversarial Examples Phenomenon in Artificial Neural Networks
Ramin Barati, Reza Safabakhsh, Mohammad Rahmati

Auto-TLDR; Convolutional Neural Networks and Adversarial Training from the Perspective of convergence
Abstract Slides Poster Similar
RNN Training along Locally Optimal Trajectories via Frank-Wolfe Algorithm
Yun Yue, Ming Li, Venkatesh Saligrama, Ziming Zhang

Auto-TLDR; Frank-Wolfe Algorithm for Efficient Training of RNNs
Abstract Slides Poster Similar
Verifying the Causes of Adversarial Examples
Honglin Li, Yifei Fan, Frieder Ganz, Tony Yezzi, Payam Barnaghi

Auto-TLDR; Exploring the Causes of Adversarial Examples in Neural Networks
Abstract Slides Poster Similar
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Renlong Jie, Junbin Gao, Andrey Vasnev, Minh-Ngoc Tran

Auto-TLDR; Flexible Activation in Deep Neural Networks using ReLU and ELUs
Abstract Slides Poster Similar
Compression Strategies and Space-Conscious Representations for Deep Neural Networks
Giosuè Marinò, Gregorio Ghidoli, Marco Frasca, Dario Malchiodi

Auto-TLDR; Compression of Large Convolutional Neural Networks by Weight Pruning and Quantization
Abstract Slides Poster Similar
Multi-Layered Discriminative Restricted Boltzmann Machine with Untrained Probabilistic Layer

Auto-TLDR; MDRBM: A Probabilistic Four-layered Neural Network for Extreme Learning Machine
On the Global Self-attention Mechanism for Graph Convolutional Networks

Auto-TLDR; Global Self-Attention Mechanism for Graph Convolutional Networks
Partial Monotone Dependence
Denis Khryashchev, Huy Vo, Robert Haralick

Auto-TLDR; Partially Monotone Autoregressive Correlation for Time Series Forecasting
Learning Sparse Deep Neural Networks Using Efficient Structured Projections on Convex Constraints for Green AI
Michel Barlaud, Frederic Guyard

Auto-TLDR; Constrained Deep Neural Network with Constrained Splitting Projection
Abstract Slides Poster Similar
Exploiting Non-Linear Redundancy for Neural Model Compression
Muhammad Ahmed Shah, Raphael Olivier, Bhiksha Raj

Auto-TLDR; Compressing Deep Neural Networks with Linear Dependency
Abstract Slides Poster Similar
Hcore-Init: Neural Network Initialization Based on Graph Degeneracy
Stratis Limnios, George Dasoulas, Dimitrios Thilikos, Michalis Vazirgiannis

Auto-TLDR; K-hypercore: Graph Mining for Deep Neural Networks
Abstract Slides Poster Similar
Killing Four Birds with One Gaussian Process: The Relation between Different Test-Time Attacks
Kathrin Grosse, Michael Thomas Smith, Michael Backes

Auto-TLDR; Security of Gaussian Process Classifiers against Attack Algorithms
Abstract Slides Poster Similar
Energy Minimum Regularization in Continual Learning

Auto-TLDR; Energy Minimization Regularization for Continuous Learning
On Resource-Efficient Bayesian Network Classifiers and Deep Neural Networks
Wolfgang Roth, Günther Schindler, Holger Fröning, Franz Pernkopf

Auto-TLDR; Quantization-Aware Bayesian Network Classifiers for Small-Scale Scenarios
Abstract Slides Poster Similar
Generalized Conics: Properties and Applications
Aysylu Gabdulkhakova, Walter Kropatsch

Auto-TLDR; A Generalized Conic Representation for Distance Fields
Abstract Slides Poster Similar
Semantic Segmentation Refinement Using Entropy and Boundary-guided Monte Carlo Sampling and Directed Regional Search
Zitang Sun, Sei-Ichiro Kamata, Ruojing Wang, Weili Chen

Auto-TLDR; Directed Region Search and Refinement for Semantic Segmentation
Abstract Slides Poster Similar
Learning with Multiplicative Perturbations

Auto-TLDR; XAT and xVAT: A Multiplicative Adversarial Training Algorithm for Robust DNN Training
Abstract Slides Poster Similar
3D Pots Configuration System by Optimizing Over Geometric Constraints
Jae Eun Kim, Muhammad Zeeshan Arshad, Seong Jong Yoo, Je Hyeong Hong, Jinwook Kim, Young Min Kim

Auto-TLDR; Optimizing 3D Configurations for Stable Pottery Restoration from irregular and noisy evidence
Abstract Slides Poster Similar
Accuracy-Perturbation Curves for Evaluation of Adversarial Attack and Defence Methods

Auto-TLDR; Accuracy-perturbation Curve for Robustness Evaluation of Adversarial Examples
Abstract Slides Poster Similar
A Hybrid Metric Based on Persistent Homology and Its Application to Signal Classification
Austin Lawson, Yu-Min Chung, William Cruse

Auto-TLDR; Topological Data Analysis with Persistence Curves
Revisiting the Training of Very Deep Neural Networks without Skip Connections
Oyebade Kayode Oyedotun, Abd El Rahman Shabayek, Djamila Aouada, Bjorn Ottersten

Auto-TLDR; Optimization of Very Deep PlainNets without shortcut connections with 'vanishing and exploding units' activations'
Abstract Slides Poster Similar
Stochastic Runge-Kutta Methods and Adaptive SGD-G2 Stochastic Gradient Descent

Auto-TLDR; Adaptive Stochastic Runge Kutta for the Minimization of the Loss Function
Abstract Slides Poster Similar
F-Mixup: Attack CNNs from Fourier Perspective
Xiu-Chuan Li, Xu-Yao Zhang, Fei Yin, Cheng-Lin Liu

Auto-TLDR; F-Mixup: A novel black-box attack in frequency domain for deep neural networks
Abstract Slides Poster Similar
Beyond Cross-Entropy: Learning Highly Separable Feature Distributions for Robust and Accurate Classification
Arslan Ali, Andrea Migliorati, Tiziano Bianchi, Enrico Magli

Auto-TLDR; Gaussian class-conditional simplex loss for adversarial robust multiclass classifiers
Abstract Slides Poster Similar
Nearest Neighbor Classification Based on Activation Space of Convolutional Neural Network
Xinbo Ju, Shuo Shao, Huan Long, Weizhe Wang

Auto-TLDR; Convolutional Neural Network with Convex Hull Based Classifier
Locality-Promoting Representation Learning
Auto-TLDR; Locality-promoting Regularization for Neural Networks
Abstract Slides Poster Similar
How to Define a Rejection Class Based on Model Learning?
Sarah Laroui, Xavier Descombes, Aurelia Vernay, Florent Villiers, Francois Villalba, Eric Debreuve

Auto-TLDR; An innovative learning strategy for supervised classification that is able, by design, to reject a sample as not belonging to any of the known classes
Abstract Slides Poster Similar
An Efficient Empirical Solver for Localized Multiple Kernel Learning Via DNNs

Auto-TLDR; Localized Multiple Kernel Learning using LMKL-Net
Abstract Slides Poster Similar
Fractional Adaptation of Activation Functions in Neural Networks
Julio Zamora Esquivel, Jesus Adan Cruz Vargas, Paulo Lopez-Meyer, Hector Alfonso Cordourier Maruri, Jose Rodrigo Camacho Perez, Omesh Tickoo

Auto-TLDR; Automatic Selection of Activation Functions in Neural Networks using Fractional Calculus
Abstract Slides Poster Similar
Optimal Transport As a Defense against Adversarial Attacks
Quentin Bouniot, Romaric Audigier, Angélique Loesch

Auto-TLDR; Sinkhorn Adversarial Training with Optimal Transport Theory
Abstract Slides Poster Similar
Classification and Feature Selection Using a Primal-Dual Method and Projections on Structured Constraints
Michel Barlaud, Antonin Chambolle, Jean_Baptiste Caillau

Auto-TLDR; A Constrained Primal-dual Method for Structured Feature Selection on High Dimensional Data
Abstract Slides Poster Similar
An Invariance-Guided Stability Criterion for Time Series Clustering Validation
Florent Forest, Alex Mourer, Mustapha Lebbah, Hanane Azzag, Jérôme Lacaille

Auto-TLDR; An invariance-guided method for clustering model selection in time series data
Abstract Slides Poster Similar
A New Convex Loss Function for Multiple Instance Support Vector Machines

Auto-TLDR; WR-SVM: A Novel Multiple Instance SVM for Video Classification
Abstract Slides Poster Similar
A Multilinear Sampling Algorithm to Estimate Shapley Values

Auto-TLDR; A sampling method for Shapley values for multilayer Perceptrons
Abstract Slides Poster Similar
GAN-Based Gaussian Mixture Model Responsibility Learning
Wanming Huang, Yi Da Xu, Shuai Jiang, Xuan Liang, Ian Oppermann

Auto-TLDR; Posterior Consistency Module for Gaussian Mixture Model
Abstract Slides Poster Similar
Uniform and Non-Uniform Sampling Methods for Sub-Linear Time K-Means Clustering

Auto-TLDR; Sub-linear Time Clustering with Constant Approximation Ratio for K-Means Problem
Abstract Slides Poster Similar
Region and Relations Based Multi Attention Network for Graph Classification
Manasvi Aggarwal, M. Narasimha Murty

Auto-TLDR; R2POOL: A Graph Pooling Layer for Non-euclidean Structures
Abstract Slides Poster Similar
Low-Cost Lipschitz-Independent Adaptive Importance Sampling of Stochastic Gradients
Huikang Liu, Xiaolu Wang, Jiajin Li, Man-Cho Anthony So

Auto-TLDR; Adaptive Importance Sampling for Stochastic Gradient Descent
Learning Stable Deep Predictive Coding Networks with Weight Norm Supervision

Auto-TLDR; Stability of Predictive Coding Network with Weight Norm Supervision
Abstract Slides Poster Similar
Understanding Integrated Gradients with SmoothTaylor for Deep Neural Network Attribution
Gary Shing Wee Goh, Sebastian Lapuschkin, Leander Weber, Wojciech Samek, Alexander Binder

Auto-TLDR; SmoothGrad: bridging Integrated Gradients and SmoothGrad from the Taylor's theorem perspective
Graph Approximations to Geodesics on Metric Graphs
Robin Vandaele, Yvan Saeys, Tijl De Bie

Auto-TLDR; Topological Pattern Recognition of Metric Graphs Using Proximity Graphs
Abstract Slides Poster Similar
Computing Stable Resultant-Based Minimal Solvers by Hiding a Variable
Snehal Bhayani, Zuzana Kukelova, Janne Heikkilä

Auto-TLDR; Sparse Permian-Based Method for Solving Minimal Systems of Polynomial Equations
Learning Sign-Constrained Support Vector Machines
Kenya Tajima, Kouhei Tsuchida, Esmeraldo Ronnie Rey Zara, Naoya Ohta, Tsuyoshi Kato

Auto-TLDR; Constrained Sign Constraints for Learning Linear Support Vector Machine
Interpretable Structured Learning with Sparse Gated Sequence Encoder for Protein-Protein Interaction Prediction
Kishan K C, Feng Cui, Anne Haake, Rui Li

Auto-TLDR; Predicting Protein-Protein Interactions Using Sequence Representations
Abstract Slides Poster Similar
From Early Biological Models to CNNs: Do They Look Where Humans Look?
Marinella Iole Cadoni, Andrea Lagorio, Enrico Grosso, Jia Huei Tan, Chee Seng Chan

Auto-TLDR; Comparing Neural Networks to Human Fixations for Semantic Learning
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
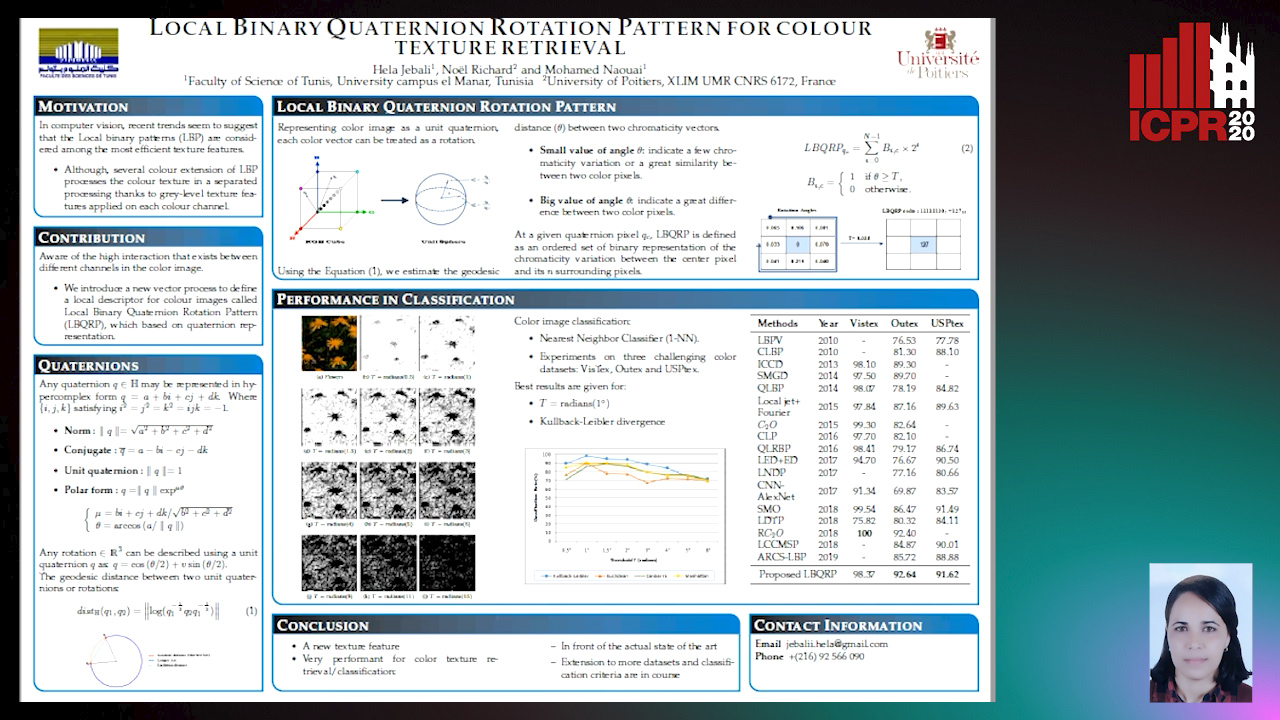
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification